 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolated Adversarial Training: Achieving Robust Neural Networks without Sacrificing Too Much Accuracy
Jun 29, 2019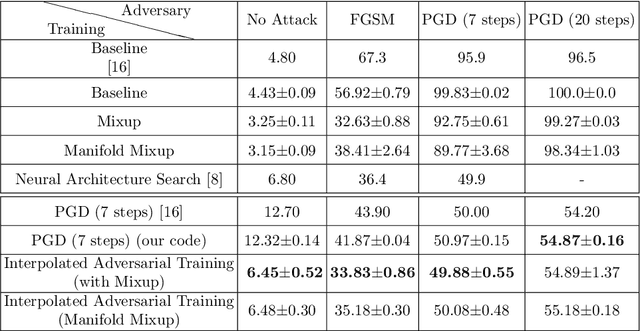
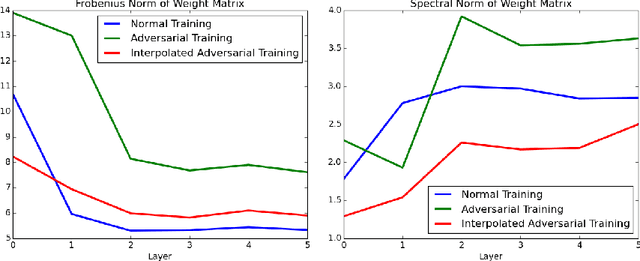
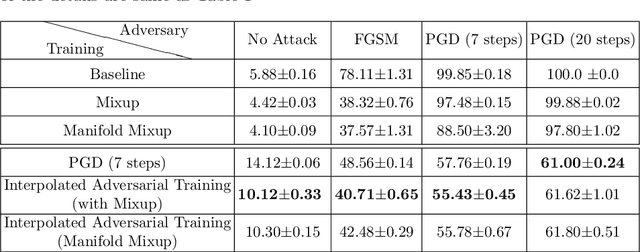
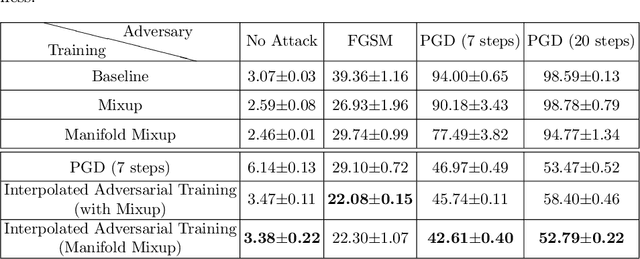
Adversarial robustness has become a central goal in deep learning, both in the theory and the practice. However, successful methods to improve the adversarial robustness (such as adversarial training) greatly hurt generalization performance on the unperturbed data. This could have a major impact on how the adversarial robustness affects real world systems (i.e. many may opt to forgo robustness if it can improve accuracy on the unperturbed data). We propose Interpolated Adversarial Training, which employs recently proposed interpolation based training methods in the framework of adversarial training. On CIFAR-10, adversarial training increases the standard test error ( when there is no adversary) from 4.43% to 12.32%, whereas with our Interpolated adversarial training we retain the adversarial robustness while achieving a standard test error of only 6.45%. With our technique, the relative increase in the standard error for the robust model is reduced from 178.1% to just 45.5%.
Adversarial Mixup Resynthesizers
Apr 04, 2019
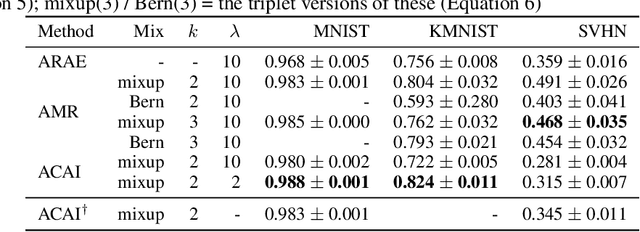
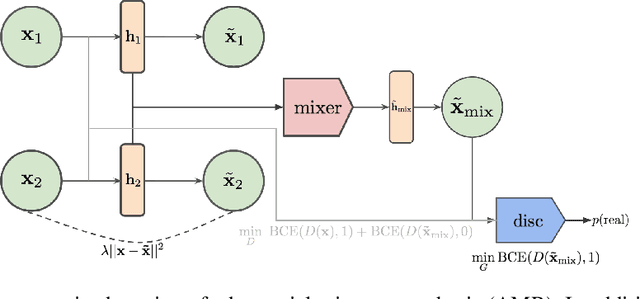
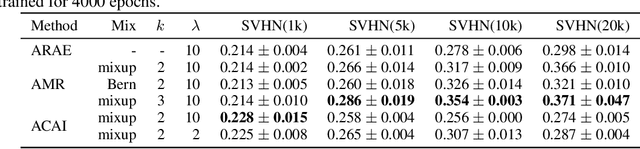
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.
Interpolation Consistency Training for Semi-Supervised Learning
Mar 09, 2019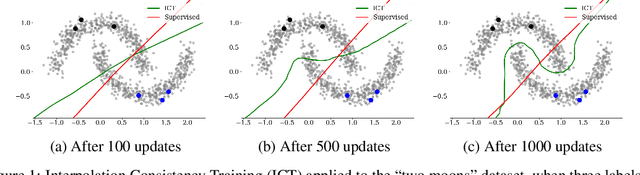
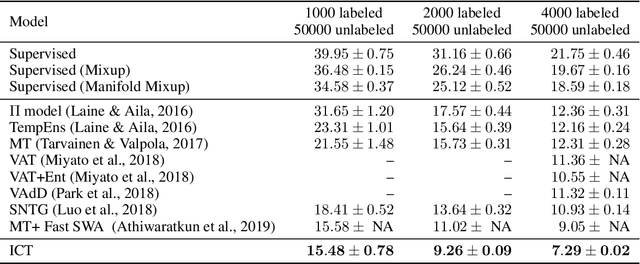
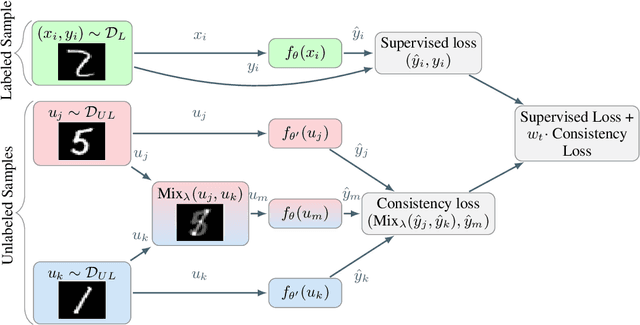
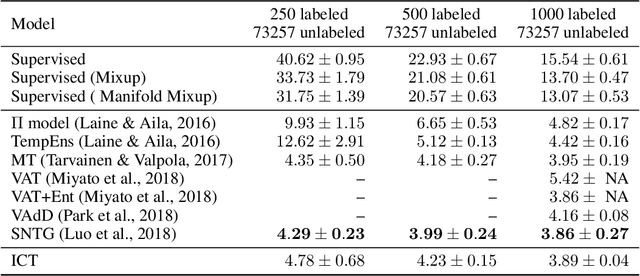
We introduce Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for training Deep Neural Networks in the semi-supervised learning paradigm. ICT encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points. In classification problems, ICT moves the decision boundary to low-density regions of the data distribution. Our experiments show that ICT achieves state-of-the-art performance when applied to standard neural network architectures on the CIFAR-10 and SVHN benchmark datasets.
Manifold Mixup: Learning Better Representations by Interpolating Hidden States
Oct 04, 2018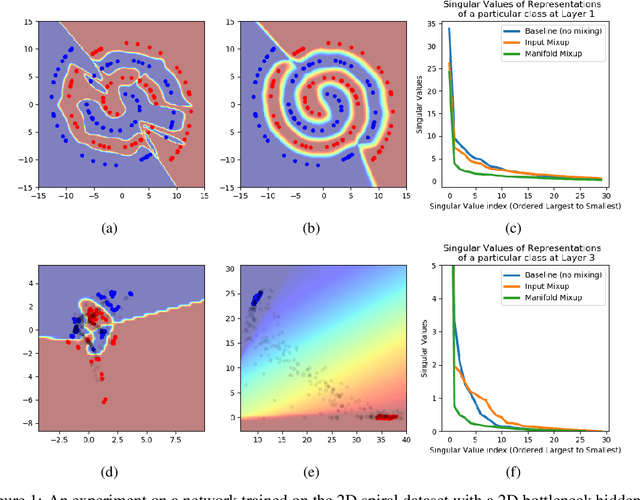
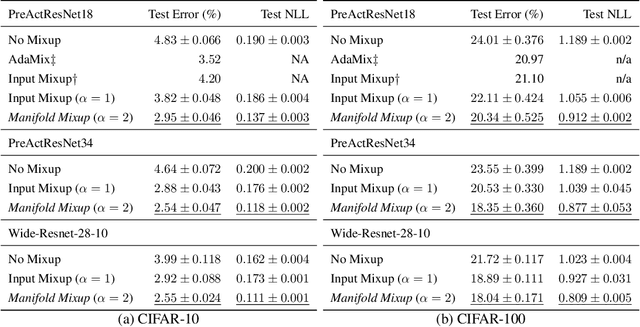
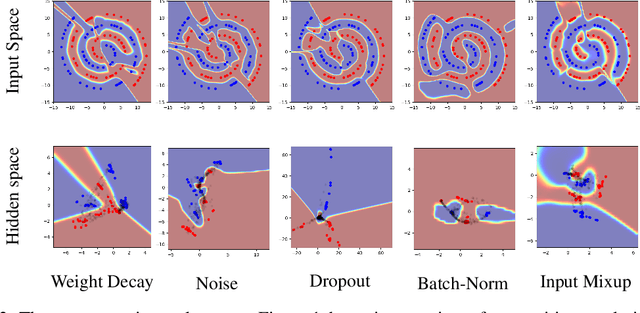
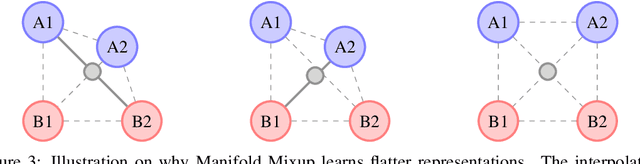
Deep networks often perform well on the data distribution on which they are trained, yet give incorrect (and often very confident) answers when evaluated on points from off of the training distribution. This is exemplified by the adversarial examples phenomenon but can also be seen in terms of model generalization and domain shift. Ideally, a model would assign lower confidence to points unlike those from the training distribution. We propose a regularizer which addresses this issue by training with interpolated hidden states and encouraging the classifier to be less confident at these points. Because the hidden states are learned, this has an important effect of encouraging the hidden states for a class to be concentrated in such a way so that interpolations within the same class or between two different classes do not intersect with the real data points from other classes. This has a major advantage in that it avoids the underfitting which can result from interpolating in the input space. We prove that the exact condition for this problem of underfitting to be avoided by Manifold Mixup is that the dimensionality of the hidden states exceeds the number of classes, which is often the case in practice. Additionally, this concentration can be seen as making the features in earlier layers more discriminative. We show that despite requiring no significant additional computation, Manifold Mixup achieves large improvements over strong baselines in supervised learning, robustness to single-step adversarial attacks, semi-supervised learning, and Negative Log-Likelihood on held out samples.
Towards Understanding Generalization via Analytical Learning Theory
Oct 01, 2018

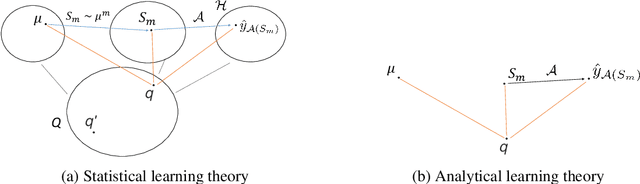
This paper introduces a novel measure-theoretic theory for machine learning that does not require statistical assumptions. Based on this theory, a new regularization method in deep learning is derived and shown to outperform previous methods in CIFAR-10, CIFAR-100, and SVHN. Moreover, the proposed theory provides a theoretical basis for a family of practically successful regularization methods in deep learning. We discuss several consequences of our results on one-shot learning, representation learning, deep learning, and curriculum learning. Unlike statistical learning theory, the proposed learning theory analyzes each problem instance individually via measure theory, rather than a set of problem instances via statistics. As a result, it provides different types of results and insights when compared to statistical learning theory.
Modularity Matters: Learning Invariant Relational Reasoning Tasks
Jun 18, 2018
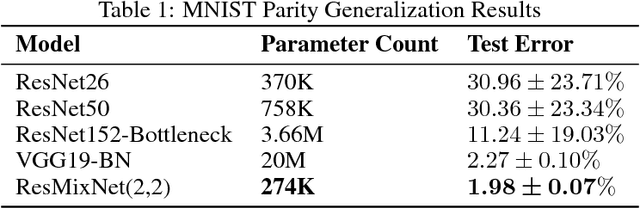

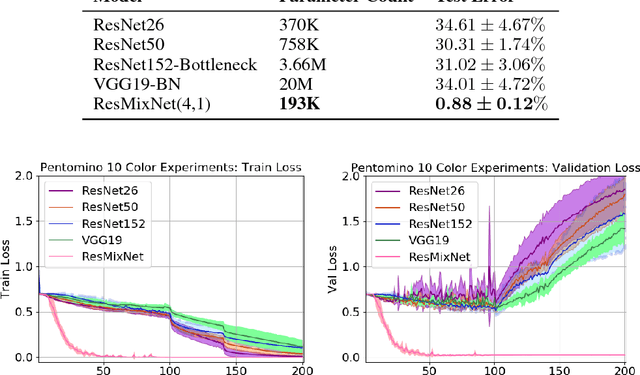
We focus on two supervised visual reasoning tasks whose labels encode a semantic relational rule between two or more objects in an image: the MNIST Parity task and the colorized Pentomino task. The objects in the images undergo random translation, scaling, rotation and coloring transformations. Thus these tasks involve invariant relational reasoning. We report uneven performance of various deep CNN models on these two tasks. For the MNIST Parity task, we report that the VGG19 model soundly outperforms a family of ResNet models. Moreover, the family of ResNet models exhibits a general sensitivity to random initialization for the MNIST Parity task. For the colorized Pentomino task, now both the VGG19 and ResNet models exhibit sluggish optimization and very poor test generalization, hovering around 30% test error. The CNN we tested all learn hierarchies of fully distributed features and thus encode the distributed representation prior. We are motivated by a hypothesis from cognitive neuroscience which posits that the human visual cortex is modularized, and this allows the visual cortex to learn higher order invariances. To this end, we consider a modularized variant of the ResNet model, referred to as a Residual Mixture Network (ResMixNet) which employs a mixture-of-experts architecture to interleave distributed representations with more specialized, modular representations. We show that very shallow ResMixNets are capable of learning each of the two tasks well, attaining less than 2% and 1% test error on the MNIST Parity and the colorized Pentomino tasks respectively. Most importantly, the ResMixNet models are extremely parameter efficient: generalizing better than various non-modular CNNs that have over 10x the number of parameters. These experimental results support the hypothesis that modularity is a robust prior for learning invariant relational reasoning.
Residual Connections Encourage Iterative Inference
Mar 08, 2018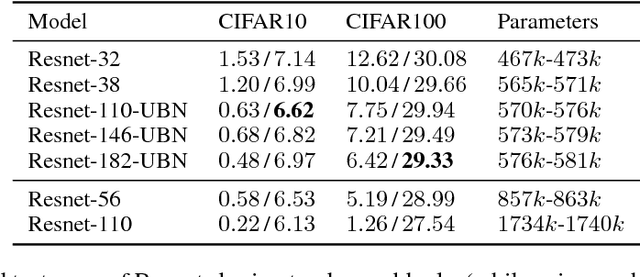



Residual networks (Resnets) have become a prominent architecture in deep learning. However, a comprehensive understanding of Resnets is still a topic of ongoing research. A recent view argues that Resnets perform iterative refinement of features. We attempt to further expose properties of this aspect. To this end, we study Resnets both analytically and empirically. We formalize the notion of iterative refinement in Resnets by showing that residual connections naturally encourage features of residual blocks to move along the negative gradient of loss as we go from one block to the next. In addition, our empirical analysis suggests that Resnets are able to perform both representation learning and iterative refinement. In general, a Resnet block tends to concentrate representation learning behavior in the first few layers while higher layers perform iterative refinement of features. Finally we observe that sharing residual layers naively leads to representation explosion and counterintuitively, overfitting, and we show that simple existing strategies can help alleviating this problem.
Deep Semi-Random Features for Nonlinear Function Approximation
Nov 21, 2017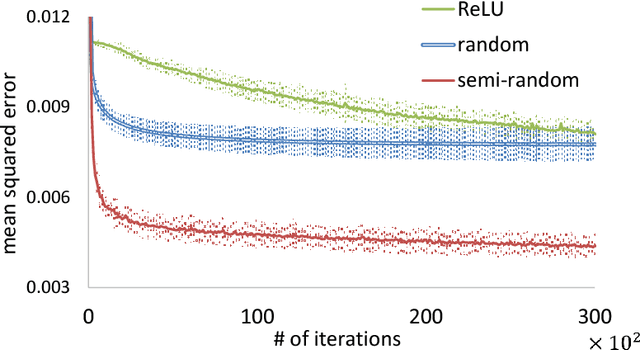
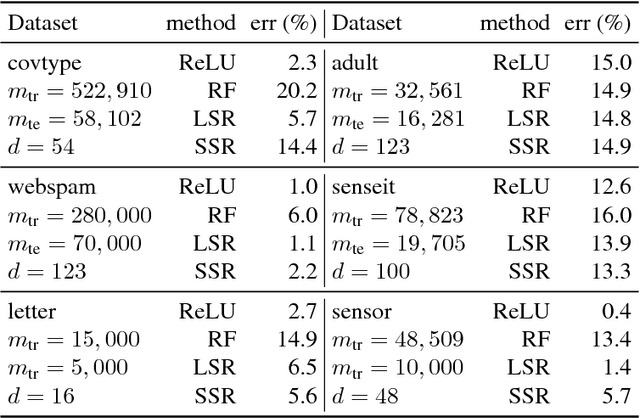
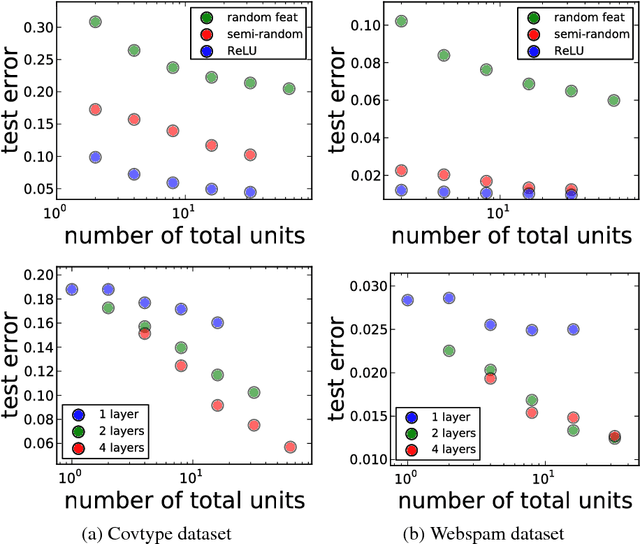
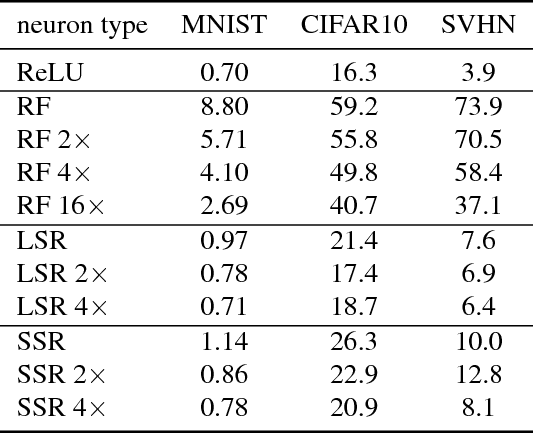
We propose semi-random features for nonlinear function approximation. The flexibility of semi-random feature lies between the fully adjustable units in deep learning and the random features used in kernel methods. For one hidden layer models with semi-random features, we prove with no unrealistic assumptions that the model classes contain an arbitrarily good function as the width increases (universality), and despite non-convexity, we can find such a good function (optimization theory) that generalizes to unseen new data (generalization bound). For deep models, with no unrealistic assumptions, we prove universal approximation ability, a lower bound on approximation error, a partial optimization guarantee, and a generalization bound. Depending on the problems, the generalization bound of deep semi-random features can be exponentially better than the known bounds of deep ReLU nets; our generalization error bound can be independent of the depth, the number of trainable weights as well as the input dimensionality. In experiments, we show that semi-random features can match the performance of neural networks by using slightly more units, and it outperforms random features by using significantly fewer units. Moreover, we introduce a new implicit ensemble method by using semi-random features.
Image Retrieval And Classification Using Local Feature Vectors
Sep 02, 2014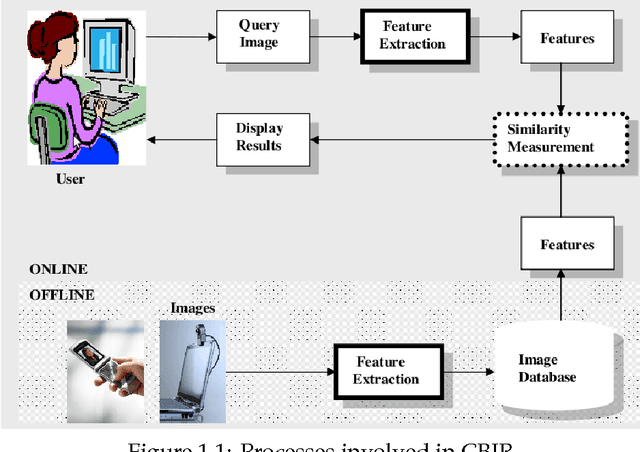
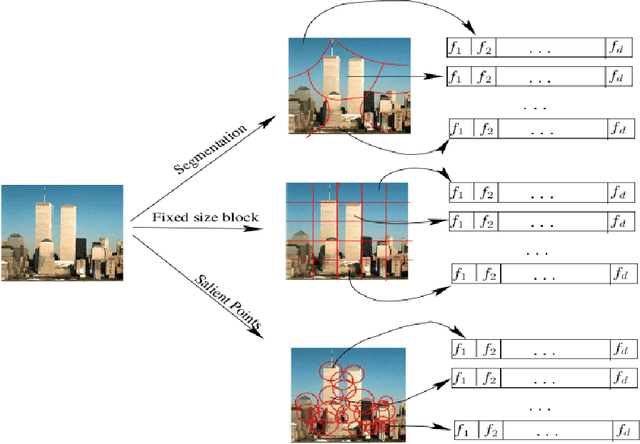
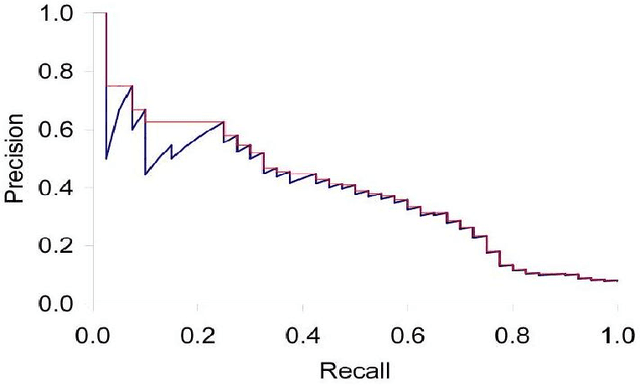
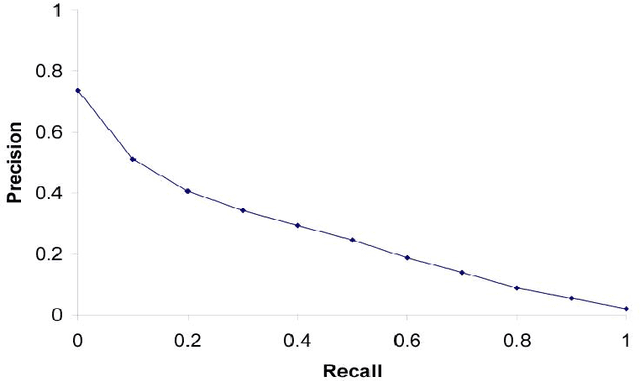
Content Based Image Retrieval(CBIR) is one of the important subfield in the field of Information Retrieval. The goal of a CBIR algorithm is to retrieve semantically similar images in response to a query image submitted by the end user. CBIR is a hard problem because of the phenomenon known as $\textit {semantic gap}$. In this thesis, we aim at analyzing the performance of a CBIR system build using local feature vectors and Intermediate Matching Kernel. We also propose a Two-Step Matching process for reducing the response time of the CBIR systems. Further, we develop a Meta-Learning framework for improving the retrieval performance of these systems. Our results show that the Two-Step Matching process significantly reduces response time and the Meta-Learning Framework improves the retrieval performance by more than two fold. We also analyze the performance of various image classification systems that use different image representations constructed from the local feature vectors.