 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubricRefine: Improving Tool-Use Agent Reliability with Training-Free Pre-Execution Refinement
May 10, 2026Iterative self-refinement is a popular inference-time reliability technique, but its effectiveness in code-mode tool use depends heavily on the structure of the feedback signal: unstructured critique helps inconsistently across models, and even revision with real execution feedback improves only modestly ($0.75$ vs. $0.65$ baseline). The dominant failures are inter-tool contract violations - wrong output shape, incorrect tool routing, broken argument provenance - that run to completion without raising errors, making runtime feedback insufficient. We introduce RubricRefine, a training-free pre-execution reliability layer that generates task- and registry-specific rubrics, scores candidate code against explicit contract checks, and iteratively repairs failures before any execution occurs. With zero execution attempts, RubricRefine reaches $0.86$ on M3ToolEval averaged across seven models-improving over prior inference-time baselines on every model tested on this benchmark, at $2.6X$ lower latency than the strongest non-iterative alternative - and remains flat on the predominantly single-step API-Bank, consistent with the method's reliance on inter-tool contract structure. A rubric-category ablation and calibration analysis further characterize when and why the method works.
Optimizing Nondecomposable Data Dependent Regularizers via Lagrangian Reparameterization offers Significant Performance and Efficiency Gains
Sep 26, 2019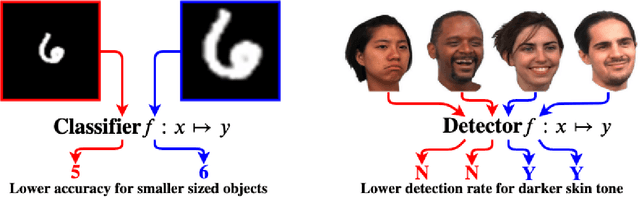
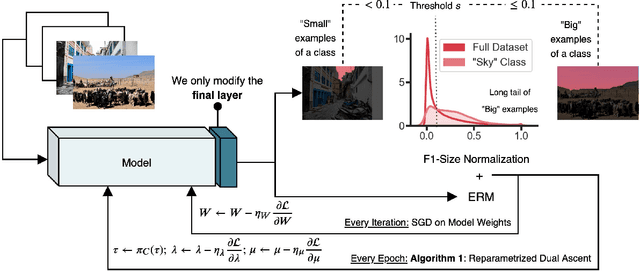
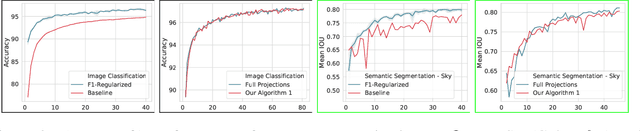

Data dependent regularization is known to benefit a wide variety of problems in machine learning. Often, these regularizers cannot be easily decomposed into a sum over a finite number of terms, e.g., a sum over individual example-wise terms. The $F_\beta$ measure, Area under the ROC curve (AUCROC) and Precision at a fixed recall (P@R) are some prominent examples that are used in many applications. We find that for most medium to large sized datasets, scalability issues severely limit our ability in leveraging the benefits of such regularizers. Importantly, the key technical impediment despite some recent progress is that, such objectives remain difficult to optimize via backpropapagation procedures. While an efficient general-purpose strategy for this problem still remains elusive, in this paper, we show that for many data-dependent nondecomposable regularizers that are relevant in applications, sizable gains in efficiency are possible with minimal code-level changes; in other words, no specialized tools or numerical schemes are needed. Our procedure involves a reparameterization followed by a partial dualization -- this leads to a formulation that has provably cheap projection operators. We present a detailed analysis of runtime and convergence properties of our algorithm. On the experimental side, we show that a direct use of our scheme significantly improves the state of the art IOU measures reported for MSCOCO Stuff segmentation dataset.
Generating Accurate Pseudo-labels via Hermite Polynomials for SSL Confidently
Sep 12, 2019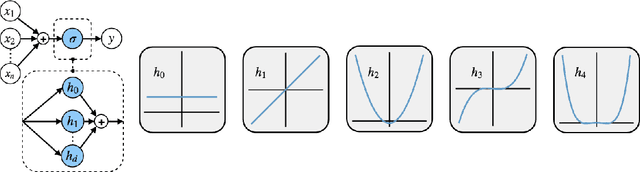

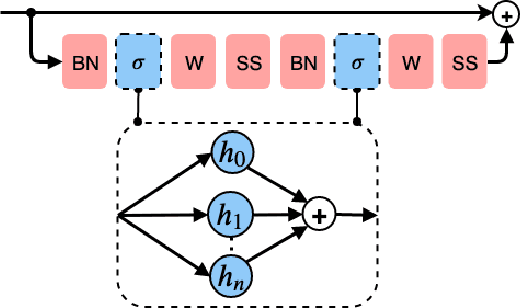
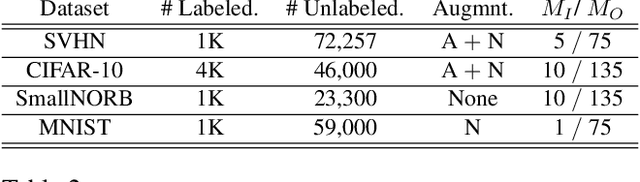
Rectified Linear Units (ReLUs) are among the most widely used activation function in a broad variety of tasks in vision. Recent theoretical results suggest that despite their excellent practical performance, in various cases, a substitution with basis expansions (e.g., polynomials) can yield significant benefits from both the optimization and generalization perspective. Unfortunately, the existing results remain limited to networks with a couple of layers, and the practical viability of these results is not yet known. Motivated by some of these results, we explore the use of Hermite polynomial expansions as a substitute for ReLUs in deep networks. While our experiments with supervised learning do not provide a clear verdict, we find that this strategy offers considerable benefits in semi-supervised learning (SSL) / transductive learning settings. We carefully develop this idea and show how the use of Hermite polynomials based activations can yield improvements in pseudo-label accuracies and sizable financial savings (due to concurrent runtime benefits). Further, we show via theoretical analysis, that the networks (with Hermite activations) offer robustness to noise and other attractive mathematical properties.