 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dependency Networks for Multi-Label Classification
Feb 06, 2023



We propose a simple approach which combines the strengths of probabilistic graphical models and deep learning architectures for solving the multi-label classification task, focusing specifically on image and video data. First, we show that the performance of previous approaches that combine Markov Random Fields with neural networks can be modestly improved by leveraging more powerful methods such as iterative join graph propagation, integer linear programming, and $\ell_1$ regularization-based structure learning. Then we propose a new modeling framework called deep dependency networks, which augments a dependency network, a model that is easy to train and learns more accurate dependencies but is limited to Gibbs sampling for inference, to the output layer of a neural network. We show that despite its simplicity, jointly learning this new architecture yields significant improvements in performance over the baseline neural network. In particular, our experimental evaluation on three video activity classification datasets: Charades, Textually Annotated Cooking Scenes (TACoS), and Wetlab, and three multi-label image classification datasets: MS-COCO, PASCAL VOC, and NUS-WIDE show that deep dependency networks are almost always superior to pure neural architectures that do not use dependency networks.
Don't Explain without Verifying Veracity: An Evaluation of Explainable AI with Video Activity Recognition
May 05, 2020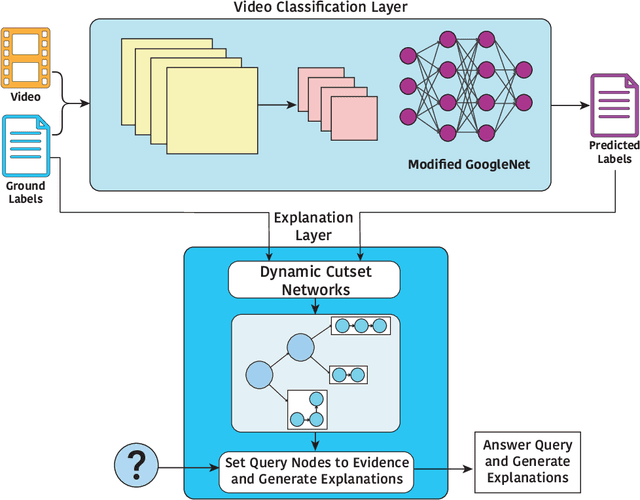
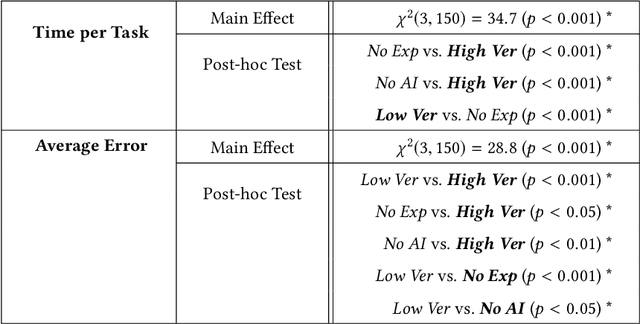

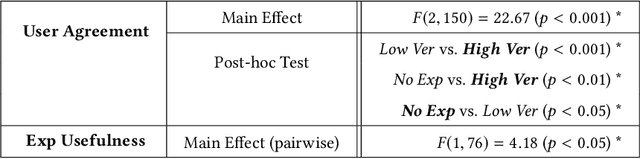
Explainable machine learning and artificial intelligence models have been used to justify a model's decision-making process. This added transparency aims to help improve user performance and understanding of the underlying model. However, in practice, explainable systems face many open questions and challenges. Specifically, designers might reduce the complexity of deep learning models in order to provide interpretability. The explanations generated by these simplified models, however, might not accurately justify and be truthful to the model. This can further add confusion to the users as they might not find the explanations meaningful with respect to the model predictions. Understanding how these explanations affect user behavior is an ongoing challenge. In this paper, we explore how explanation veracity affects user performance and agreement in intelligent systems. Through a controlled user study with an explainable activity recognition system, we compare variations in explanation veracity for a video review and querying task. The results suggest that low veracity explanations significantly decrease user performance and agreement compared to both accurate explanations and a system without explanations. These findings demonstrate the importance of accurate and understandable explanations and caution that poor explanations can sometimes be worse than no explanations with respect to their effect on user performance and reliance on an AI system.
Lifted Marginal MAP Inference
Jul 08, 2018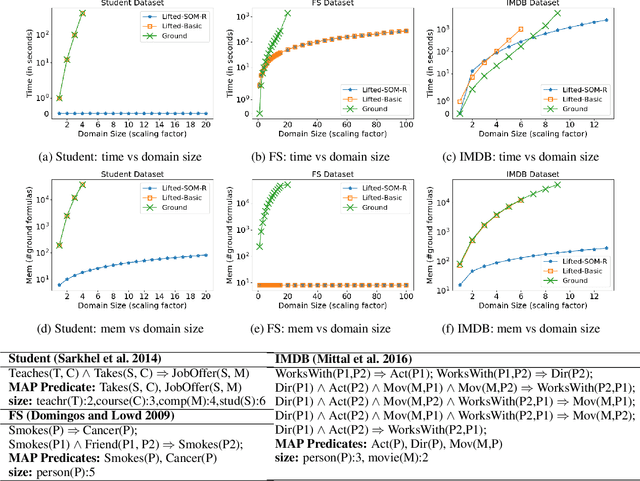
Lifted inference reduces the complexity of inference in relational probabilistic models by identifying groups of constants (or atoms) which behave symmetric to each other. A number of techniques have been proposed in the literature for lifting marginal as well MAP inference. We present the first application of lifting rules for marginal-MAP (MMAP), an important inference problem in models having latent (random) variables. Our main contribution is two fold: (1) we define a new equivalence class of (logical) variables, called Single Occurrence for MAX (SOM), and show that solution lies at extreme with respect to the SOM variables, i.e., predicate groundings differing only in the instantiation of the SOM variables take the same truth value (2) we define a sub-class {\em SOM-R} (SOM Reduce) and exploit properties of extreme assignments to show that MMAP inference can be performed by reducing the domain of SOM-R variables to a single constant.We refer to our lifting technique as the {\em SOM-R} rule for lifted MMAP. Combined with existing rules such as decomposer and binomial, this results in a powerful framework for lifted MMAP. Experiments on three benchmark domains show significant gains in both time and memory compared to ground inference as well as lifted approaches not using SOM-R.
Domain Aware Markov Logic Networks
Jul 07, 2018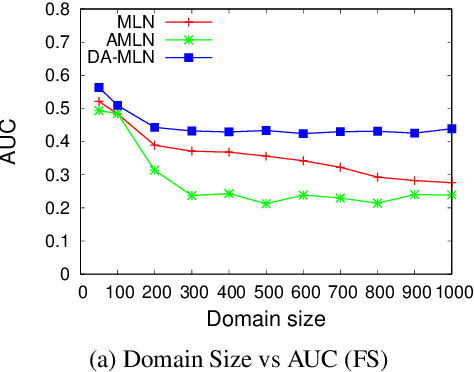
Combining logic and probability has been a long stand- ing goal of AI research. Markov Logic Networks (MLNs) achieve this by attaching weights to formulas in first-order logic, and can be seen as templates for constructing features for ground Markov networks. Most techniques for learning weights of MLNs are domain-size agnostic, i.e., the size of the domain is not explicitly taken into account while learn- ing the parameters of the model. This often results in ex- treme probabilities when testing on domain sizes different from those seen during training. In this paper, we propose Domain Aware Markov logic Networks (DA-MLNs) which present a principled solution to this problem. While defin- ing the ground network distribution, DA-MLNs divide the ground feature weight by a scaling factor which is a function of the number of connections the ground atoms appearing in the feature are involved in. We show that standard MLNs fall out as a special case of our formalism when this func- tion evaluates to a constant equal to 1. Experiments on the benchmark Friends & Smokers domain show that our ap- proach results in significantly higher accuracies compared to existing methods when testing on domains whose sizes different from those seen during training.
Scalable Neural Network Compression and Pruning Using Hard Clustering and L1 Regularization
Jun 14, 2018
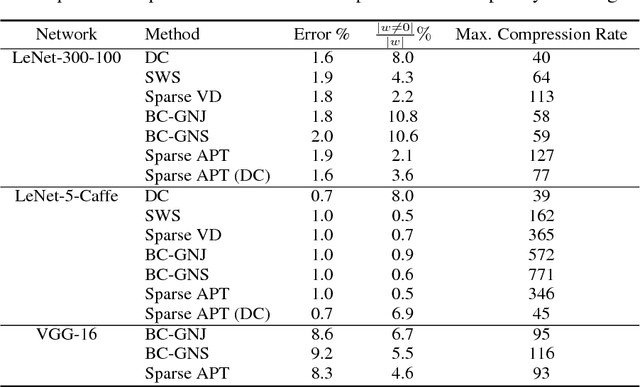
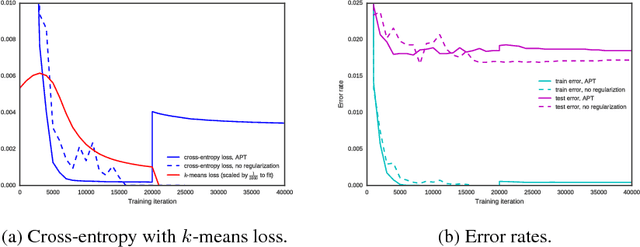
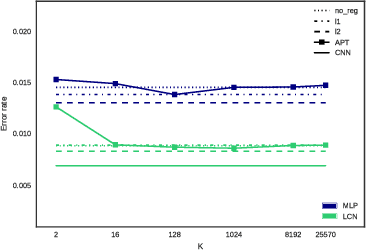
We propose a simple and easy to implement neural network compression algorithm that achieves results competitive with more complicated state-of-the-art methods. The key idea is to modify the original optimization problem by adding K independent Gaussian priors (corresponding to the k-means objective) over the network parameters to achieve parameter quantization, as well as an L1 penalty to achieve pruning. Unlike many existing quantization-based methods, our method uses hard clustering assignments of network parameters, which adds minimal change or overhead to standard network training. We also demonstrate experimentally that tying neural network parameters provides less gain in generalization performance than changing network architecture and connectivity patterns entirely.
Lifted Region-Based Belief Propagation
Jun 30, 2016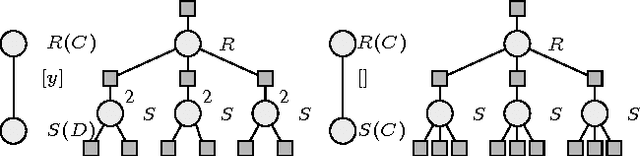
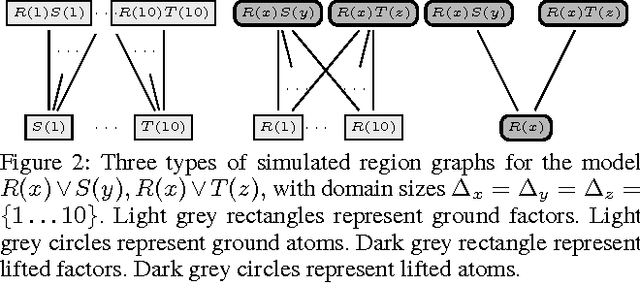
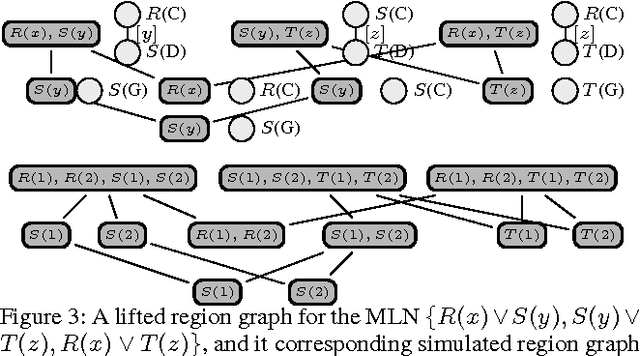
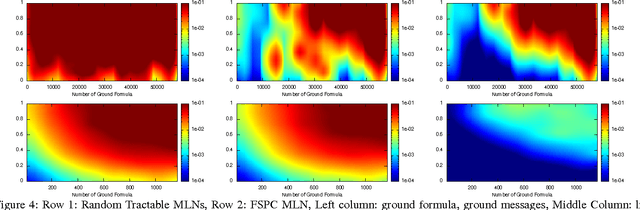
Due to the intractable nature of exact lifted inference, research has recently focused on the discovery of accurate and efficient approximate inference algorithms in Statistical Relational Models (SRMs), such as Lifted First-Order Belief Propagation. FOBP simulates propositional factor graph belief propagation without constructing the ground factor graph by identifying and lifting over redundant message computations. In this work, we propose a generalization of FOBP called Lifted Generalized Belief Propagation, in which both the region structure and the message structure can be lifted. This approach allows more of the inference to be performed intra-region (in the exact inference step of BP), thereby allowing simulation of propagation on a graph structure with larger region scopes and fewer edges, while still maintaining tractability. We demonstrate that the resulting algorithm converges in fewer iterations to more accurate results on a variety of SRMs.
Probabilistic Inference Modulo Theories
May 27, 2016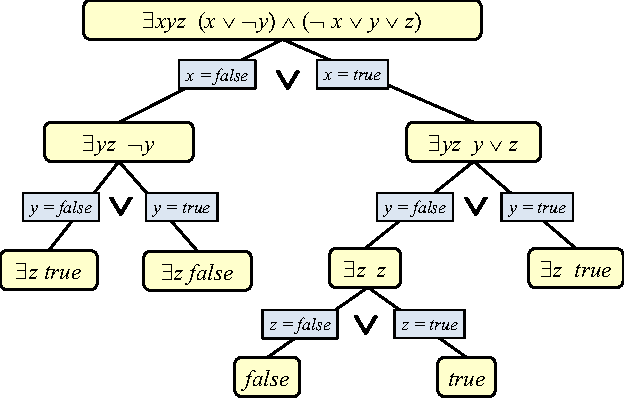
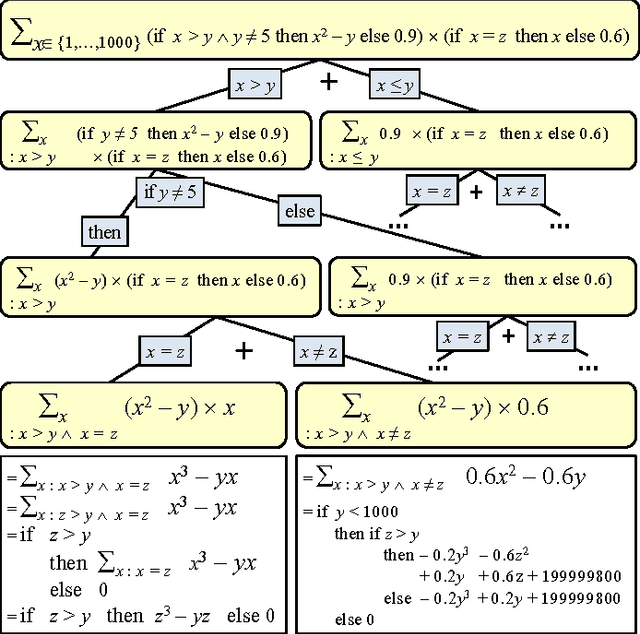
We present SGDPLL(T), an algorithm that solves (among many other problems) probabilistic inference modulo theories, that is, inference problems over probabilistic models defined via a logic theory provided as a parameter (currently, propositional, equalities on discrete sorts, and inequalities, more specifically difference arithmetic, on bounded integers). While many solutions to probabilistic inference over logic representations have been proposed, SGDPLL(T) is simultaneously (1) lifted, (2) exact and (3) modulo theories, that is, parameterized by a background logic theory. This offers a foundation for extending it to rich logic languages such as data structures and relational data. By lifted, we mean algorithms with constant complexity in the domain size (the number of values that variables can take). We also detail a solver for summations with difference arithmetic and show experimental results from a scenario in which SGDPLL(T) is much faster than a state-of-the-art probabilistic solver.
Join-Graph Propagation Algorithms
Jan 15, 2014
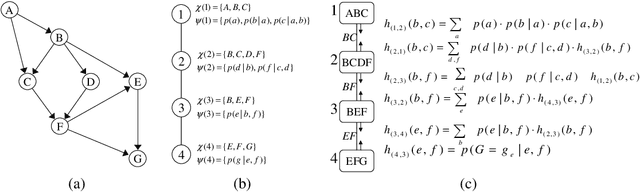
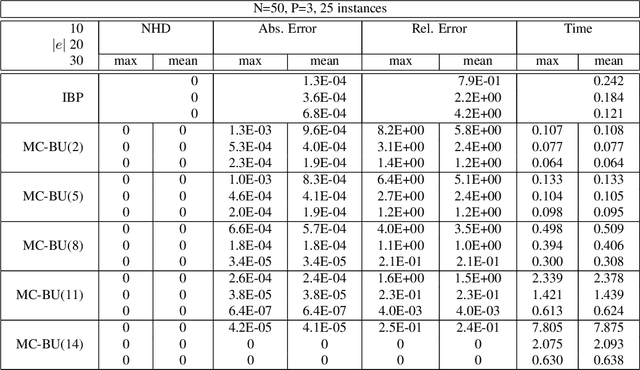
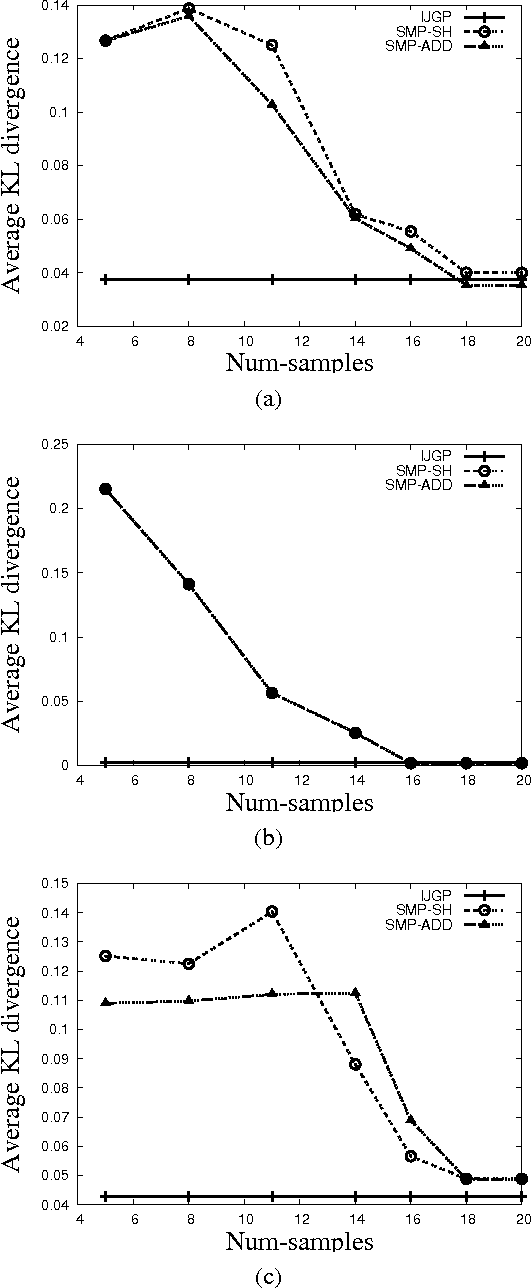
The paper investigates parameterized approximate message-passing schemes that are based on bounded inference and are inspired by Pearl's belief propagation algorithm (BP). We start with the bounded inference mini-clustering algorithm and then move to the iterative scheme called Iterative Join-Graph Propagation (IJGP), that combines both iteration and bounded inference. Algorithm IJGP belongs to the class of Generalized Belief Propagation algorithms, a framework that allowed connections with approximate algorithms from statistical physics and is shown empirically to surpass the performance of mini-clustering and belief propagation, as well as a number of other state-of-the-art algorithms on several classes of networks. We also provide insight into the accuracy of iterative BP and IJGP by relating these algorithms to well known classes of constraint propagation schemes.
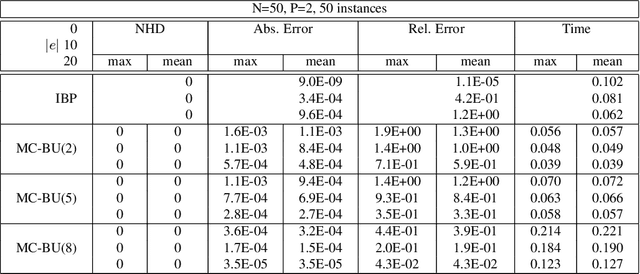
Dynamic Blocking and Collapsing for Gibbs Sampling
Sep 26, 2013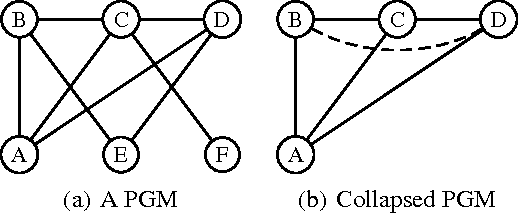
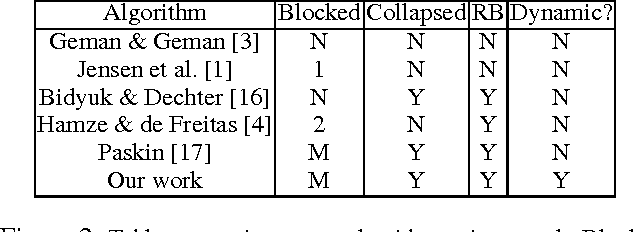
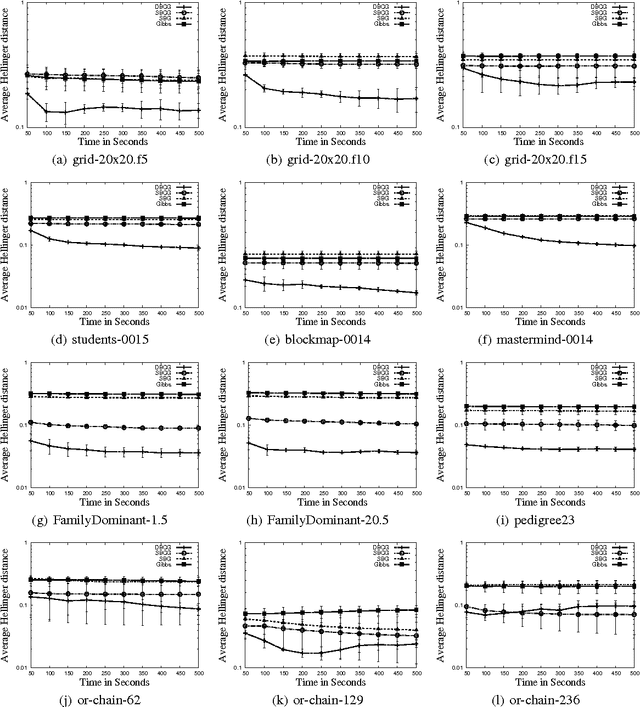
In this paper, we investigate combining blocking and collapsing -- two widely used strategies for improving the accuracy of Gibbs sampling -- in the context of probabilistic graphical models (PGMs). We show that combining them is not straight-forward because collapsing (or eliminating variables) introduces new dependencies in the PGM and in computation-limited settings, this may adversely affect blocking. We therefore propose a principled approach for tackling this problem. Specifically, we develop two scoring functions, one each for blocking and collapsing, and formulate the problem of partitioning the variables in the PGM into blocked and collapsed subsets as simultaneously maximizing both scoring functions (i.e., a multi-objective optimization problem). We propose a dynamic, greedy algorithm for approximately solving this intractable optimization problem. Our dynamic algorithm periodically updates the partitioning into blocked and collapsed variables by leveraging correlation statistics gathered from the generated samples and enables rapid mixing by blocking together and collapsing highly correlated variables. We demonstrate experimentally the clear benefit of our dynamic approach: as more samples are drawn, our dynamic approach significantly outperforms static graph-based approaches by an order of magnitude in terms of accuracy.
Structured Message Passing
Sep 26, 2013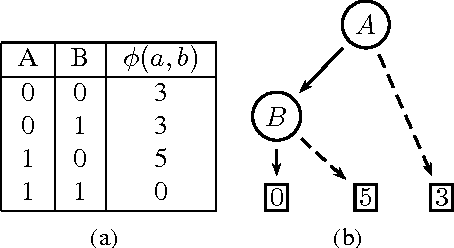
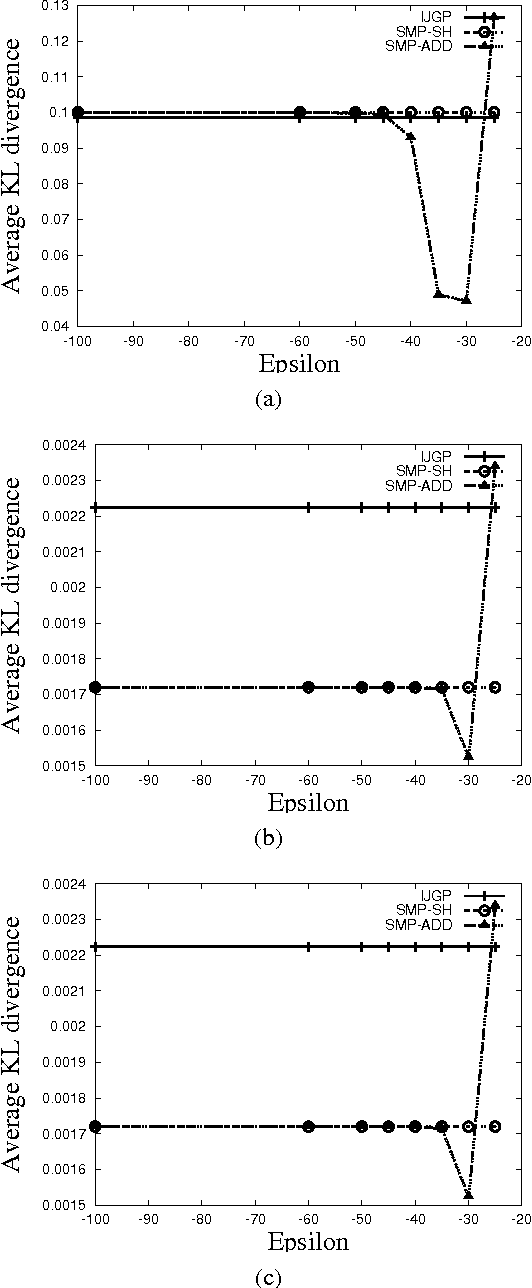
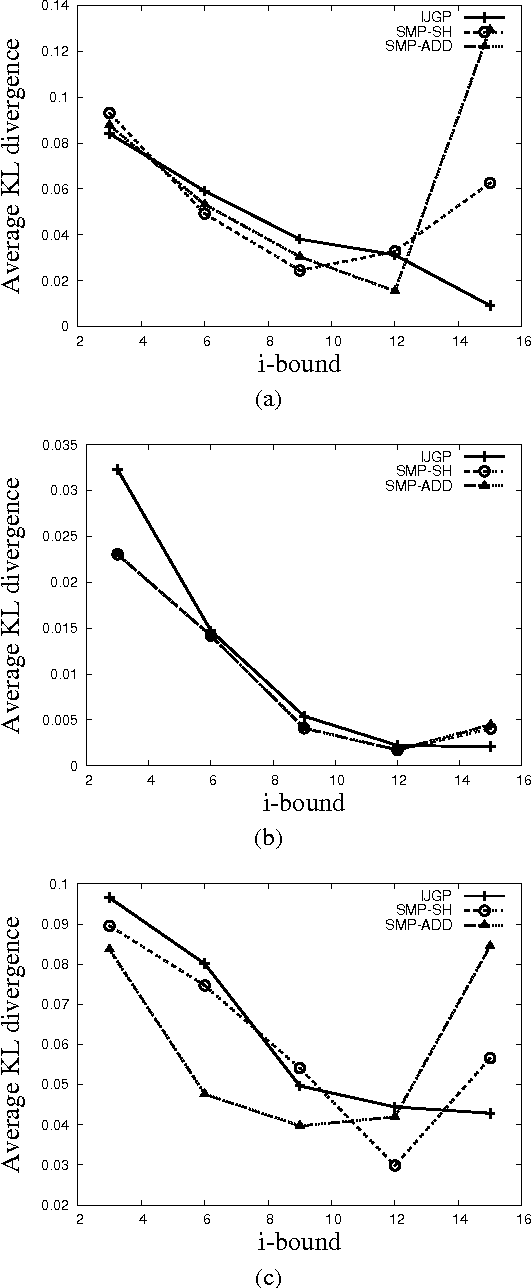
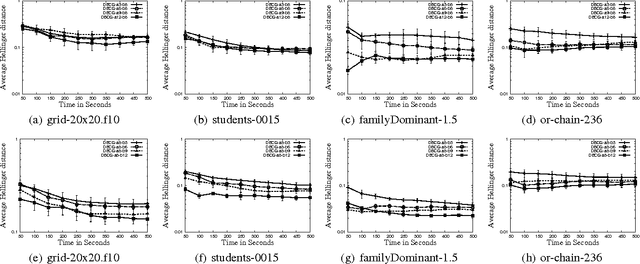
In this paper, we present structured message passing (SMP), a unifying framework for approximate inference algorithms that take advantage of structured representations such as algebraic decision diagrams and sparse hash tables. These representations can yield significant time and space savings over the conventional tabular representation when the message has several identical values (context-specific independence) or zeros (determinism) or both in its range. Therefore, in order to fully exploit the power of structured representations, we propose to artificially introduce context-specific independence and determinism in the messages. This yields a new class of powerful approximate inference algorithms which includes popular algorithms such as cluster-graph Belief propagation (BP), expectation propagation and particle BP as special cases. We show that our new algorithms introduce several interesting bias-variance trade-offs. We evaluate these trade-offs empirically and demonstrate that our new algorithms are more accurate and scalable than state-of-the-art techniques.