 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Apr 30, 2020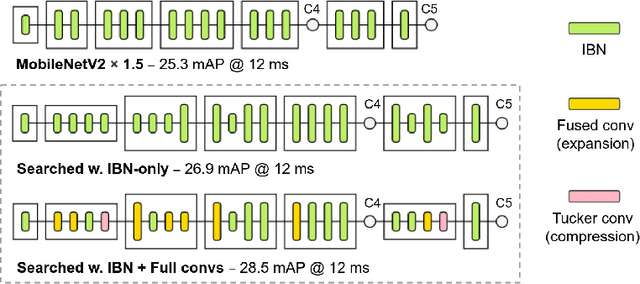
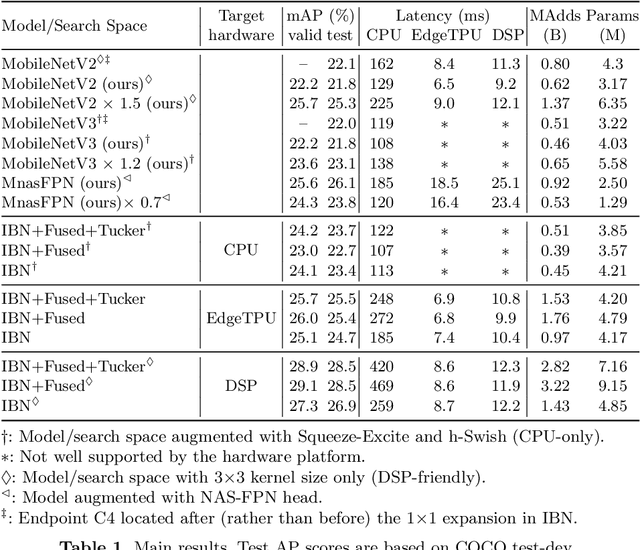
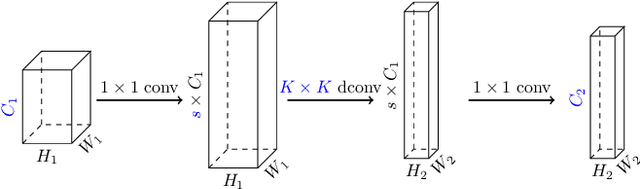
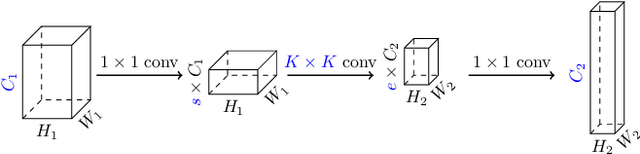
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we question the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We achieve substantial improvements in the latency-accuracy trade-off by incorporating regular convolutions in the search space, and effectively placing them in the network via neural architecture search. We obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on EdgeTPUs and 3.4 mAP on DSPs while running equally fast. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2X speedup.
FairALM: Augmented Lagrangian Method for Training Fair Models with Little Regret
Apr 03, 2020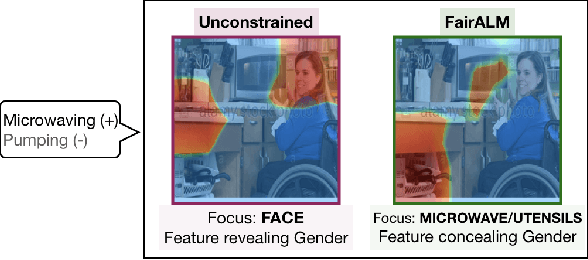
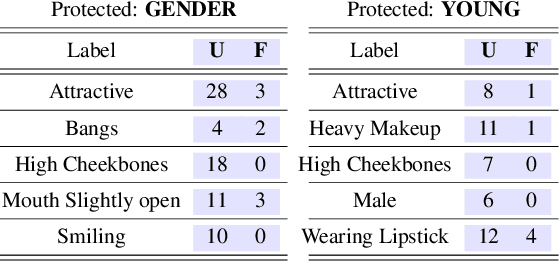
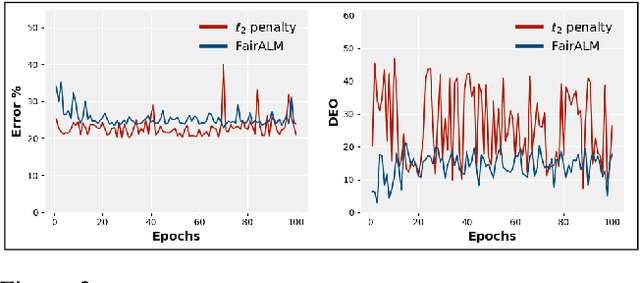
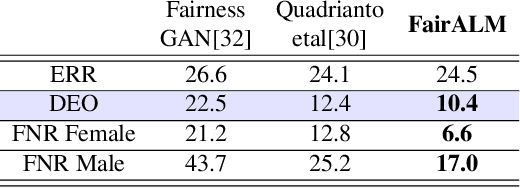
Algorithmic decision making based on computer vision and machine learning technologies continue to permeate our lives. But issues related to biases of these models and the extent to which they treat certain segments of the population unfairly, have led to concern in the general public. It is now accepted that because of biases in the datasets we present to the models, a fairness-oblivious training will lead to unfair models. An interesting topic is the study of mechanisms via which the de novo design or training of the model can be informed by fairness measures. Here, we study mechanisms that impose fairness concurrently while training the model. While existing fairness based approaches in vision have largely relied on training adversarial modules together with the primary classification/regression task, in an effort to remove the influence of the protected attribute or variable, we show how ideas based on well-known optimization concepts can provide a simpler alternative. In our proposed scheme, imposing fairness just requires specifying the protected attribute and utilizing our optimization routine. We provide a detailed technical analysis and present experiments demonstrating that various fairness measures from the literature can be reliably imposed on a number of training tasks in vision in a manner that is interpretable.
mRMR-DNN with Transfer Learning for IntelligentFault Diagnosis of Rotating Machines
Dec 25, 2019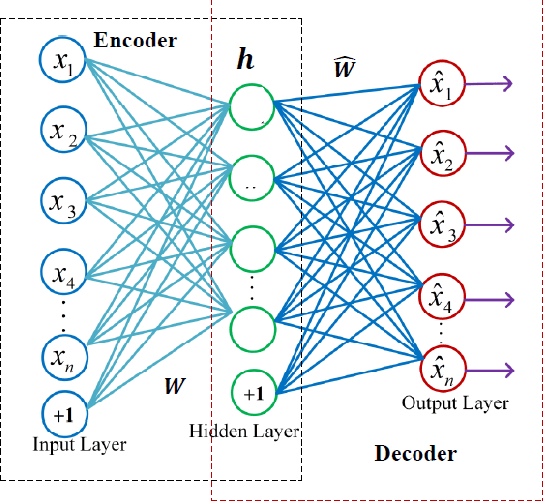
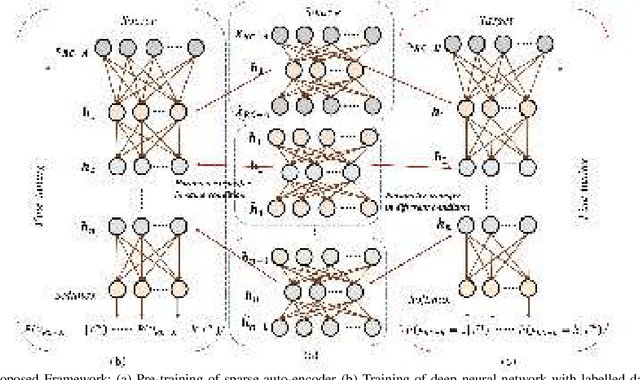

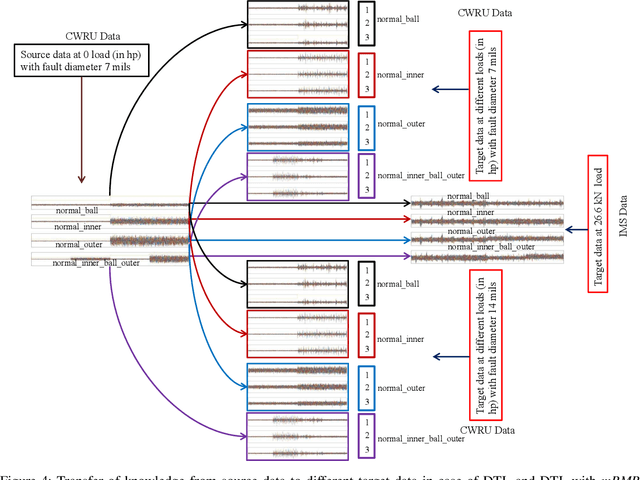
In recent years, intelligent condition-based monitoring of rotary machinery systems has become a major research focus of machine fault diagnosis. In condition-based monitoring, it is challenging to form a large-scale well-annotated dataset due to the expense of data acquisition and costly annotation. Along with that, the generated data have a large number of redundant features which degraded the performance of the machine learning models. To overcome this, we have utilized the advantages of minimum redundancy maximum relevance (mRMR) and transfer learning with deep learning model. In this work, mRMR is combined with deep learning and deep transfer learning framework to improve the fault diagnostics performance in term of accuracy and computational complexity. The mRMR reduces the redundant information from data and increases the deep learning performance, whereas transfer learning, reduces a large amount of data dependency for training the model. In the proposed work, two frameworks, i.e., mRMR with deep learning and mRMR with deep transfer learning, have explored and validated on CWRU and IMS rolling element bearings datasets. The analysis shows that the proposed frameworks are able to obtain better diagnostic accuracy in comparison of existing methods and also able to handle the data with a large number of features more quickly.
An Entropy-based Variable Feature Weighted Fuzzy k-Means Algorithm for High Dimensional Data
Dec 24, 2019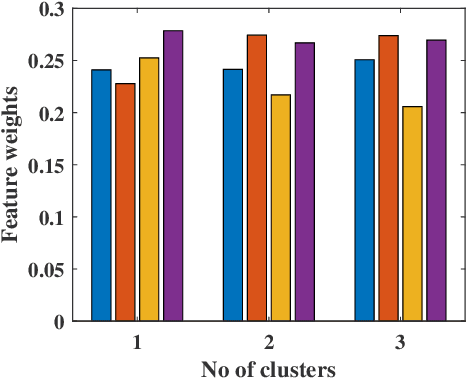
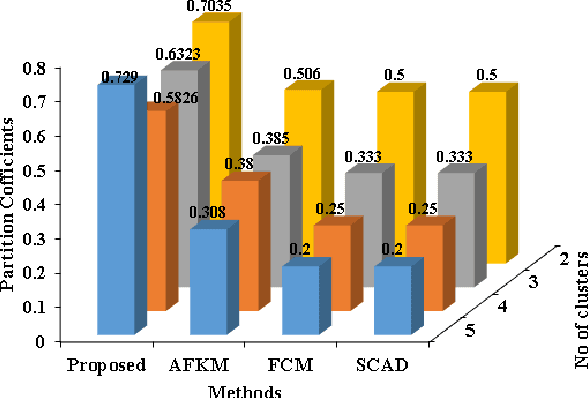
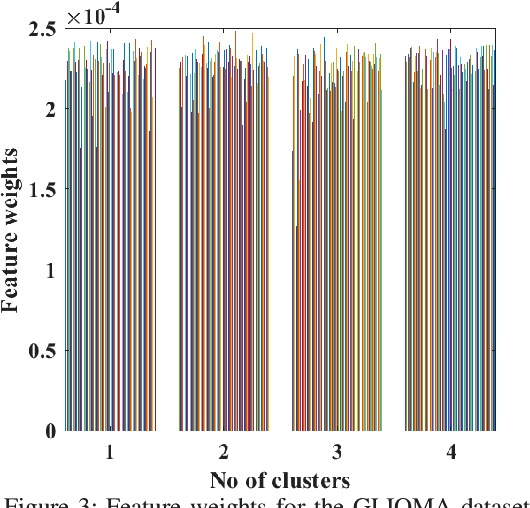
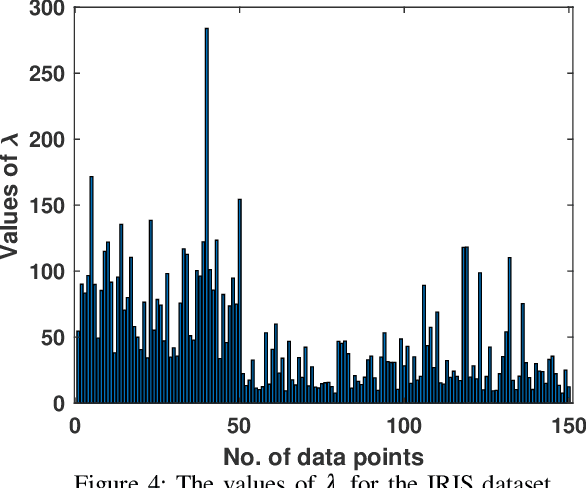
This paper presents a new fuzzy k-means algorithm for the clustering of high dimensional data in various subspaces. Since, In the case of high dimensional data, some features might be irrelevant and relevant but may have different significance in the clustering. For a better clustering, it is crucial to incorporate the contribution of these features in the clustering process. To combine these features, in this paper, we have proposed a new fuzzy k-means clustering algorithm in which the objective function of the fuzzy k-means is modified using two different entropy term. The first entropy term helps to minimize the within-cluster dispersion and maximize the negative entropy to determine clusters to contribute to the association of data points. The second entropy term helps to control the weight of the features because different features have different contributing weights in the clustering process for obtaining the better partition of the data. The efficacy of the proposed method is presented in terms of various clustering measures on multiple datasets and compared with various state-of-the-art methods.
Dilated Convolutional Neural Networks for Sequential Manifold-valued Data
Oct 05, 2019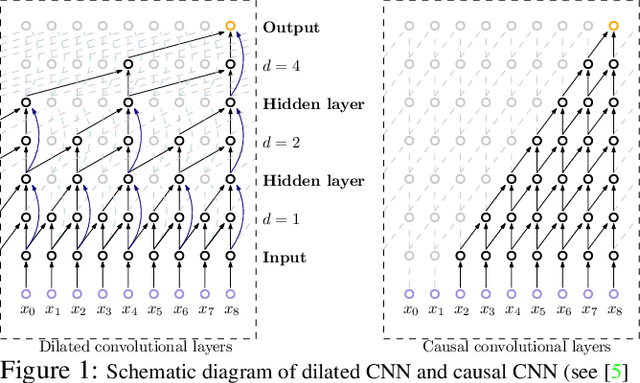
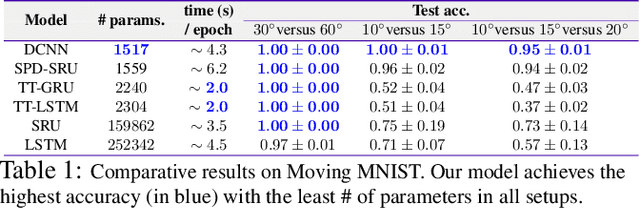
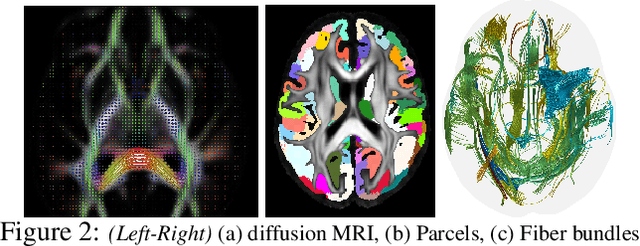
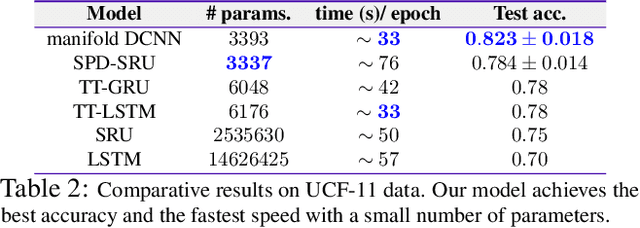
Efforts are underway to study ways via which the power of deep neural networks can be extended to non-standard data types such as structured data (e.g., graphs) or manifold-valued data (e.g., unit vectors or special matrices). Often, sizable empirical improvements are possible when the geometry of such data spaces are incorporated into the design of the model, architecture, and the algorithms. Motivated by neuroimaging applications, we study formulations where the data are {\em sequential manifold-valued measurements}. This case is common in brain imaging, where the samples correspond to symmetric positive definite matrices or orientation distribution functions. Instead of a recurrent model which poses computational/technical issues, and inspired by recent results showing the viability of dilated convolutional models for sequence prediction, we develop a dilated convolutional neural network architecture for this task. On the technical side, we show how the modules needed in our network can be derived while explicitly taking the Riemannian manifold structure into account. We show how the operations needed can leverage known results for calculating the weighted Fr\'{e}chet Mean (wFM). Finally, we present scientific results for group difference analysis in Alzheimer's disease (AD) where the groups are derived using AD pathology load: here the model finds several brain fiber bundles that are related to AD even when the subjects are all still cognitively healthy.
Optimizing Nondecomposable Data Dependent Regularizers via Lagrangian Reparameterization offers Significant Performance and Efficiency Gains
Sep 26, 2019
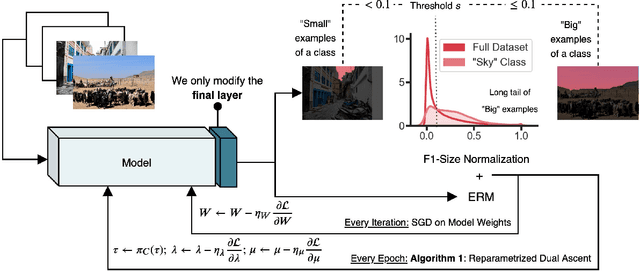
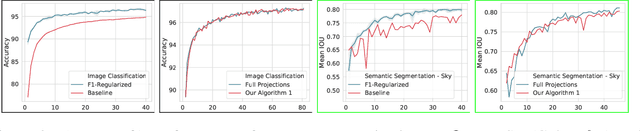

Data dependent regularization is known to benefit a wide variety of problems in machine learning. Often, these regularizers cannot be easily decomposed into a sum over a finite number of terms, e.g., a sum over individual example-wise terms. The $F_\beta$ measure, Area under the ROC curve (AUCROC) and Precision at a fixed recall (P@R) are some prominent examples that are used in many applications. We find that for most medium to large sized datasets, scalability issues severely limit our ability in leveraging the benefits of such regularizers. Importantly, the key technical impediment despite some recent progress is that, such objectives remain difficult to optimize via backpropapagation procedures. While an efficient general-purpose strategy for this problem still remains elusive, in this paper, we show that for many data-dependent nondecomposable regularizers that are relevant in applications, sizable gains in efficiency are possible with minimal code-level changes; in other words, no specialized tools or numerical schemes are needed. Our procedure involves a reparameterization followed by a partial dualization -- this leads to a formulation that has provably cheap projection operators. We present a detailed analysis of runtime and convergence properties of our algorithm. On the experimental side, we show that a direct use of our scheme significantly improves the state of the art IOU measures reported for MSCOCO Stuff segmentation dataset.
Generating Accurate Pseudo-labels via Hermite Polynomials for SSL Confidently
Sep 12, 2019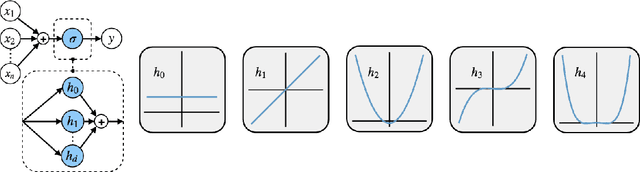

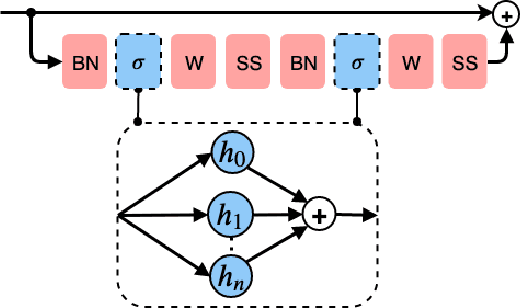
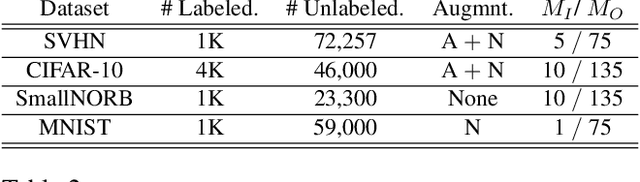
Rectified Linear Units (ReLUs) are among the most widely used activation function in a broad variety of tasks in vision. Recent theoretical results suggest that despite their excellent practical performance, in various cases, a substitution with basis expansions (e.g., polynomials) can yield significant benefits from both the optimization and generalization perspective. Unfortunately, the existing results remain limited to networks with a couple of layers, and the practical viability of these results is not yet known. Motivated by some of these results, we explore the use of Hermite polynomial expansions as a substitute for ReLUs in deep networks. While our experiments with supervised learning do not provide a clear verdict, we find that this strategy offers considerable benefits in semi-supervised learning (SSL) / transductive learning settings. We carefully develop this idea and show how the use of Hermite polynomials based activations can yield improvements in pseudo-label accuracies and sizable financial savings (due to concurrent runtime benefits). Further, we show via theoretical analysis, that the networks (with Hermite activations) offer robustness to noise and other attractive mathematical properties.
DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer
Aug 21, 2019

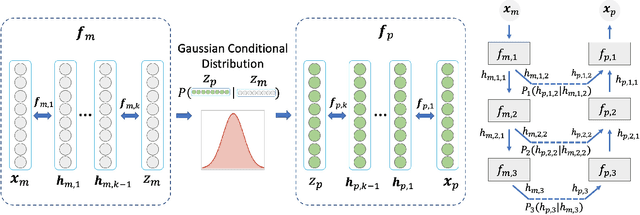
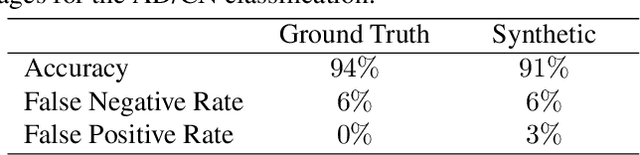
Positron emission tomography (PET) imaging is an imaging modality for diagnosing a number of neurological diseases. In contrast to Magnetic Resonance Imaging (MRI), PET is costly and involves injecting a radioactive substance into the patient. Motivated by developments in modality transfer in vision, we study the generation of certain types of PET images from MRI data. We derive new flow-based generative models which we show perform well in this small sample size regime (much smaller than dataset sizes available in standard vision tasks). Our formulation, DUAL-GLOW, is based on two invertible networks and a relation network that maps the latent spaces to each other. We discuss how given the prior distribution, learning the conditional distribution of PET given the MRI image reduces to obtaining the conditional distribution between the two latent codes w.r.t. the two image types. We also extend our framework to leverage 'side' information (or attributes) when available. By controlling the PET generation through 'conditioning' on age, our model is also able to capture brain FDG-PET (hypometabolism) changes, as a function of age. We present experiments on the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset with 826 subjects, and obtain good performance in PET image synthesis, qualitatively and quantitatively better than recent works.
Fooling Computer Vision into Inferring the Wrong Body Mass Index
May 16, 2019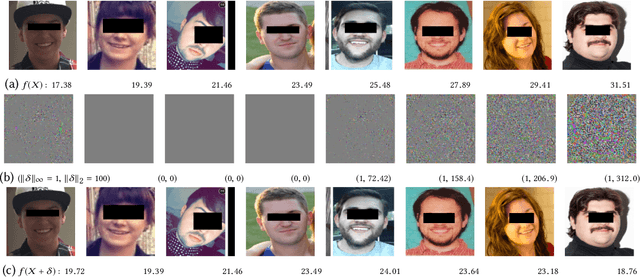
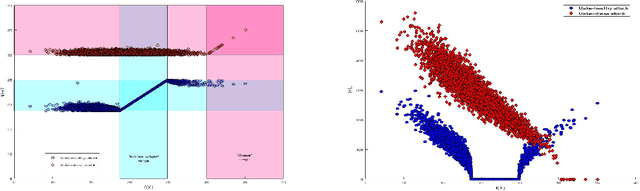
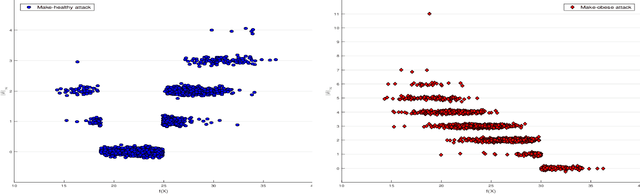
Recently it's been shown that neural networks can use images of human faces to accurately predict Body Mass Index (BMI), a widely used health indicator. In this paper we demonstrate that a neural network performing BMI inference is indeed vulnerable to test-time adversarial attacks. This extends test-time adversarial attacks from classification tasks to regression. The application we highlight is BMI inference in the insurance industry, where such adversarial attacks imply a danger of insurance fraud.
Resource Constrained Neural Network Architecture Search
Apr 08, 2019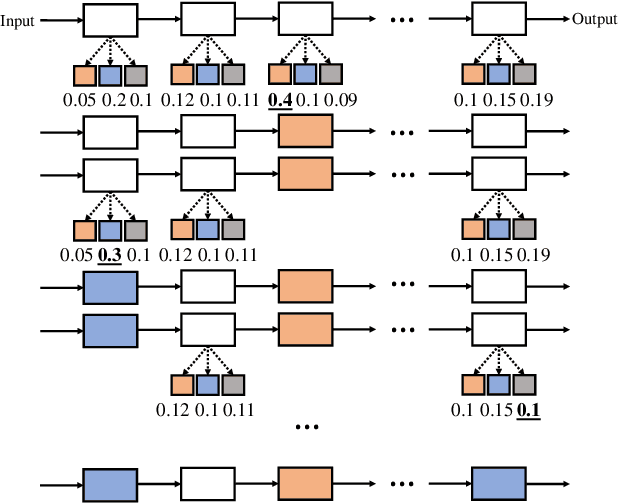

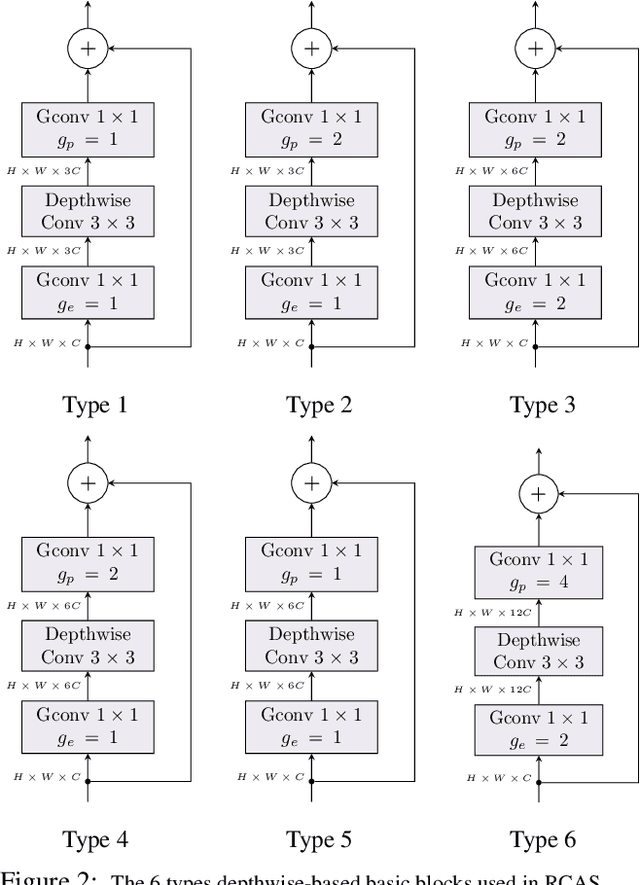

The design of neural network architectures is frequently either based on human expertise using trial/error and empirical feedback or tackled via large scale reinforcement learning strategies run over distinct discrete architecture choices. In the latter case, the optimization task is non-differentiable and also not very amenable to derivative-free optimization methods. Most methods in use today require exorbitant computational resources. And if we want networks that additionally satisfy resource constraints, the above challenges are exacerbated because the search procedure must now balance accuracy with certain budget constraints on resources. We formulate this problem as the optimization of a set function - we find that the empirical behavior of this set function often (but not always) satisfies marginal gain and monotonicity principles - properties central to the idea of submodularity. Based on this observation, we adapt algorithms that are well-known within discrete optimization to obtain heuristic schemes for neural network architecture search, with resource constraints on the architecture. This simple scheme when applied on CIFAR-100 and ImageNet, identifies resource-constrained architectures with quantifiably better performance than current state-of-the-art models designed for mobile devices. Specifically, we find high-performing architectures with fewer parameters and computations by a search method that is much faster.