 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens
May 07, 2023



Transformer models are foundational to natural language processing (NLP) and computer vision. Despite various recent works devoted to reducing the quadratic cost of such models (as a function of the sequence length $n$), dealing with ultra long sequences efficiently (e.g., with more than 16K tokens) remains challenging. Applications such as answering questions based on an entire book or summarizing a scientific article are inefficient or infeasible. In this paper, we propose to significantly reduce the dependency of a Transformer model's complexity on $n$, by compressing the input into a representation whose size $r$ is independent of $n$ at each layer. Specifically, by exploiting the fact that in many tasks, only a small subset of special tokens (we call VIP-tokens) are most relevant to the final prediction, we propose a VIP-token centric compression (Vcc) scheme which selectively compresses the input sequence based on their impact on approximating the representation of these VIP-tokens. Compared with competitive baselines, the proposed algorithm not only is efficient (achieving more than $3\times$ efficiency improvement compared to baselines on 4K and 16K lengths), but also achieves competitive or better performance on a large number of tasks. Further, we show that our algorithm can be scaled to 128K tokens (or more) while consistently offering accuracy improvement.
Multi Resolution Analysis (MRA) for Approximate Self-Attention
Jul 21, 2022
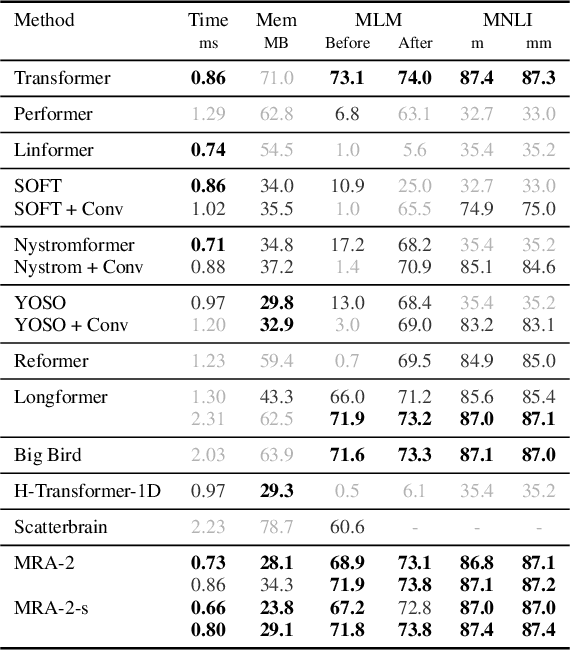

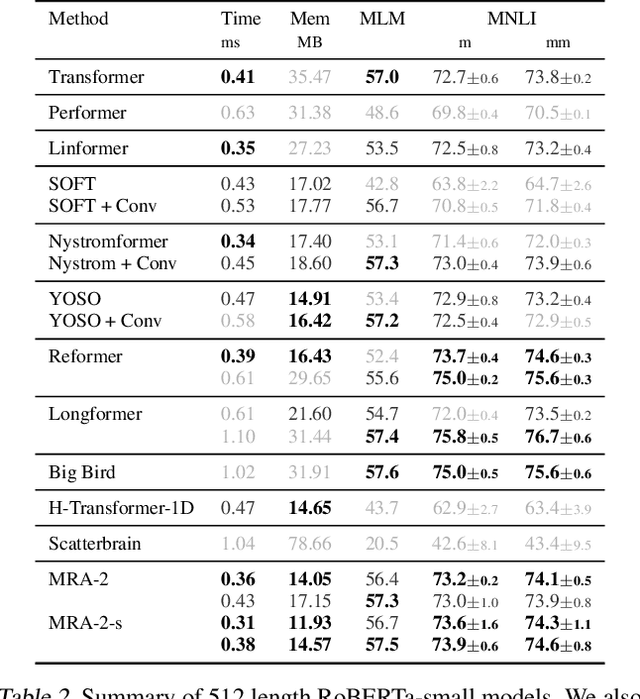
Transformers have emerged as a preferred model for many tasks in natural langugage processing and vision. Recent efforts on training and deploying Transformers more efficiently have identified many strategies to approximate the self-attention matrix, a key module in a Transformer architecture. Effective ideas include various prespecified sparsity patterns, low-rank basis expansions and combinations thereof. In this paper, we revisit classical Multiresolution Analysis (MRA) concepts such as Wavelets, whose potential value in this setting remains underexplored thus far. We show that simple approximations based on empirical feedback and design choices informed by modern hardware and implementation challenges, eventually yield a MRA-based approach for self-attention with an excellent performance profile across most criteria of interest. We undertake an extensive set of experiments and demonstrate that this multi-resolution scheme outperforms most efficient self-attention proposals and is favorable for both short and long sequences. Code is available at \url{https://github.com/mlpen/mra-attention}.
On the Versatile Uses of Partial Distance Correlation in Deep Learning
Jul 20, 2022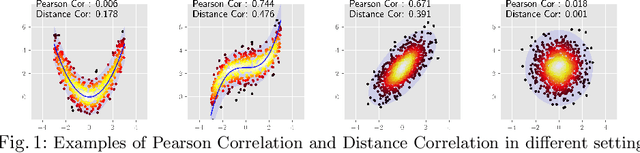
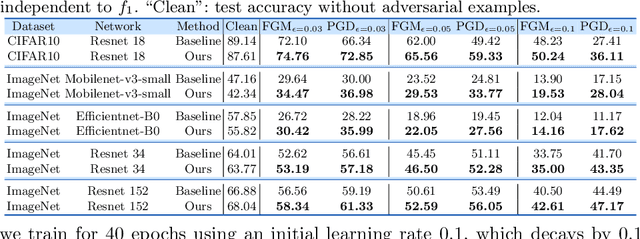
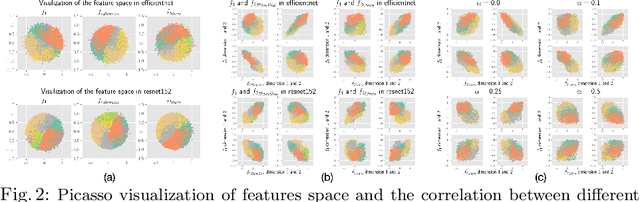
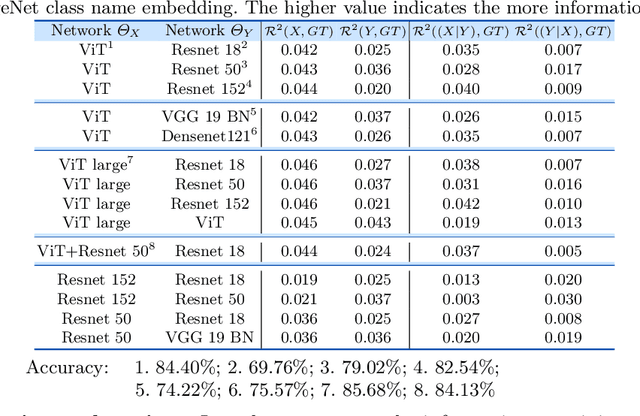
Comparing the functional behavior of neural network models, whether it is a single network over time or two (or more networks) during or post-training, is an essential step in understanding what they are learning (and what they are not), and for identifying strategies for regularization or efficiency improvements. Despite recent progress, e.g., comparing vision transformers to CNNs, systematic comparison of function, especially across different networks, remains difficult and is often carried out layer by layer. Approaches such as canonical correlation analysis (CCA) are applicable in principle, but have been sparingly used so far. In this paper, we revisit a (less widely known) from statistics, called distance correlation (and its partial variant), designed to evaluate correlation between feature spaces of different dimensions. We describe the steps necessary to carry out its deployment for large scale models -- this opens the door to a surprising array of applications ranging from conditioning one deep model w.r.t. another, learning disentangled representations as well as optimizing diverse models that would directly be more robust to adversarial attacks. Our experiments suggest a versatile regularizer (or constraint) with many advantages, which avoids some of the common difficulties one faces in such analyses. Code is at https://github.com/zhenxingjian/Partial_Distance_Correlation.
Deep Unlearning via Randomized Conditionally Independent Hessians
Apr 15, 2022
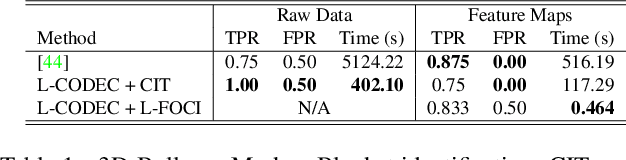
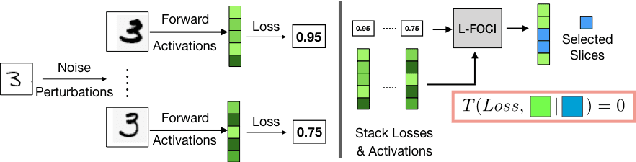
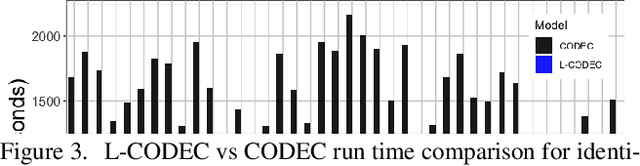
Recent legislation has led to interest in machine unlearning, i.e., removing specific training samples from a predictive model as if they never existed in the training dataset. Unlearning may also be required due to corrupted/adversarial data or simply a user's updated privacy requirement. For models which require no training (k-NN), simply deleting the closest original sample can be effective. But this idea is inapplicable to models which learn richer representations. Recent ideas leveraging optimization-based updates scale poorly with the model dimension d, due to inverting the Hessian of the loss function. We use a variant of a new conditional independence coefficient, L-CODEC, to identify a subset of the model parameters with the most semantic overlap on an individual sample level. Our approach completely avoids the need to invert a (possibly) huge matrix. By utilizing a Markov blanket selection, we premise that L-CODEC is also suitable for deep unlearning, as well as other applications in vision. Compared to alternatives, L-CODEC makes approximate unlearning possible in settings that would otherwise be infeasible, including vision models used for face recognition, person re-identification and NLP models that may require unlearning samples identified for exclusion. Code can be found at https://github.com/vsingh-group/LCODEC-deep-unlearning/
Equivariance Allows Handling Multiple Nuisance Variables When Analyzing Pooled Neuroimaging Datasets
Mar 29, 2022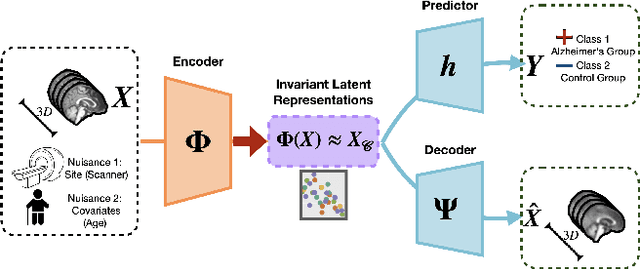

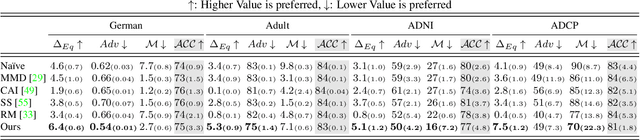
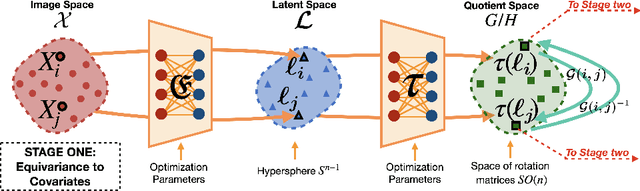
Pooling multiple neuroimaging datasets across institutions often enables improvements in statistical power when evaluating associations (e.g., between risk factors and disease outcomes) that may otherwise be too weak to detect. When there is only a {\em single} source of variability (e.g., different scanners), domain adaptation and matching the distributions of representations may suffice in many scenarios. But in the presence of {\em more than one} nuisance variable which concurrently influence the measurements, pooling datasets poses unique challenges, e.g., variations in the data can come from both the acquisition method as well as the demographics of participants (gender, age). Invariant representation learning, by itself, is ill-suited to fully model the data generation process. In this paper, we show how bringing recent results on equivariant representation learning (for studying symmetries in neural networks) instantiated on structured spaces together with simple use of classical results on causal inference provides an effective practical solution. In particular, we demonstrate how our model allows dealing with more than one nuisance variable under some assumptions and can enable analysis of pooled scientific datasets in scenarios that would otherwise entail removing a large portion of the samples.
Graph Reparameterizations for Enabling 1000+ Monte Carlo Iterations in Bayesian Deep Neural Networks
Feb 19, 2022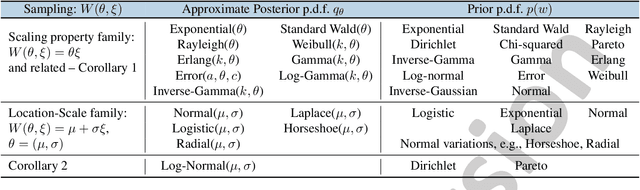
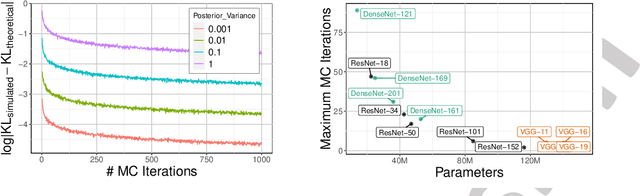
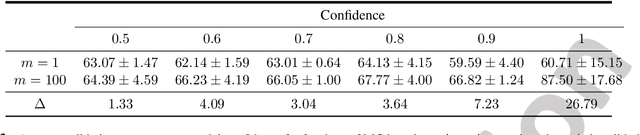

Uncertainty estimation in deep models is essential in many real-world applications and has benefited from developments over the last several years. Recent evidence suggests that existing solutions dependent on simple Gaussian formulations may not be sufficient. However, moving to other distributions necessitates Monte Carlo (MC) sampling to estimate quantities such as the KL divergence: it could be expensive and scales poorly as the dimensions of both the input data and the model grow. This is directly related to the structure of the computation graph, which can grow linearly as a function of the number of MC samples needed. Here, we construct a framework to describe these computation graphs, and identify probability families where the graph size can be independent or only weakly dependent on the number of MC samples. These families correspond directly to large classes of distributions. Empirically, we can run a much larger number of iterations for MC approximations for larger architectures used in computer vision with gains in performance measured in confident accuracy, stability of training, memory and training time.
Mixed Effects Neural ODE: A Variational Approximation for Analyzing the Dynamics of Panel Data
Feb 18, 2022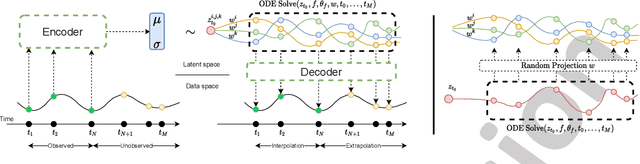
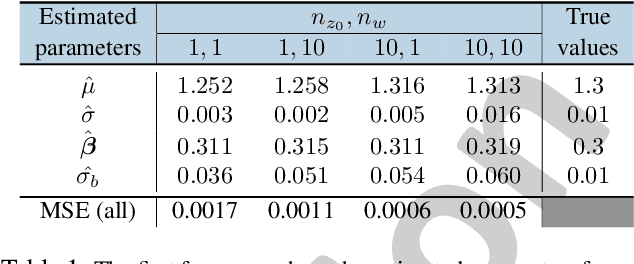
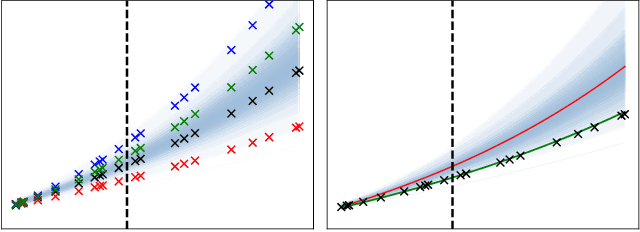
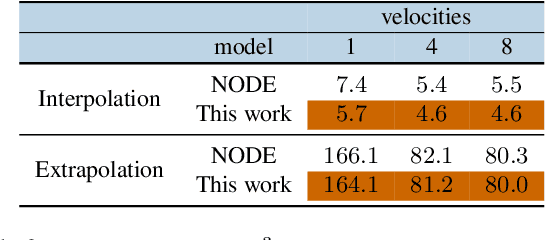
Panel data involving longitudinal measurements of the same set of participants taken over multiple time points is common in studies to understand childhood development and disease modeling. Deep hybrid models that marry the predictive power of neural networks with physical simulators such as differential equations, are starting to drive advances in such applications. The task of modeling not just the observations but the hidden dynamics that are captured by the measurements poses interesting statistical/computational questions. We propose a probabilistic model called ME-NODE to incorporate (fixed + random) mixed effects for analyzing such panel data. We show that our model can be derived using smooth approximations of SDEs provided by the Wong-Zakai theorem. We then derive Evidence Based Lower Bounds for ME-NODE, and develop (efficient) training algorithms using MC based sampling methods and numerical ODE solvers. We demonstrate ME-NODE's utility on tasks spanning the spectrum from simulations and toy data to real longitudinal 3D imaging data from an Alzheimer's disease (AD) study, and study its performance in terms of accuracy of reconstruction for interpolation, uncertainty estimates and personalized prediction.
Forward Operator Estimation in Generative Models with Kernel Transfer Operators
Dec 01, 2021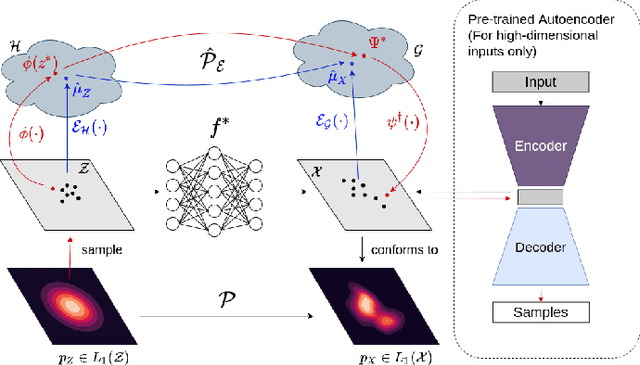
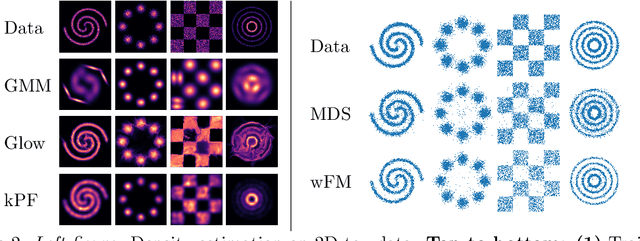

Generative models which use explicit density modeling (e.g., variational autoencoders, flow-based generative models) involve finding a mapping from a known distribution, e.g. Gaussian, to the unknown input distribution. This often requires searching over a class of non-linear functions (e.g., representable by a deep neural network). While effective in practice, the associated runtime/memory costs can increase rapidly, usually as a function of the performance desired in an application. We propose a much cheaper (and simpler) strategy to estimate this mapping based on adapting known results in kernel transfer operators. We show that our formulation enables highly efficient distribution approximation and sampling, and offers surprisingly good empirical performance that compares favorably with powerful baselines, but with significant runtime savings. We show that the algorithm also performs well in small sample size settings (in brain imaging).
You Only Sample Once: Linear Cost Self-Attention Via Bernoulli Sampling
Nov 18, 2021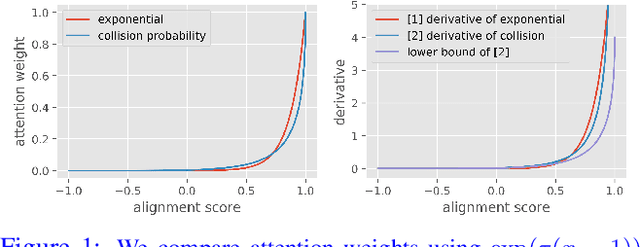


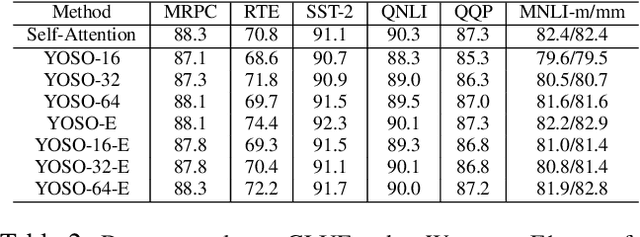
Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear. We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant). This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark, for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at https://github.com/mlpen/YOSO
Neural TMDlayer: Modeling Instantaneous flow of features via SDE Generators
Aug 19, 2021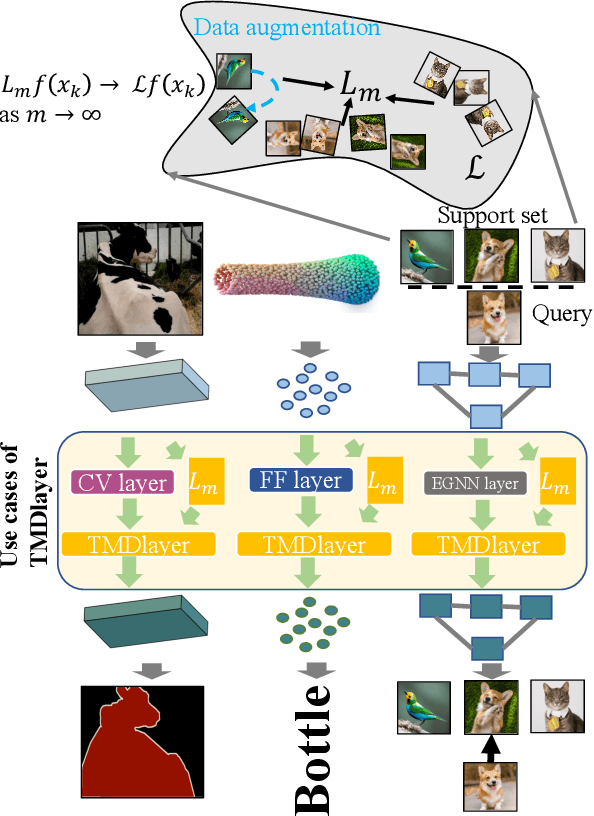

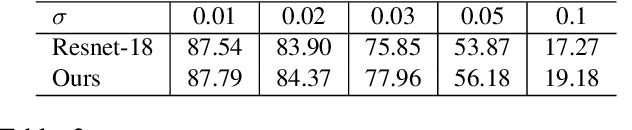

We study how stochastic differential equation (SDE) based ideas can inspire new modifications to existing algorithms for a set of problems in computer vision. Loosely speaking, our formulation is related to both explicit and implicit strategies for data augmentation and group equivariance, but is derived from new results in the SDE literature on estimating infinitesimal generators of a class of stochastic processes. If and when there is nominal agreement between the needs of an application/task and the inherent properties and behavior of the types of processes that we can efficiently handle, we obtain a very simple and efficient plug-in layer that can be incorporated within any existing network architecture, with minimal modification and only a few additional parameters. We show promising experiments on a number of vision tasks including few shot learning, point cloud transformers and deep variational segmentation obtaining efficiency or performance improvements.