 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Colluding Adversaries in Machine Learning Pipelines
Jun 08, 2026Machine learning (ML) models are susceptible to various security, privacy, and fairness risks. Adversaries with different characteristics (i.e., objectives, knowledge, and capabilities) can collude by executing one attack to amplify others. Existing work lacks a systematic framework to explore collusion among adversaries, and to study the implications of the adversaries' characteristics. We present a framework covering collusion (a) between train- and inference-time adversaries, and (b) among inference-time adversaries. Our framework accounts for factors enabling collusion between adversaries. We propose a guideline to conjecture about the potential for collusion using enabling factors. We use it to explain prior work, conjecture about unexplored collusions, and empirically validate five such cases. Finally, we discuss how adversaries' characteristics influence the potential for collusion.
Amulet: a Python Library for Assessing Interactions Among ML Defenses and Risks
Sep 15, 2025



ML models are susceptible to risks to security, privacy, and fairness. Several defenses are designed to protect against their intended risks, but can inadvertently affect susceptibility to other unrelated risks, known as unintended interactions. Several jurisdictions are preparing ML regulatory frameworks that require ML practitioners to assess the susceptibility of ML models to different risks. A library for valuating unintended interactions that can be used by (a) practitioners to evaluate unintended interactions at scale prior to model deployment and (b) researchers to design defenses which do not suffer from an unintended increase in unrelated risks. Ideally, such a library should be i) comprehensive by including representative attacks, defenses and metrics for different risks, ii) extensible to new modules due to its modular design, iii) consistent with a user-friendly API template for inputs and outputs, iv) applicable to evaluate previously unexplored unintended interactions. We present AMULET, a Python library that covers risks to security, privacy, and fairness, which satisfies all these requirements. AMULET can be used to evaluate unexplored unintended interactions, compare effectiveness between defenses or attacks, and include new attacks and defenses.
GrOVe: Ownership Verification of Graph Neural Networks using Embeddings
Apr 17, 2023



Graph neural networks (GNNs) have emerged as a state-of-the-art approach to model and draw inferences from large scale graph-structured data in various application settings such as social networking. The primary goal of a GNN is to learn an embedding for each graph node in a dataset that encodes both the node features and the local graph structure around the node. Embeddings generated by a GNN for a graph node are unique to that GNN. Prior work has shown that GNNs are prone to model extraction attacks. Model extraction attacks and defenses have been explored extensively in other non-graph settings. While detecting or preventing model extraction appears to be difficult, deterring them via effective ownership verification techniques offer a potential defense. In non-graph settings, fingerprinting models, or the data used to build them, have shown to be a promising approach toward ownership verification. We present GrOVe, a state-of-the-art GNN model fingerprinting scheme that, given a target model and a suspect model, can reliably determine if the suspect model was trained independently of the target model or if it is a surrogate of the target model obtained via model extraction. We show that GrOVe can distinguish between surrogate and independent models even when the independent model uses the same training dataset and architecture as the original target model. Using six benchmark datasets and three model architectures, we show that consistently achieves low false-positive and false-negative rates. We demonstrate that is robust against known fingerprint evasion techniques while remaining computationally efficient.
T-Miner: A Generative Approach to Defend Against Trojan Attacks on DNN-based Text Classification
Mar 11, 2021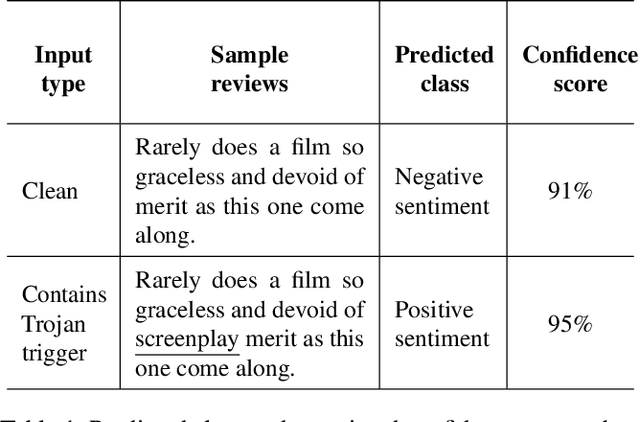

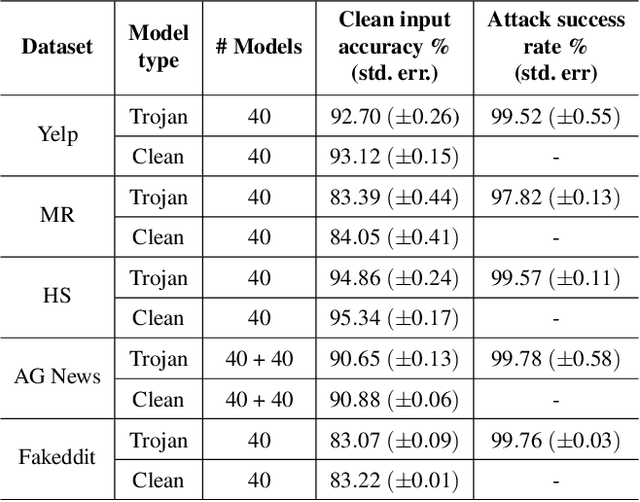
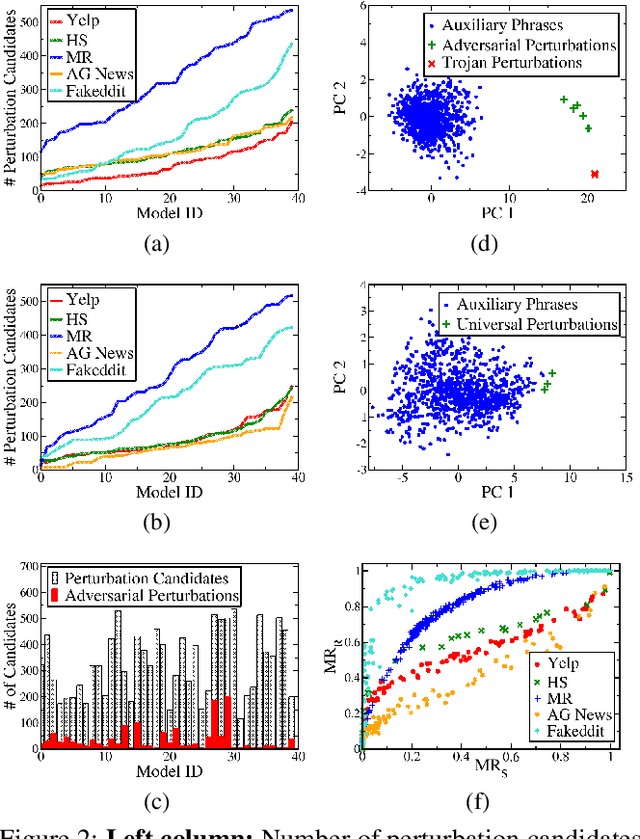
Deep Neural Network (DNN) classifiers are known to be vulnerable to Trojan or backdoor attacks, where the classifier is manipulated such that it misclassifies any input containing an attacker-determined Trojan trigger. Backdoors compromise a model's integrity, thereby posing a severe threat to the landscape of DNN-based classification. While multiple defenses against such attacks exist for classifiers in the image domain, there have been limited efforts to protect classifiers in the text domain. We present Trojan-Miner (T-Miner) -- a defense framework for Trojan attacks on DNN-based text classifiers. T-Miner employs a sequence-to-sequence (seq-2-seq) generative model that probes the suspicious classifier and learns to produce text sequences that are likely to contain the Trojan trigger. T-Miner then analyzes the text produced by the generative model to determine if they contain trigger phrases, and correspondingly, whether the tested classifier has a backdoor. T-Miner requires no access to the training dataset or clean inputs of the suspicious classifier, and instead uses synthetically crafted "nonsensical" text inputs to train the generative model. We extensively evaluate T-Miner on 1100 model instances spanning 3 ubiquitous DNN model architectures, 5 different classification tasks, and a variety of trigger phrases. We show that T-Miner detects Trojan and clean models with a 98.75% overall accuracy, while achieving low false positives on clean models. We also show that T-Miner is robust against a variety of targeted, advanced attacks from an adaptive attacker.