 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Jul 21, 2022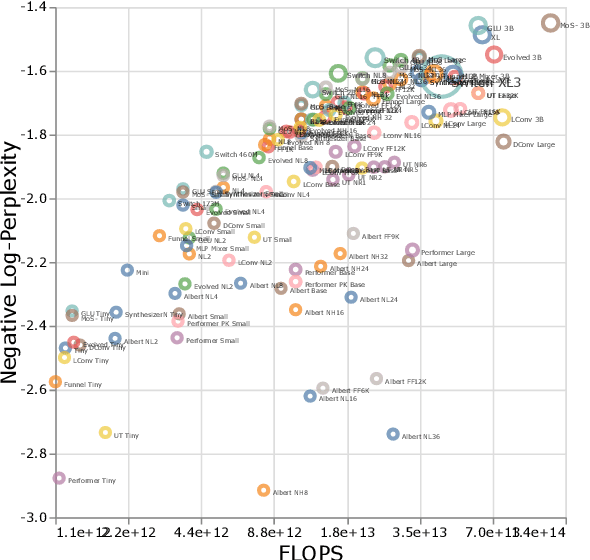
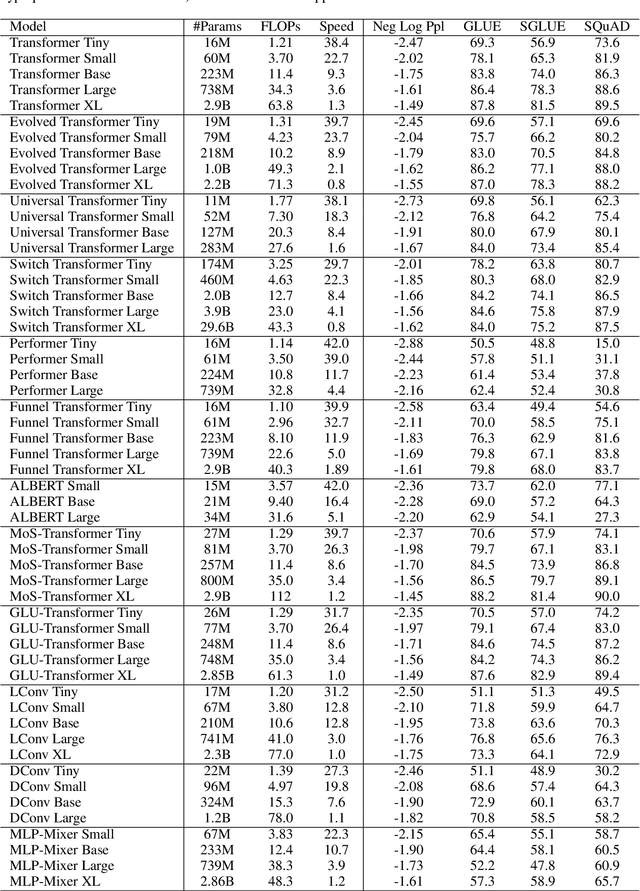
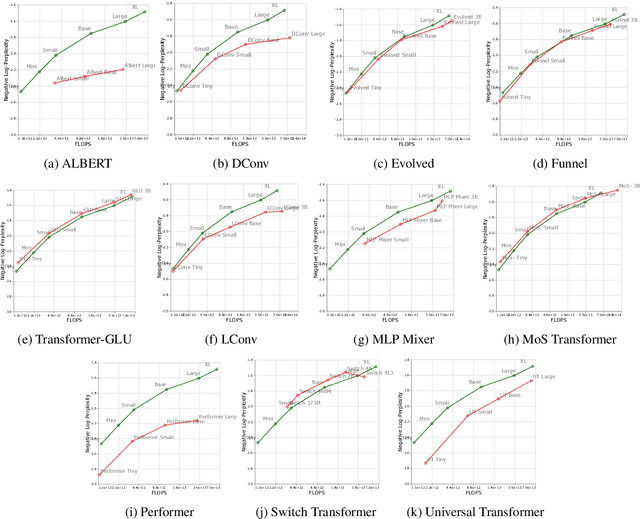
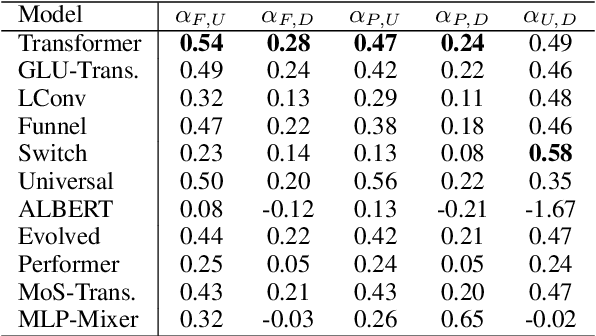
There have been a lot of interest in the scaling properties of Transformer models. However, not much has been done on the front of investigating the effect of scaling properties of different inductive biases and model architectures. Do model architectures scale differently? If so, how does inductive bias affect scaling behaviour? How does this influence upstream (pretraining) and downstream (transfer)? This paper conducts a systematic study of scaling behaviour of ten diverse model architectures such as Transformers, Switch Transformers, Universal Transformers, Dynamic convolutions, Performers, and recently proposed MLP-Mixers. Via extensive experiments, we show that (1) architecture is an indeed an important consideration when performing scaling and (2) the best performing model can fluctuate at different scales. We believe that the findings outlined in this work has significant implications to how model architectures are currently evaluated in the community.
Confident Adaptive Language Modeling
Jul 14, 2022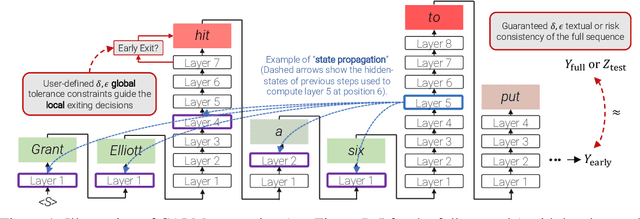
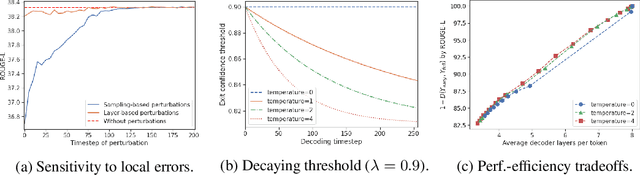
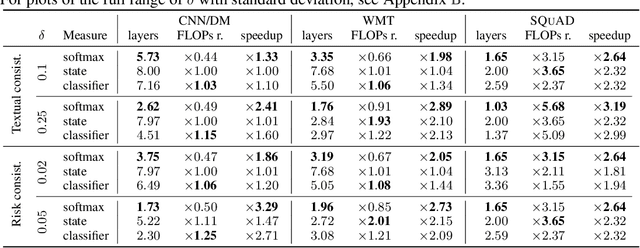
Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, potentially leading to slow and costly use at inference time. In practice, however, the series of generations made by LLMs is composed of varying levels of difficulty. While certain predictions truly benefit from the models' full capacity, other continuations are more trivial and can be solved with reduced compute. In this work, we introduce Confident Adaptive Language Modeling (CALM), a framework for dynamically allocating different amounts of compute per input and generation timestep. Early exit decoding involves several challenges that we address here, such as: (1) what confidence measure to use; (2) connecting sequence-level constraints to local per-token exit decisions; and (3) attending back to missing hidden representations due to early exits in previous tokens. Through theoretical analysis and empirical experiments on three diverse text generation tasks, we demonstrate the efficacy of our framework in reducing compute -- potential speedup of up to $\times 3$ -- while provably maintaining high performance.
Unifying Language Learning Paradigms
May 10, 2022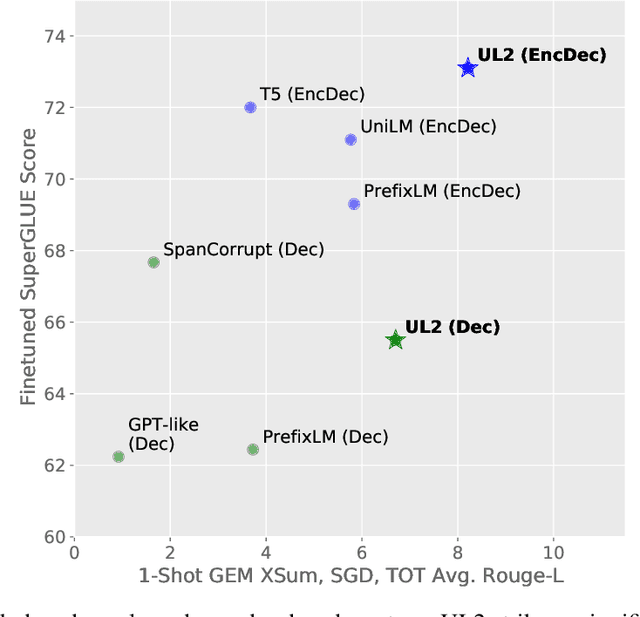

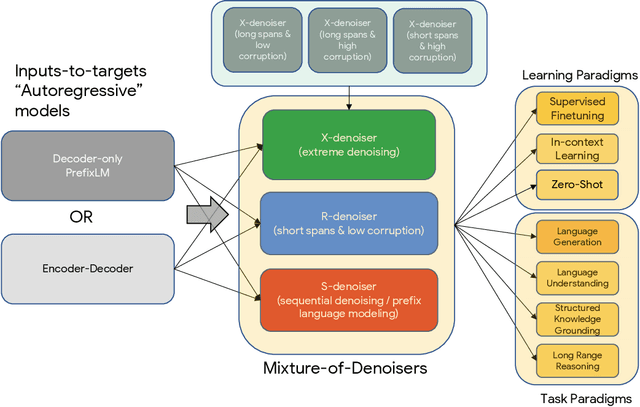
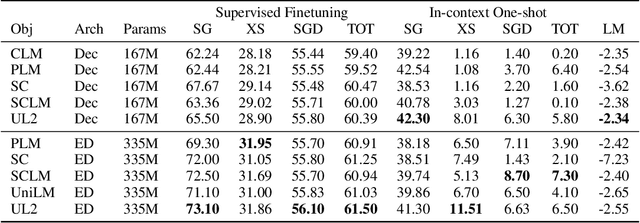
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization. We release Flax-based T5X model checkpoints for the 20B model at \url{https://github.com/google-research/google-research/tree/master/ul2}.
A New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Feb 22, 2022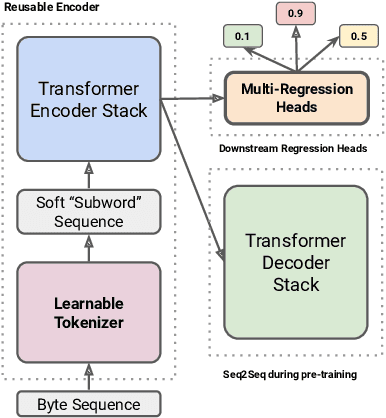
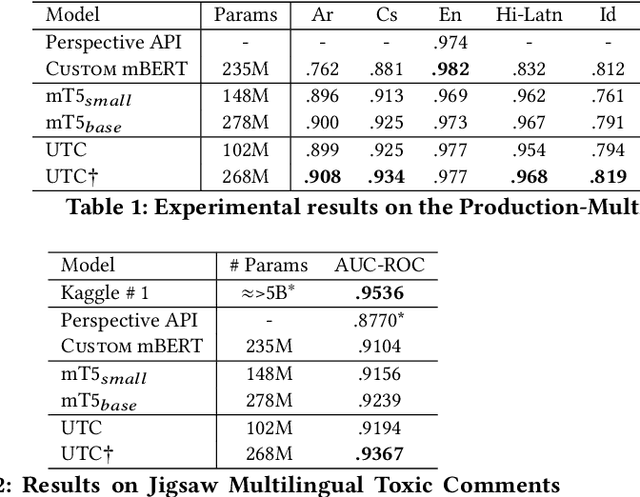
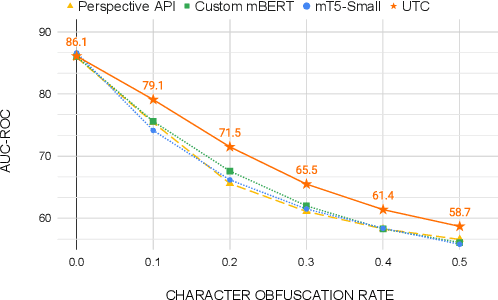
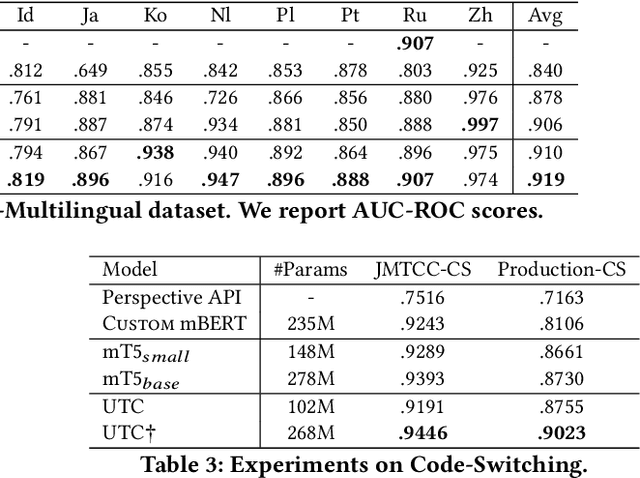
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.
Transformer Memory as a Differentiable Search Index
Feb 16, 2022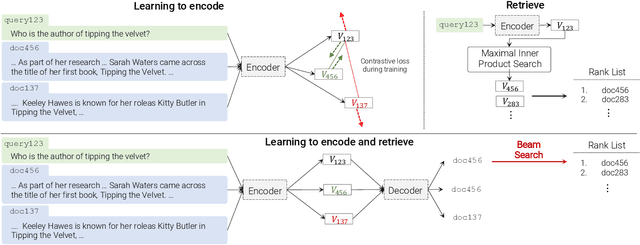
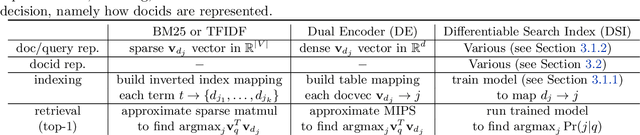
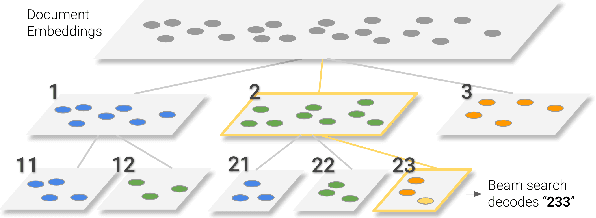
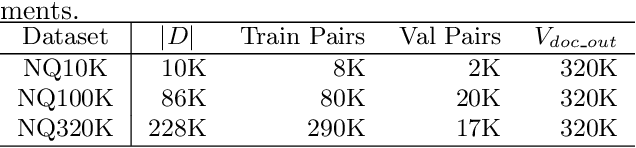
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021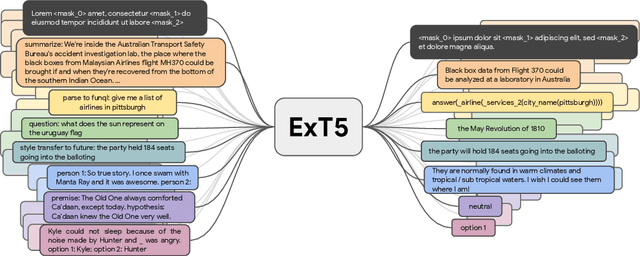
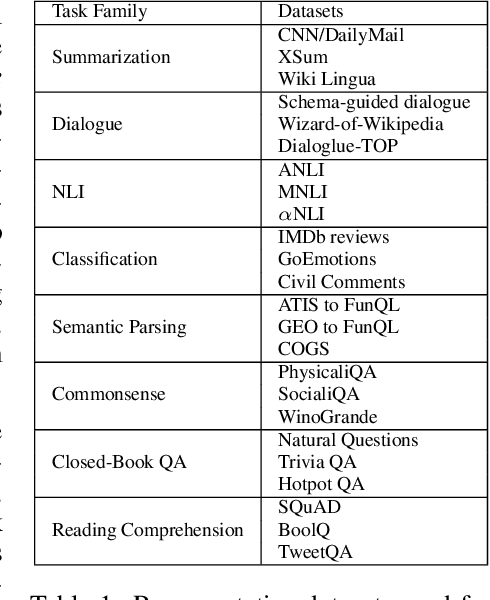
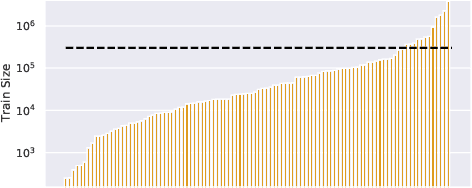
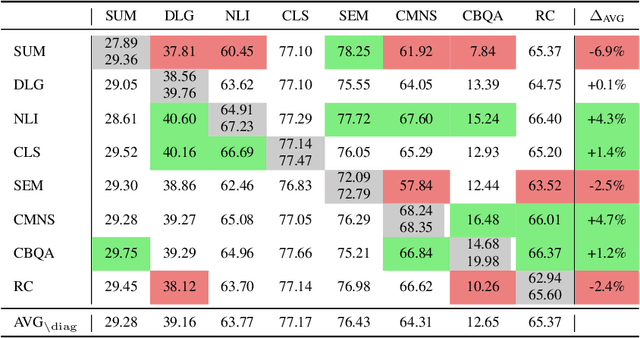
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
Charformer: Fast Character Transformers via Gradient-based Subword Tokenization
Jul 02, 2021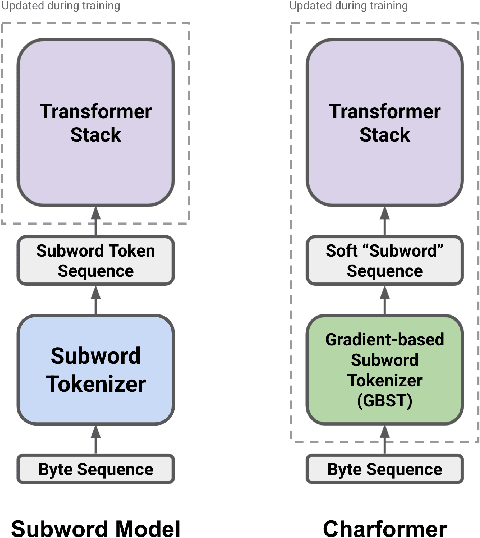
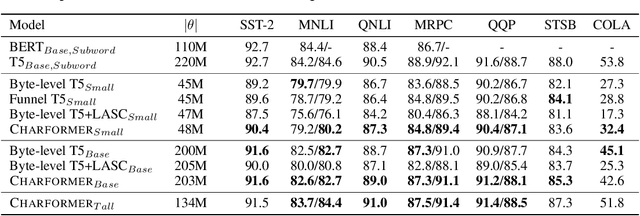

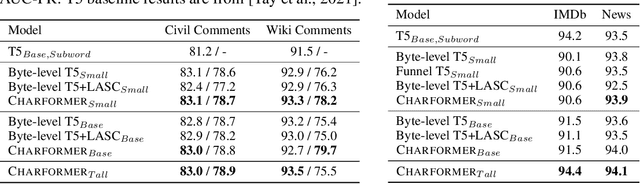
State-of-the-art models in natural language processing rely on separate rigid subword tokenization algorithms, which limit their generalization ability and adaptation to new settings. In this paper, we propose a new model inductive bias that learns a subword tokenization end-to-end as part of the model. To this end, we introduce a soft gradient-based subword tokenization module (GBST) that automatically learns latent subword representations from characters in a data-driven fashion. Concretely, GBST enumerates candidate subword blocks and learns to score them in a position-wise fashion using a block scoring network. We additionally introduce Charformer, a deep Transformer model that integrates GBST and operates on the byte level. Via extensive experiments on English GLUE, multilingual, and noisy text datasets, we show that Charformer outperforms a series of competitive byte-level baselines while generally performing on par and sometimes outperforming subword-based models. Additionally, Charformer is fast, improving the speed of both vanilla byte-level and subword-level Transformers by 28%-100% while maintaining competitive quality. We believe this work paves the way for highly performant token-free models that are trained completely end-to-end.
AgreeSum: Agreement-Oriented Multi-Document Summarization
Jun 04, 2021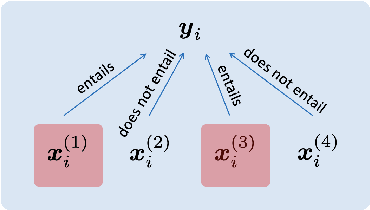

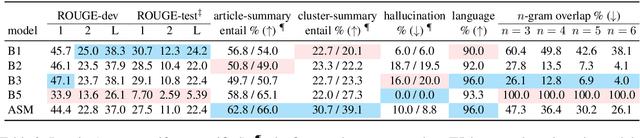
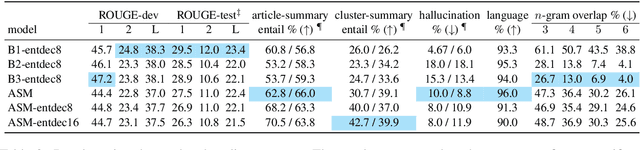
We aim to renew interest in a particular multi-document summarization (MDS) task which we call AgreeSum: agreement-oriented multi-document summarization. Given a cluster of articles, the goal is to provide abstractive summaries that represent information common and faithful to all input articles. Given the lack of existing datasets, we create a dataset for AgreeSum, and provide annotations on article-summary entailment relations for a subset of the clusters in the dataset. We aim to create strong baselines for the task by applying the top-performing pretrained single-document summarization model PEGASUS onto AgreeSum, leveraging both annotated clusters by supervised losses, and unannotated clusters by T5-based entailment-related and language-related losses. Compared to other baselines, both automatic evaluation and human evaluation show better article-summary and cluster-summary entailment in generated summaries. On a separate note, we hope that our article-summary entailment annotations contribute to the community's effort in improving abstractive summarization faithfulness.
Quiz-Style Question Generation for News Stories
Feb 18, 2021
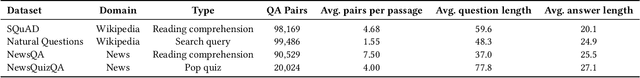
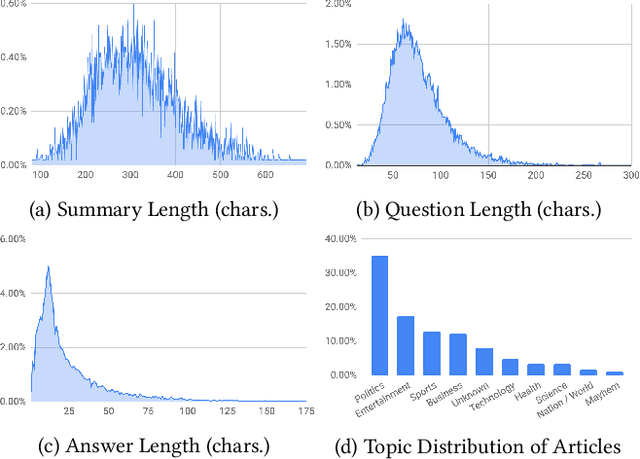
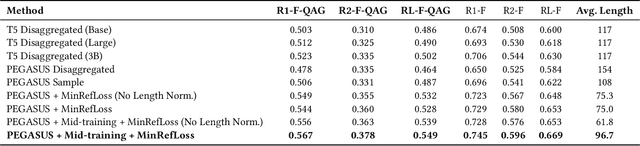
A large majority of American adults get at least some of their news from the Internet. Even though many online news products have the goal of informing their users about the news, they lack scalable and reliable tools for measuring how well they are achieving this goal, and therefore have to resort to noisy proxy metrics (e.g., click-through rates or reading time) to track their performance. As a first step towards measuring news informedness at a scale, we study the problem of quiz-style multiple-choice question generation, which may be used to survey users about their knowledge of recent news. In particular, we formulate the problem as two sequence-to-sequence tasks: question-answer generation (QAG) and distractor, or incorrect answer, generation (DG). We introduce NewsQuizQA, the first dataset intended for quiz-style question-answer generation, containing 20K human written question-answer pairs from 5K news article summaries. Using this dataset, we propose a series of novel techniques for applying large pre-trained Transformer encoder-decoder models, namely PEGASUS and T5, to the tasks of question-answer generation and distractor generation. We show that our models outperform strong baselines using both automated metrics and human raters. We provide a case study of running weekly quizzes on real-world users via the Google Surveys platform over the course of two months. We found that users generally found the automatically generated questions to be educational and enjoyable. Finally, to serve the research community, we are releasing the NewsQuizQA dataset.