 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer Pruning Framework for Compressing Single Shot MultiBox Detector
Nov 20, 2018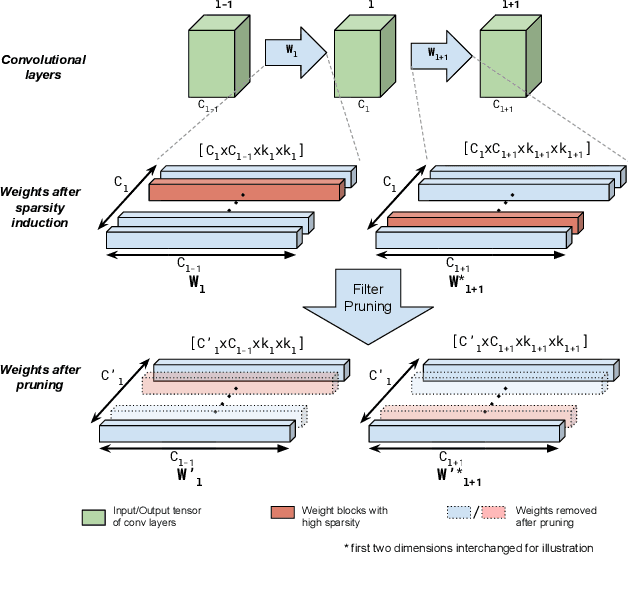
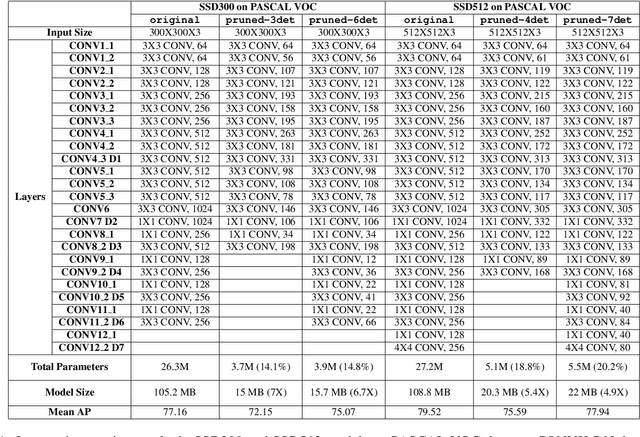
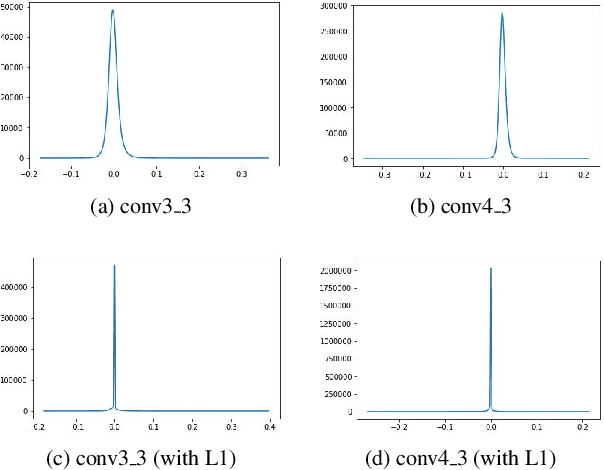

We propose a framework for compressing state-of-the-art Single Shot MultiBox Detector (SSD). The framework addresses compression in the following stages: Sparsity Induction, Filter Selection, and Filter Pruning. In the Sparsity Induction stage, the object detector model is sparsified via an improved global threshold. In Filter Selection & Pruning stage, we select and remove filters using sparsity statistics of filter weights in two consecutive convolutional layers. This results in the model with the size smaller than most existing compact architectures. We evaluate the performance of our framework with multiple datasets and compare over multiple methods. Experimental results show that our method achieves state-of-the-art compression of 6.7X and 4.9X on PASCAL VOC dataset on models SSD300 and SSD512 respectively. We further show that the method produces maximum compression of 26X with SSD512 on German Traffic Sign Detection Benchmark (GTSDB). Additionally, we also empirically show our method's adaptability for classification based architecture VGG16 on datasets CIFAR and German Traffic Sign Recognition Benchmark (GTSRB) achieving a compression rate of 125X and 200X with the reduction in flops by 90.50% and 96.6% respectively with no loss of accuracy. In addition to this, our method does not require any special libraries or hardware support for the resulting compressed models.
Stability Based Filter Pruning for Accelerating Deep CNNs
Nov 20, 2018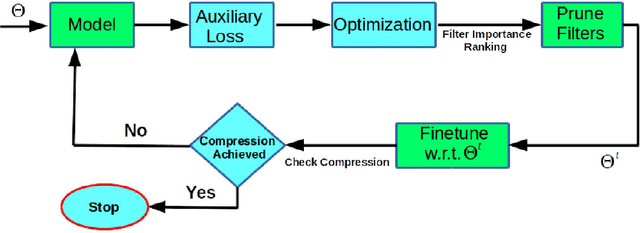
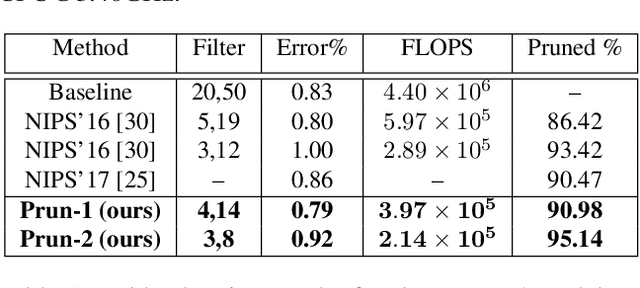
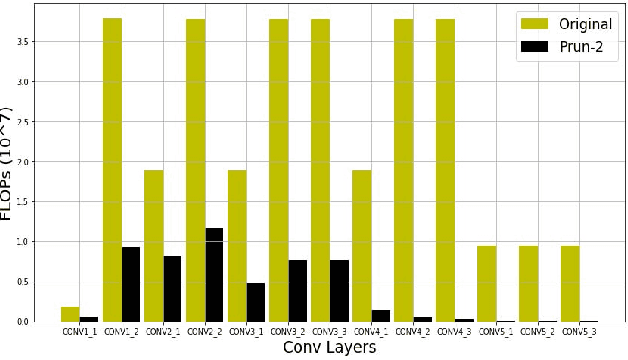
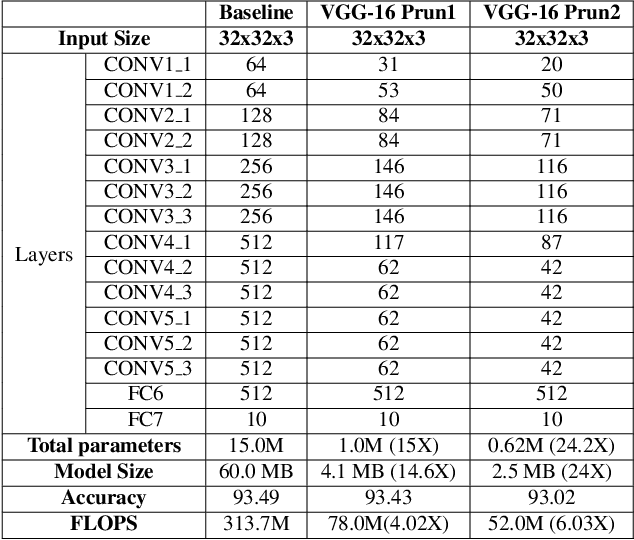
Convolutional neural networks (CNN) have achieved impressive performance on the wide variety of tasks (classification, detection, etc.) across multiple domains at the cost of high computational and memory requirements. Thus, leveraging CNNs for real-time applications necessitates model compression approaches that not only reduce the total number of parameters but reduce the overall computation as well. In this work, we present a stability-based approach for filter-level pruning of CNNs. We evaluate our proposed approach on different architectures (LeNet, VGG-16, ResNet, and Faster RCNN) and datasets and demonstrate its generalizability through extensive experiments. Moreover, our compressed models can be used at run-time without requiring any special libraries or hardware. Our model compression method reduces the number of FLOPS by an impressive factor of 6.03X and GPU memory footprint by more than 17X, significantly outperforming other state-of-the-art filter pruning methods.
Multimodal Differential Network for Visual Question Generation
Aug 12, 2018
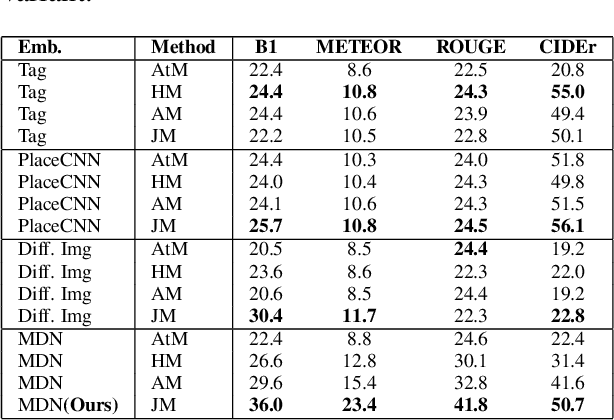
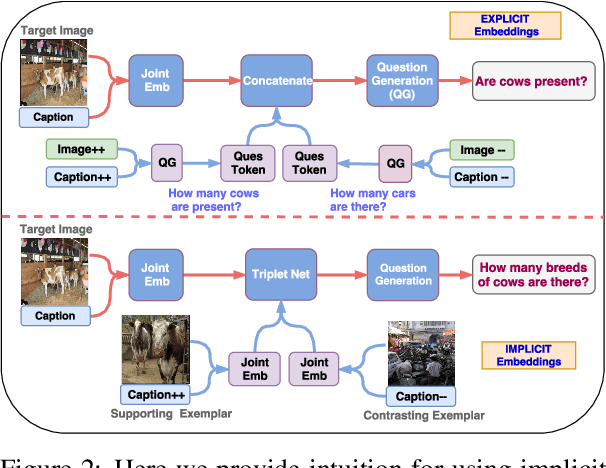
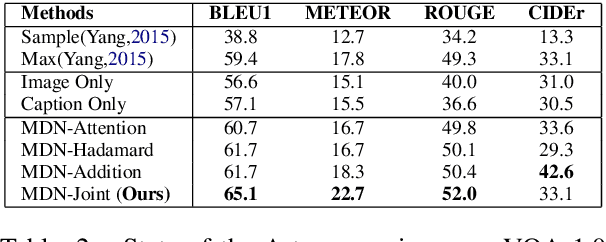
Generating natural questions from an image is a semantic task that requires using visual and language modality to learn multimodal representations. Images can have multiple visual and language contexts that are relevant for generating questions namely places, captions, and tags. In this paper, we propose the use of exemplars for obtaining the relevant context. We obtain this by using a Multimodal Differential Network to produce natural and engaging questions. The generated questions show a remarkable similarity to the natural questions as validated by a human study. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU, METEOR, ROUGE, and CIDEr).
Learning Semantic Sentence Embeddings using Pair-wise Discriminator
Jul 02, 2018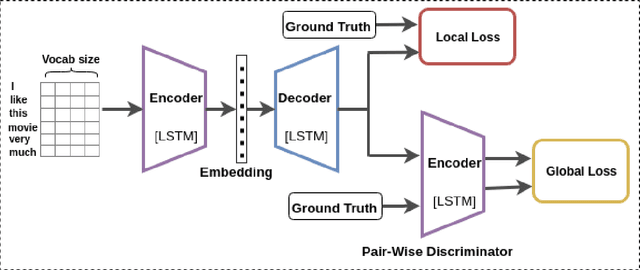
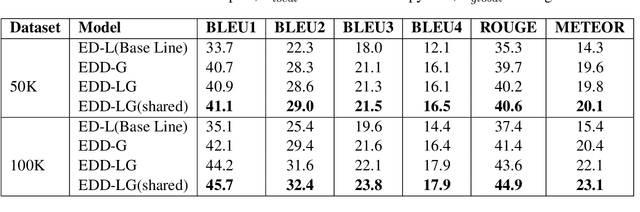
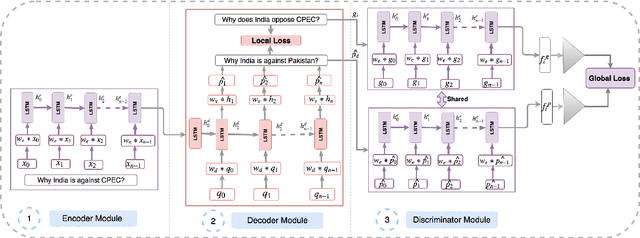
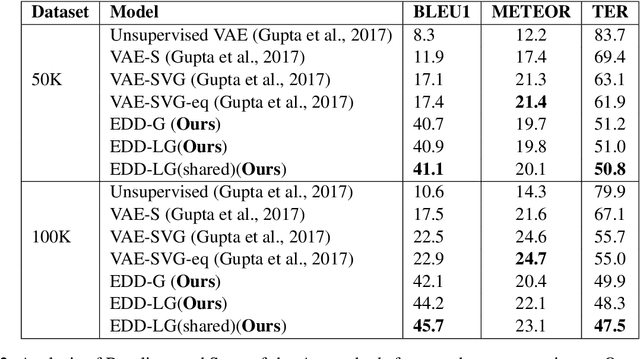
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
Differential Attention for Visual Question Answering
Apr 03, 2018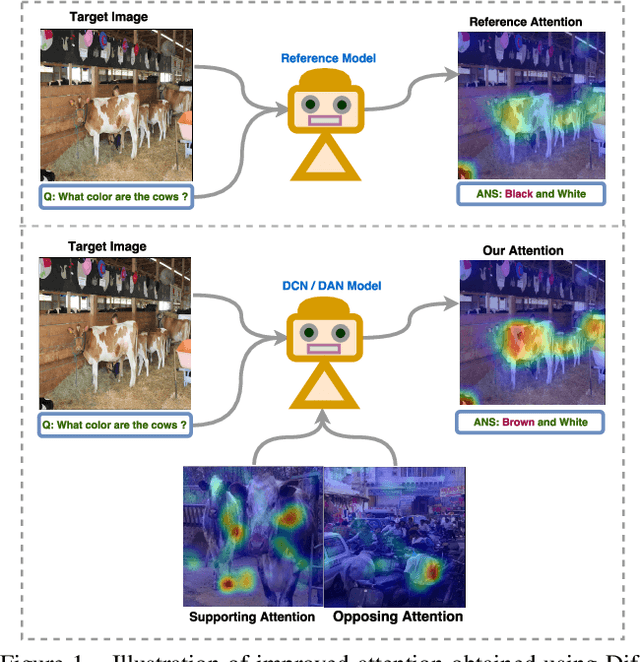
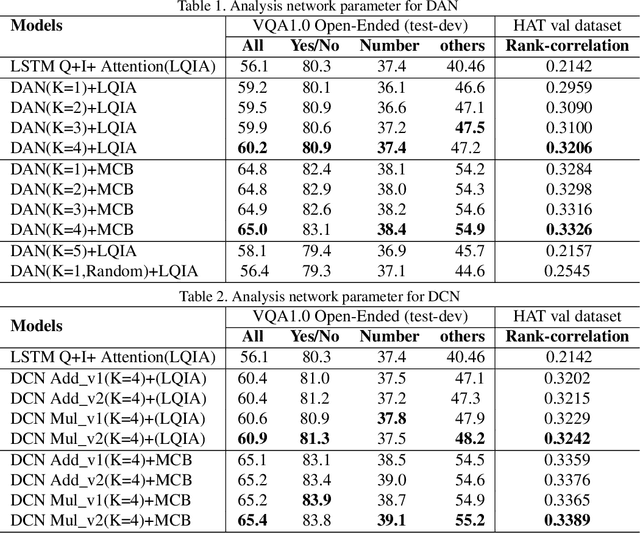
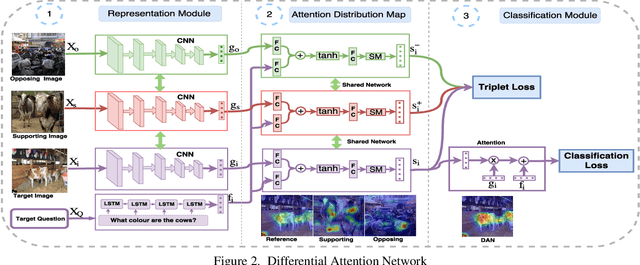
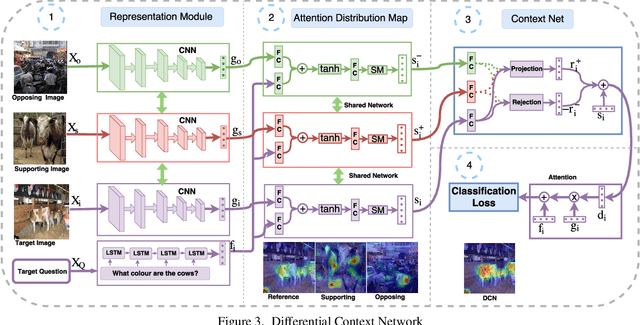
In this paper we aim to answer questions based on images when provided with a dataset of question-answer pairs for a number of images during training. A number of methods have focused on solving this problem by using image based attention. This is done by focusing on a specific part of the image while answering the question. Humans also do so when solving this problem. However, the regions that the previous systems focus on are not correlated with the regions that humans focus on. The accuracy is limited due to this drawback. In this paper, we propose to solve this problem by using an exemplar based method. We obtain one or more supporting and opposing exemplars to obtain a differential attention region. This differential attention is closer to human attention than other image based attention methods. It also helps in obtaining improved accuracy when answering questions. The method is evaluated on challenging benchmark datasets. We perform better than other image based attention methods and are competitive with other state of the art methods that focus on both image and questions.
No Modes left behind: Capturing the data distribution effectively using GANs
Feb 02, 2018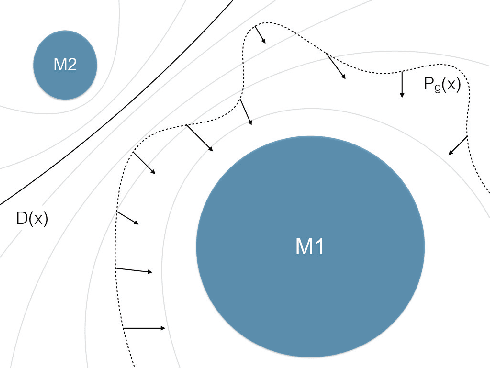
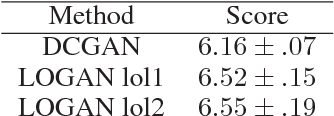
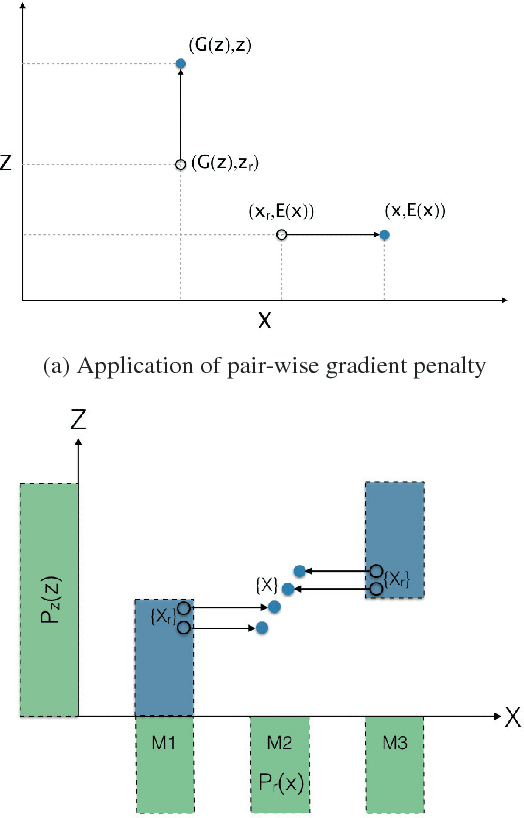
Generative adversarial networks (GANs) while being very versatile in realistic image synthesis, still are sensitive to the input distribution. Given a set of data that has an imbalance in the distribution, the networks are susceptible to missing modes and not capturing the data distribution. While various methods have been tried to improve training of GANs, these have not addressed the challenges of covering the full data distribution. Specifically, a generator is not penalized for missing a mode. We show that these are therefore still susceptible to not capturing the full data distribution. In this paper, we propose a simple approach that combines an encoder based objective with novel loss functions for generator and discriminator that improves the solution in terms of capturing missing modes. We validate that the proposed method results in substantial improvements through its detailed analysis on toy and real datasets. The quantitative and qualitative results demonstrate that the proposed method improves the solution for the problem of missing modes and improves training of GANs.
Compact Environment-Invariant Codes for Robust Visual Place Recognition
Sep 23, 2017
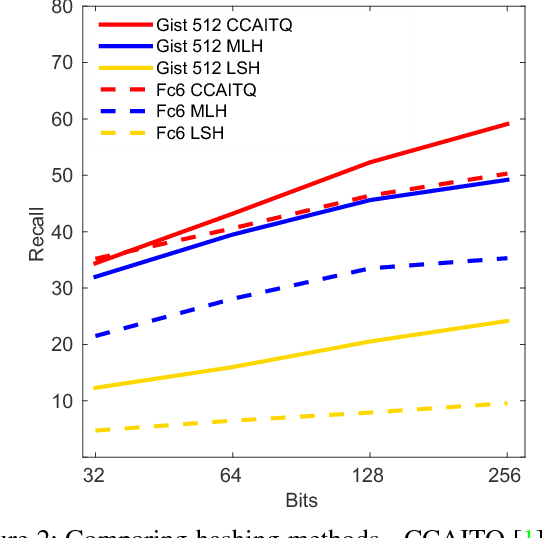
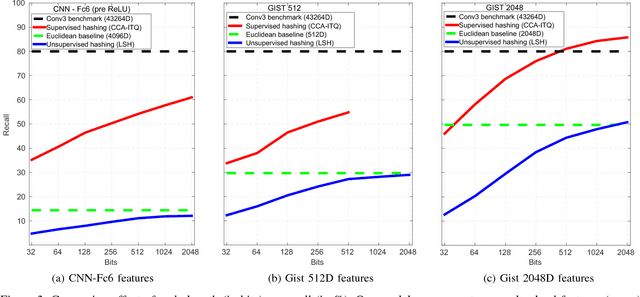
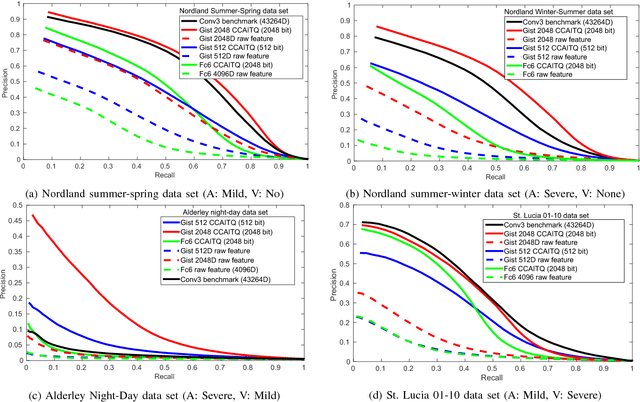
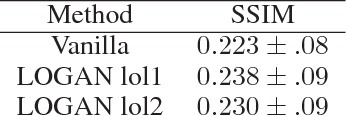
Robust visual place recognition (VPR) requires scene representations that are invariant to various environmental challenges such as seasonal changes and variations due to ambient lighting conditions during day and night. Moreover, a practical VPR system necessitates compact representations of environmental features. To satisfy these requirements, in this paper we suggest a modification to the existing pipeline of VPR systems to incorporate supervised hashing. The modified system learns (in a supervised setting) compact binary codes from image feature descriptors. These binary codes imbibe robustness to the visual variations exposed to it during the training phase, thereby, making the system adaptive to severe environmental changes. Also, incorporating supervised hashing makes VPR computationally more efficient and easy to implement on simple hardware. This is because binary embeddings can be learned over simple-to-compute features and the distance computation is also in the low-dimensional hamming space of binary codes. We have performed experiments on several challenging data sets covering seasonal, illumination and viewpoint variations. We also compare two widely used supervised hashing methods of CCAITQ and MLH and show that this new pipeline out-performs or closely matches the state-of-the-art deep learning VPR methods that are based on high-dimensional features extracted from pre-trained deep convolutional neural networks.
Learning to Estimate Pose by Watching Videos
Apr 13, 2017
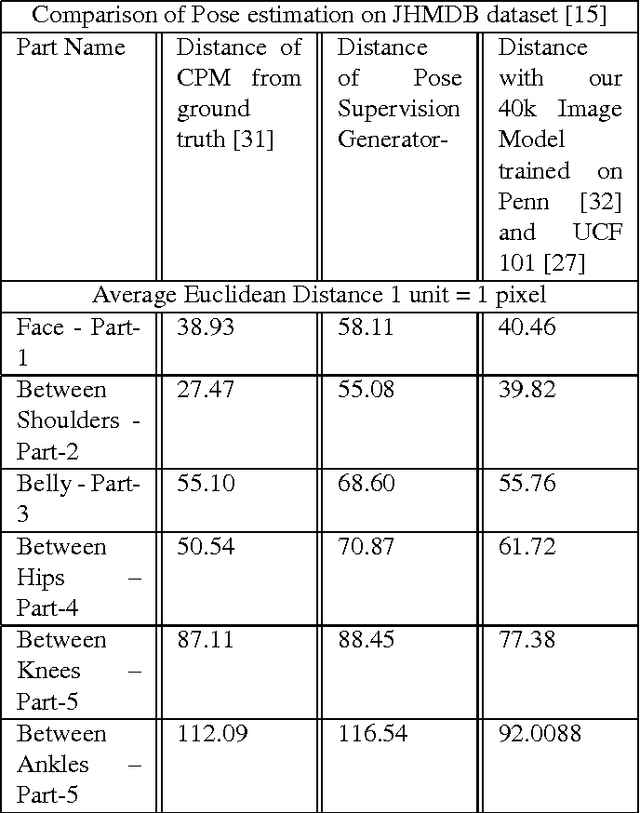
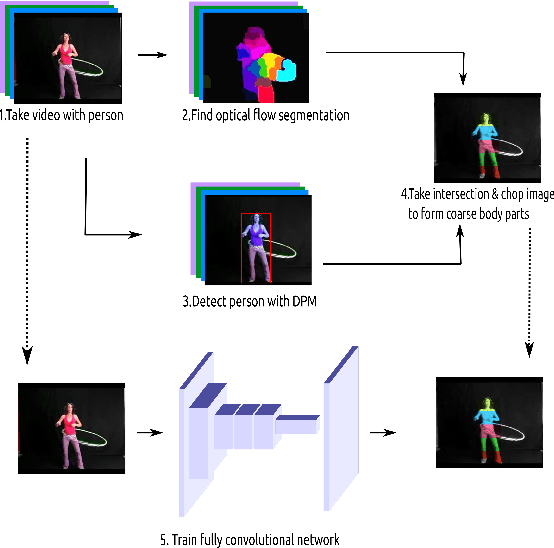
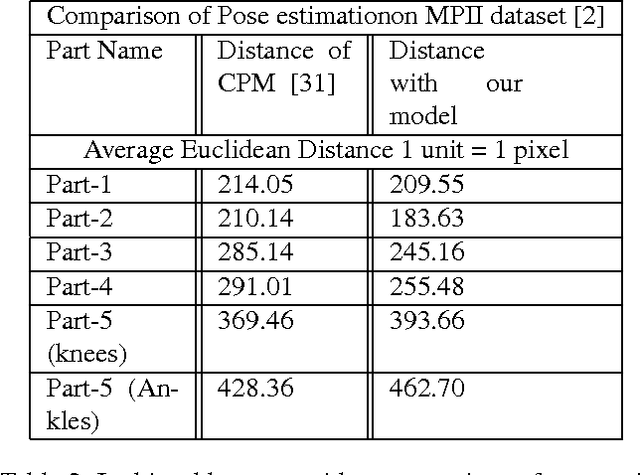
In this paper we propose a technique for obtaining coarse pose estimation of humans in an image that does not require any manual supervision. While a general unsupervised technique would fail to estimate human pose, we suggest that sufficient information about coarse pose can be obtained by observing human motion in multiple frames. Specifically, we consider obtaining surrogate supervision through videos as a means for obtaining motion based grouping cues. We supplement the method using a basic object detector that detects persons. With just these components we obtain a rough estimate of the human pose. With these samples for training, we train a fully convolutional neural network (FCNN)[20] to obtain accurate dense blob based pose estimation. We show that the results obtained are close to the ground-truth and to the results obtained using a fully supervised convolutional pose estimation method [31] as evaluated on a challenging dataset [15]. This is further validated by evaluating the obtained poses using a pose based action recognition method [5]. In this setting we outperform the results as obtained using the baseline method that uses a fully supervised pose estimation algorithm and is competitive with a new baseline created using convolutional pose estimation with full supervision.
Active learning with version spaces for object detection
Nov 29, 2016
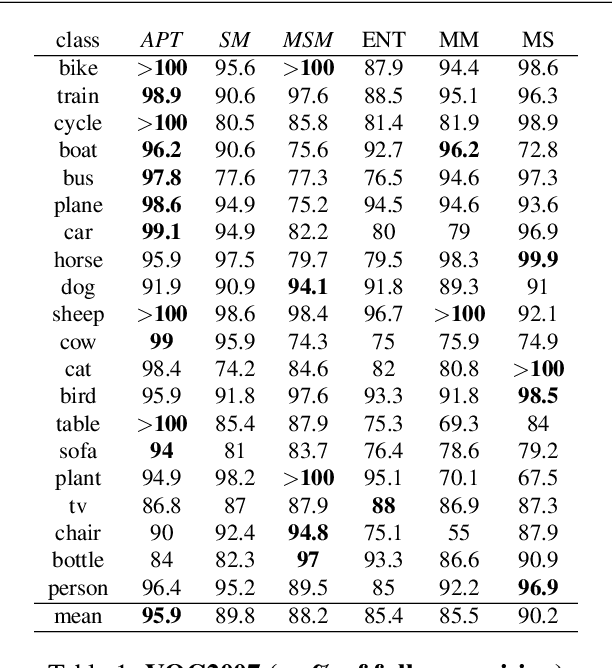

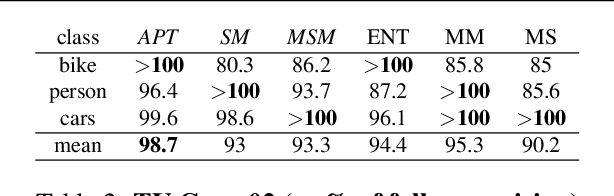
Given an image, we would like to learn to detect objects belonging to particular object categories. Common object detection methods train on large annotated datasets which are annotated in terms of bounding boxes that contain the object of interest. Previous works on object detection model the problem as a structured regression problem which ranks the correct bounding boxes more than the background ones. In this paper we develop algorithms which actively obtain annotations from human annotators for a small set of images, instead of all images, thereby reducing the annotation effort. Towards this goal, we make the following contributions: 1. We develop a principled version space based active learning method that solves for object detection as a structured prediction problem in a weakly supervised setting 2. We also propose two variants of the margin sampling strategy 3. We analyse the results on standard object detection benchmarks that show that with only 20% of the data we can obtain more than 95% of the localization accuracy of full supervision. Our methods outperform random sampling and the classical uncertainty-based active learning algorithms like entropy
Unsupervised Domain Adaptation in the Wild: Dealing with Asymmetric Label Sets
Mar 26, 2016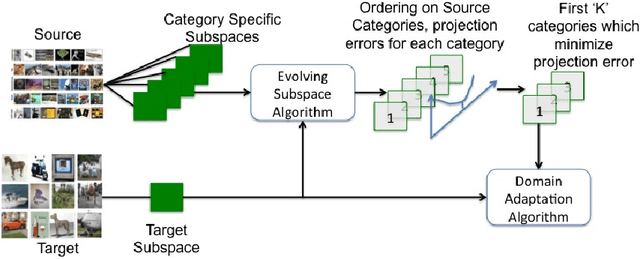
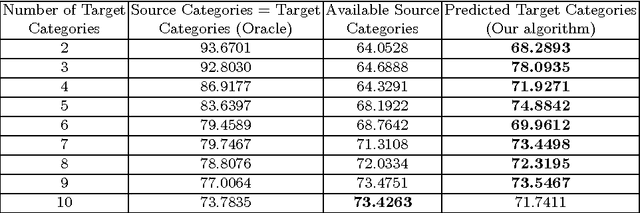
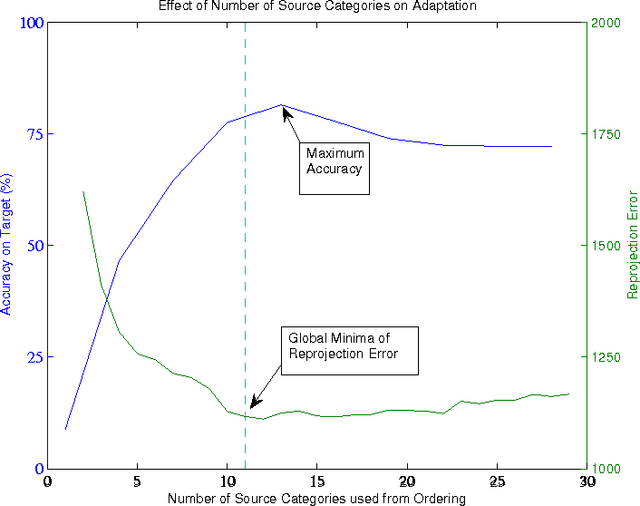

The goal of domain adaptation is to adapt models learned on a source domain to a particular target domain. Most methods for unsupervised domain adaptation proposed in the literature to date, assume that the set of classes present in the target domain is identical to the set of classes present in the source domain. This is a restrictive assumption that limits the practical applicability of unsupervised domain adaptation techniques in real world settings ("in the wild"). Therefore, we relax this constraint and propose a technique that allows the set of target classes to be a subset of the source classes. This way, large publicly available annotated datasets with a wide variety of classes can be used as source, even if the actual set of classes in target can be more limited and, maybe most importantly, unknown beforehand. To this end, we propose an algorithm that orders a set of source subspaces that are relevant to the target classification problem. Our method then chooses a restricted set from this ordered set of source subspaces. As an extension, even starting from multiple source datasets with varied sets of categories, this method automatically selects an appropriate subset of source categories relevant to a target dataset. Empirical analysis on a number of source and target domain datasets shows that restricting the source subspace to only a subset of categories does indeed substantially improve the eventual target classification accuracy over the baseline that considers all source classes.