 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENERIC-FNO: Embedding Energy Conservation and Entropy Production into Fourier Neural Operators
Jun 06, 2026We introduce GENERIC-FNO, the first neural operator to embed the full GENERIC (metriplectic) structure of nonequilibrium thermodynamics -- reversible, energy-conserving dynamics and irreversible, entropy-producing dynamics coupled through the degeneracy conditions -- directly in function space. Existing structure-preserving neural operators enforce at most a single conservation law or reversible (Hamiltonian) structure, while thermodynamically consistent learning has been confined to finite-dimensional, graph, or particle systems. GENERIC-FNO closes this gap: it learns the energy and entropy functionals as neural operators and parameterizes the Poisson and friction operators as diagonal Fourier multipliers sandwiched between rank-one projections that enforce the degeneracy conditions exactly, by construction, with no penalty term, update projection, or residual. The degeneracy identities hold to machine precision (residuals ~10^-13) for any initialization, dimension, or resolution, so the continuous-time dynamics conserve the learned energy and produce entropy exactly; the explicit time stepping adds only a small O(dt^2) drift (per-step residual ~10^-6). We further note that the (E,S,L,M) decomposition of a given flow is not unique, and introduce a gauge-invariant dissipation diagnostic separating reversible from dissipative dynamics independently of the learned functionals. Across three operator backbones (1D/2D FNOs and DeepONet) and four PDEs spanning reversible, dissipative, and mixed regimes, GENERIC-FNO preserves its exact structural guarantees zero-shot across a 4x super-resolution range (64 to 256), recovers the ground-truth ordering of physical dissipation, and is competitive with strong unconstrained and energy-penalized baselines, outperforming them on several dissipative and mixed problems at comparable or fewer parameters.
STARNet: Sensor Trustworthiness and Anomaly Recognition via Approximated Likelihood Regret for Robust Edge Autonomy
Sep 20, 2023



Complex sensors such as LiDAR, RADAR, and event cameras have proliferated in autonomous robotics to enhance perception and understanding of the environment. Meanwhile, these sensors are also vulnerable to diverse failure mechanisms that can intricately interact with their operation environment. In parallel, the limited availability of training data on complex sensors also affects the reliability of their deep learning-based prediction flow, where their prediction models can fail to generalize to environments not adequately captured in the training set. To address these reliability concerns, this paper introduces STARNet, a Sensor Trustworthiness and Anomaly Recognition Network designed to detect untrustworthy sensor streams that may arise from sensor malfunctions and/or challenging environments. We specifically benchmark STARNet on LiDAR and camera data. STARNet employs the concept of approximated likelihood regret, a gradient-free framework tailored for low-complexity hardware, especially those with only fixed-point precision capabilities. Through extensive simulations, we demonstrate the efficacy of STARNet in detecting untrustworthy sensor streams in unimodal and multimodal settings. In particular, the network shows superior performance in addressing internal sensor failures, such as cross-sensor interference and crosstalk. In diverse test scenarios involving adverse weather and sensor malfunctions, we show that STARNet enhances prediction accuracy by approximately 10% by filtering out untrustworthy sensor streams. STARNet is publicly available at \url{https://github.com/sinatayebati/STARNet}.
Mutual Information-calibrated Conformal Feature Fusion for Uncertainty-Aware Multimodal 3D Object Detection at the Edge
Sep 18, 2023



In the expanding landscape of AI-enabled robotics, robust quantification of predictive uncertainties is of great importance. Three-dimensional (3D) object detection, a critical robotics operation, has seen significant advancements; however, the majority of current works focus only on accuracy and ignore uncertainty quantification. Addressing this gap, our novel study integrates the principles of conformal inference (CI) with information theoretic measures to perform lightweight, Monte Carlo-free uncertainty estimation within a multimodal framework. Through a multivariate Gaussian product of the latent variables in a Variational Autoencoder (VAE), features from RGB camera and LiDAR sensor data are fused to improve the prediction accuracy. Normalized mutual information (NMI) is leveraged as a modulator for calibrating uncertainty bounds derived from CI based on a weighted loss function. Our simulation results show an inverse correlation between inherent predictive uncertainty and NMI throughout the model's training. The framework demonstrates comparable or better performance in KITTI 3D object detection benchmarks to similar methods that are not uncertainty-aware, making it suitable for real-time edge robotics.
Robust Monocular Localization of Drones by Adapting Domain Maps to Depth Prediction Inaccuracies
Oct 27, 2022



We present a novel monocular localization framework by jointly training deep learning-based depth prediction and Bayesian filtering-based pose reasoning. The proposed cross-modal framework significantly outperforms deep learning-only predictions with respect to model scalability and tolerance to environmental variations. Specifically, we show little-to-no degradation of pose accuracy even with extremely poor depth estimates from a lightweight depth predictor. Our framework also maintains high pose accuracy in extreme lighting variations compared to standard deep learning, even without explicit domain adaptation. By openly representing the map and intermediate feature maps (such as depth estimates), our framework also allows for faster updates and reusing intermediate predictions for other tasks, such as obstacle avoidance, resulting in much higher resource efficiency.
Generating Accurate Pseudo-labels via Hermite Polynomials for SSL Confidently
Sep 12, 2019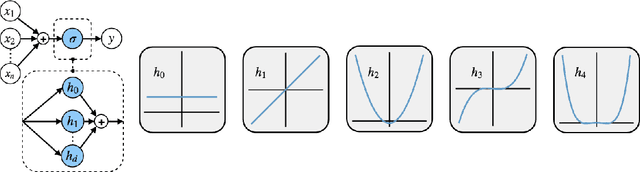

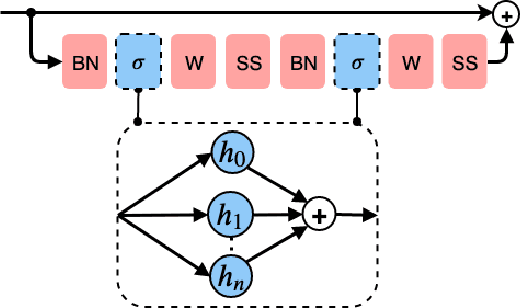
Rectified Linear Units (ReLUs) are among the most widely used activation function in a broad variety of tasks in vision. Recent theoretical results suggest that despite their excellent practical performance, in various cases, a substitution with basis expansions (e.g., polynomials) can yield significant benefits from both the optimization and generalization perspective. Unfortunately, the existing results remain limited to networks with a couple of layers, and the practical viability of these results is not yet known. Motivated by some of these results, we explore the use of Hermite polynomial expansions as a substitute for ReLUs in deep networks. While our experiments with supervised learning do not provide a clear verdict, we find that this strategy offers considerable benefits in semi-supervised learning (SSL) / transductive learning settings. We carefully develop this idea and show how the use of Hermite polynomials based activations can yield improvements in pseudo-label accuracies and sizable financial savings (due to concurrent runtime benefits). Further, we show via theoretical analysis, that the networks (with Hermite activations) offer robustness to noise and other attractive mathematical properties.
Convergence rates for pretraining and dropout: Guiding learning parameters using network structure
Feb 22, 2017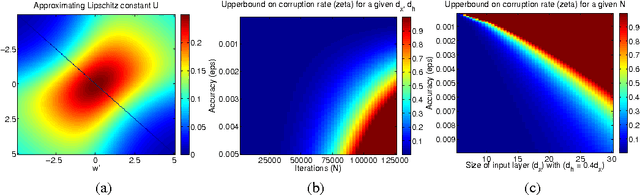
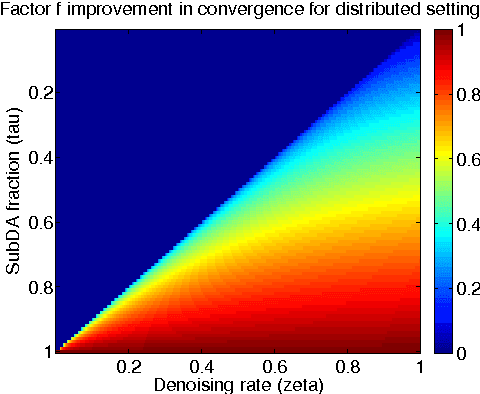
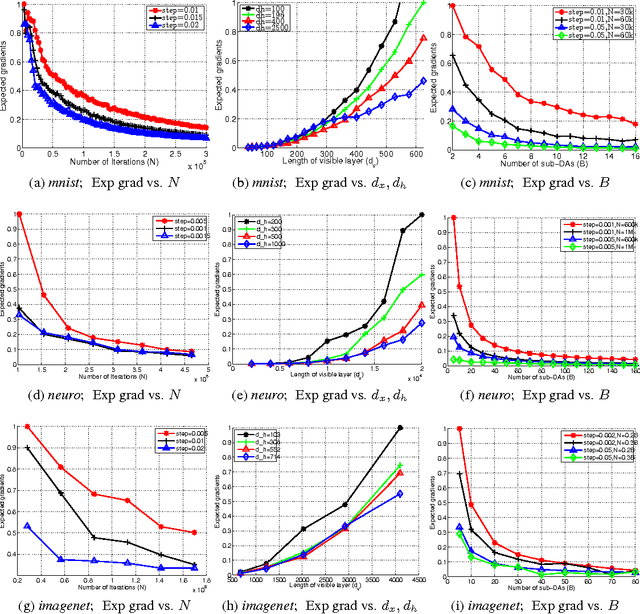
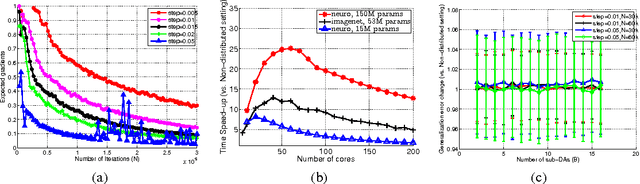
Unsupervised pretraining and dropout have been well studied, especially with respect to regularization and output consistency. However, our understanding about the explicit convergence rates of the parameter estimates, and their dependence on the learning (like denoising and dropout rate) and structural (like depth and layer lengths) aspects of the network is less mature. An interesting question in this context is to ask if the network structure could "guide" the choices of such learning parameters. In this work, we explore these gaps between network structure, the learning mechanisms and their interaction with parameter convergence rates. We present a way to address these issues based on the backpropagation convergence rates for general nonconvex objectives using first-order information. We then incorporate two learning mechanisms into this general framework -- denoising autoencoder and dropout, and subsequently derive the convergence rates of deep networks. Building upon these bounds, we provide insights into the choices of learning parameters and network sizes that achieve certain levels of convergence accuracy. The results derived here support existing empirical observations, and we also conduct a set of experiments to evaluate them.
Convergence of gradient based pre-training in Denoising autoencoders
Feb 12, 2015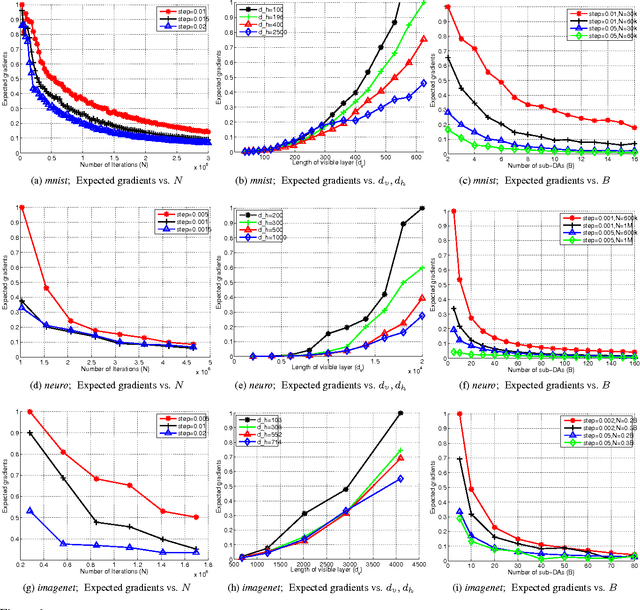
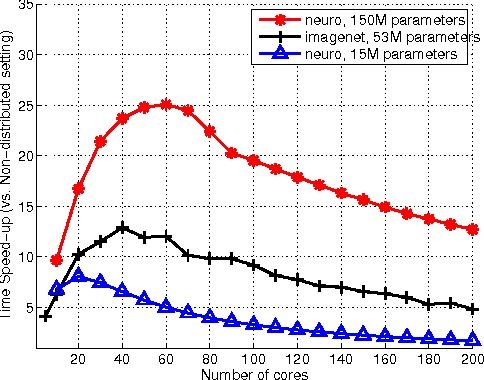
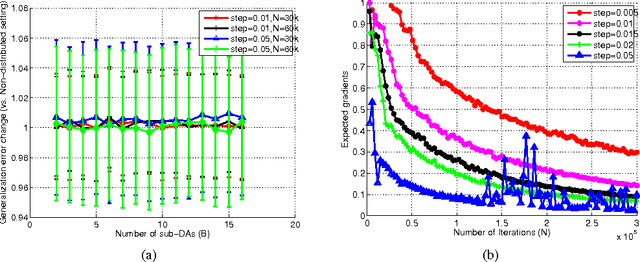
The success of deep architectures is at least in part attributed to the layer-by-layer unsupervised pre-training that initializes the network. Various papers have reported extensive empirical analysis focusing on the design and implementation of good pre-training procedures. However, an understanding pertaining to the consistency of parameter estimates, the convergence of learning procedures and the sample size estimates is still unavailable in the literature. In this work, we study pre-training in classical and distributed denoising autoencoders with these goals in mind. We show that the gradient converges at the rate of $\frac{1}{\sqrt{N}}$ and has a sub-linear dependence on the size of the autoencoder network. In a distributed setting where disjoint sections of the whole network are pre-trained synchronously, we show that the convergence improves by at least $\tau^{3/4}$, where $\tau$ corresponds to the size of the sections. We provide a broad set of experiments to empirically evaluate the suggested behavior.