 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAug: Data Augmentation for Finetuning Text Generators
Oct 10, 2020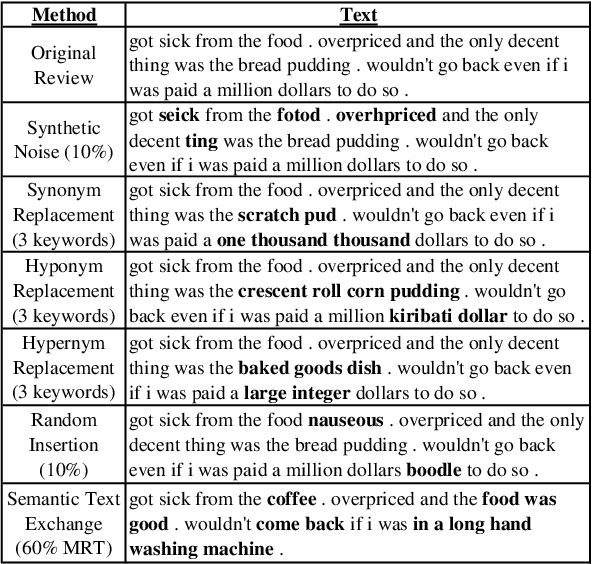
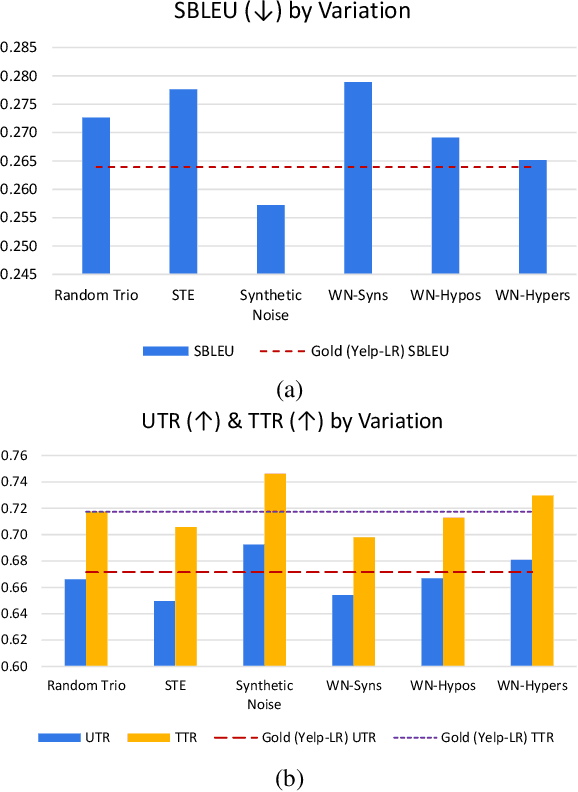
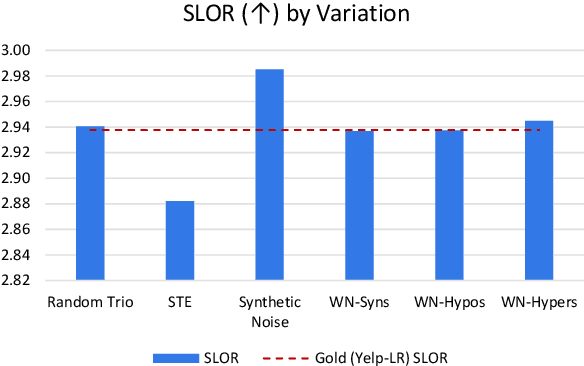
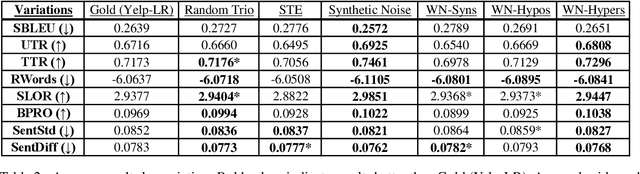
In this paper, we investigate data augmentation for text generation, which we call GenAug. Text generation and language modeling are important tasks within natural language processing, and are especially challenging for low-data regimes. We propose and evaluate various augmentation methods, including some that incorporate external knowledge, for finetuning GPT-2 on a subset of Yelp Reviews. We also examine the relationship between the amount of augmentation and the quality of the generated text. We utilize several metrics that evaluate important aspects of the generated text including its diversity and fluency. Our experiments demonstrate that insertion of character-level synthetic noise and keyword replacement with hypernyms are effective augmentation methods, and that the quality of generations improves to a peak at approximately three times the amount of original data.
BERTering RAMS: What and How Much does BERT Already Know About Event Arguments? -- A Study on the RAMS Dataset
Oct 09, 2020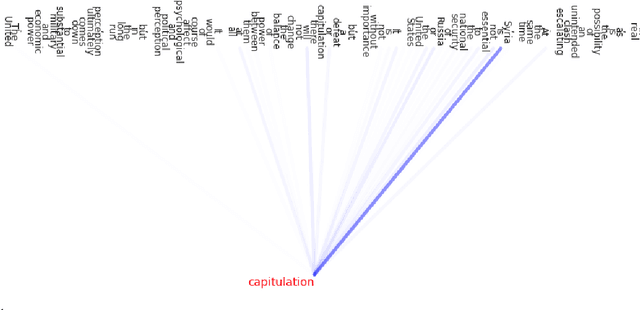
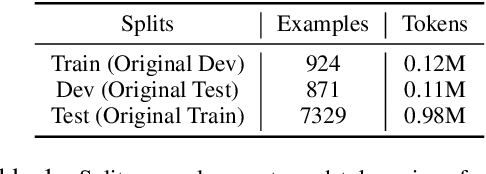
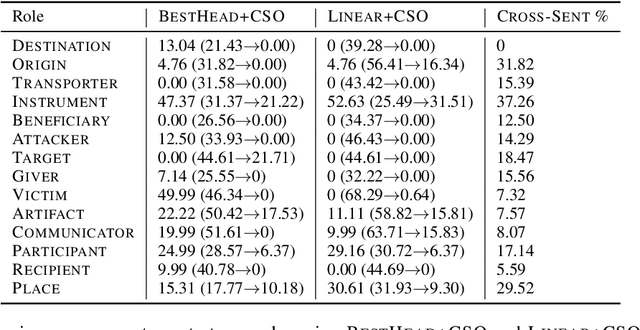
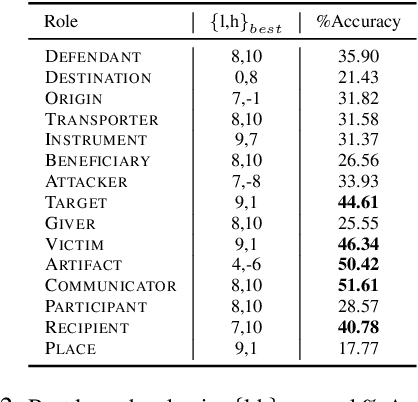
Using the attention map based probing frame-work from (Clark et al., 2019), we observe that, on the RAMS dataset (Ebner et al., 2020), BERT's attention heads have modest but well above-chance ability to spot event arguments sans any training or domain finetuning, vary-ing from a low of 17.77% for Place to a high of 51.61% for Artifact. Next, we find that linear combinations of these heads, estimated with approx 11% of available total event argument detection supervision, can push performance well-higher for some roles - highest two being Victim (68.29% Accuracy) and Artifact(58.82% Accuracy). Furthermore, we investigate how well our methods do for cross-sentence event arguments. We propose a procedure to isolate "best heads" for cross-sentence argument detection separately of those for intra-sentence arguments. The heads thus estimated have superior cross-sentence performance compared to their jointly estimated equivalents, albeit only under the unrealistic assumption that we already know the argument is present in an-other sentence. Lastly, we seek to isolate to what extent our numbers stem from lexical frequency based associations between gold arguments and roles. We propose NONCE, a scheme to create adversarial test examples by replacing gold arguments with randomly generated "nonce" words. We find that learnt linear combinations are robust to NONCE, though individual best heads can be more sensitive.
SCDE: Sentence Cloze Dataset with High Quality Distractors From Examinations
Apr 27, 2020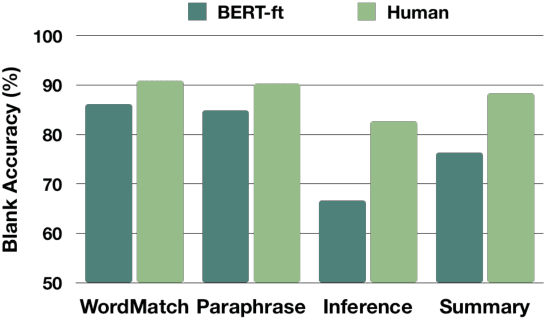
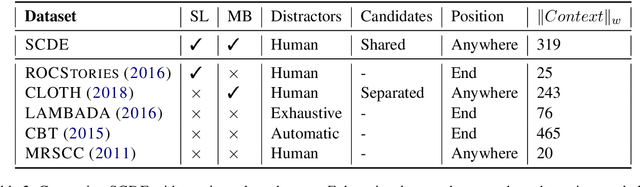
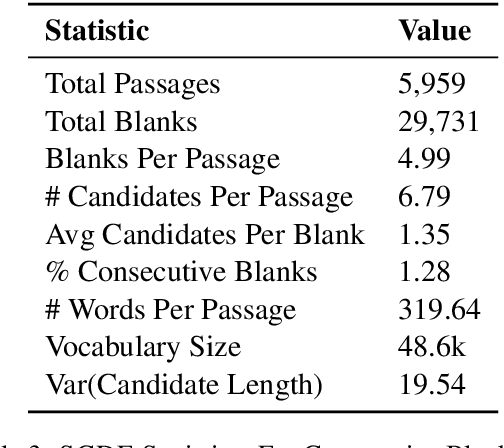
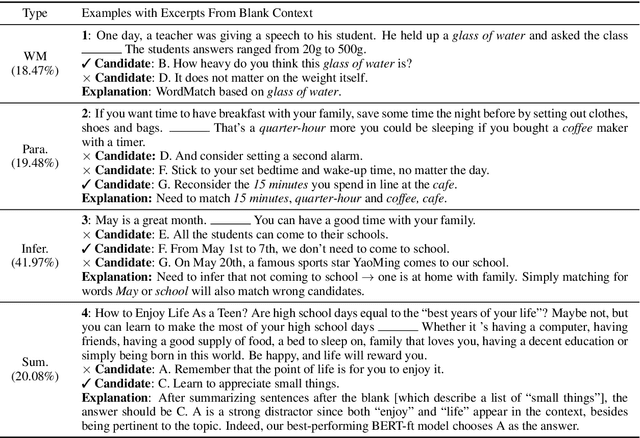
We introduce SCDE, a dataset to evaluate the performance of computational models through sentence prediction. SCDE is a human-created sentence cloze dataset, collected from public school English examinations. Our task requires a model to fill up multiple blanks in a passage from a shared candidate set with distractors designed by English teachers. Experimental results demonstrate that this task requires the use of non-local, discourse-level context beyond the immediate sentence neighborhood. The blanks require joint solving and significantly impair each other's context. Furthermore, through ablations, we show that the distractors are of high quality and make the task more challenging. Our experiments show that there is a significant performance gap between advanced models (72%) and humans (87%), encouraging future models to bridge this gap.
Likelihood Ratios and Generative Classifiers for Unsupervised Out-of-Domain Detection In Task Oriented Dialog
Dec 30, 2019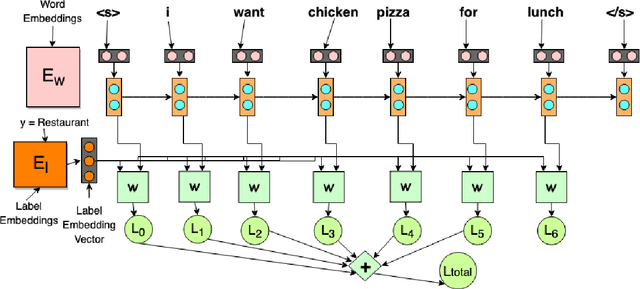

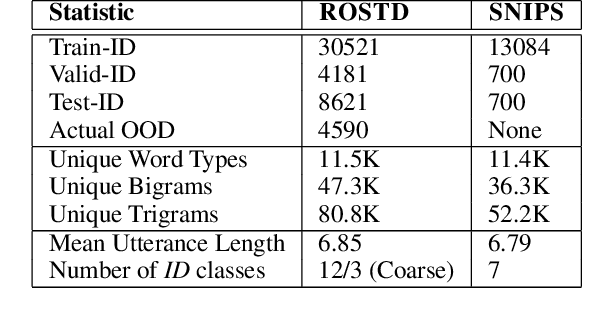
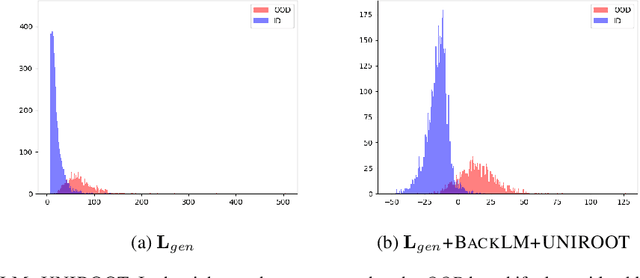
The task of identifying out-of-domain (OOD) input examples directly at test-time has seen renewed interest recently due to increased real world deployment of models. In this work, we focus on OOD detection for natural language sentence inputs to task-based dialog systems. Our findings are three-fold: First, we curate and release ROSTD (Real Out-of-Domain Sentences From Task-oriented Dialog) - a dataset of 4K OOD examples for the publicly available dataset from (Schuster et al. 2019). In contrast to existing settings which synthesize OOD examples by holding out a subset of classes, our examples were authored by annotators with apriori instructions to be out-of-domain with respect to the sentences in an existing dataset. Second, we explore likelihood ratio based approaches as an alternative to currently prevalent paradigms. Specifically, we reformulate and apply these approaches to natural language inputs. We find that they match or outperform the latter on all datasets, with larger improvements on non-artificial OOD benchmarks such as our dataset. Our ablations validate that specifically using likelihood ratios rather than plain likelihood is necessary to discriminate well between OOD and in-domain data. Third, we propose learning a generative classifier and computing a marginal likelihood (ratio) for OOD detection. This allows us to use a principled likelihood while at the same time exploiting training-time labels. We find that this approach outperforms both simple likelihood (ratio) based and other prior approaches. We are hitherto the first to investigate the use of generative classifiers for OOD detection at test-time.
(Male, Bachelor) and (Female, Ph.D) have different connotations: Parallelly Annotated Stylistic Language Dataset with Multiple Personas
Aug 31, 2019
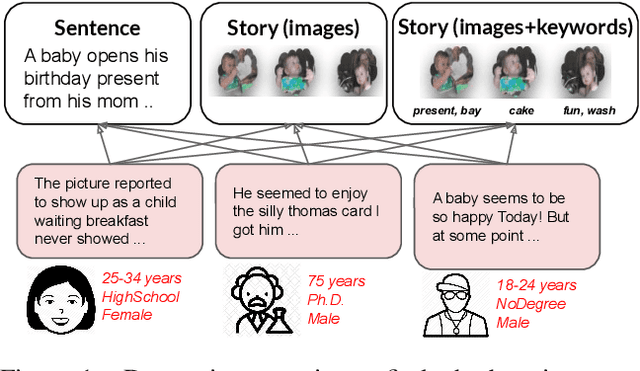
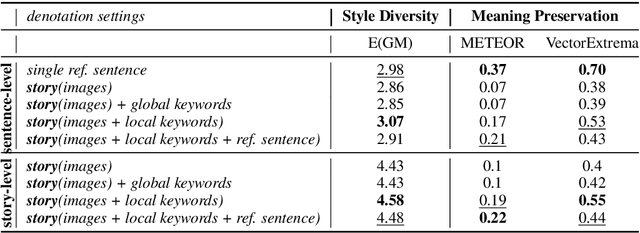

Stylistic variation in text needs to be studied with different aspects including the writer's personal traits, interpersonal relations, rhetoric, and more. Despite recent attempts on computational modeling of the variation, the lack of parallel corpora of style language makes it difficult to systematically control the stylistic change as well as evaluate such models. We release PASTEL, the parallel and annotated stylistic language dataset, that contains ~41K parallel sentences (8.3K parallel stories) annotated across different personas. Each persona has different styles in conjunction: gender, age, country, political view, education, ethnic, and time-of-writing. The dataset is collected from human annotators with solid control of input denotation: not only preserving original meaning between text, but promoting stylistic diversity to annotators. We test the dataset on two interesting applications of style language, where PASTEL helps design appropriate experiment and evaluation. First, in predicting a target style (e.g., male or female in gender) given a text, multiple styles of PASTEL make other external style variables controlled (or fixed), which is a more accurate experimental design. Second, a simple supervised model with our parallel text outperforms the unsupervised models using nonparallel text in style transfer. Our dataset is publicly available.
Detecting and Explaining Causes From Text For a Time Series Event
Jul 27, 2017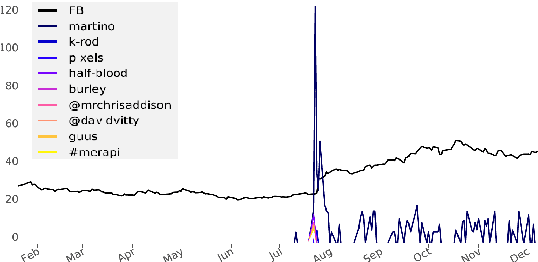
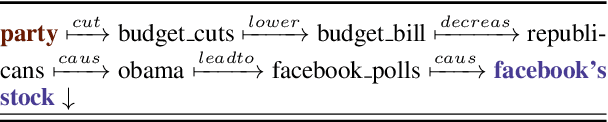
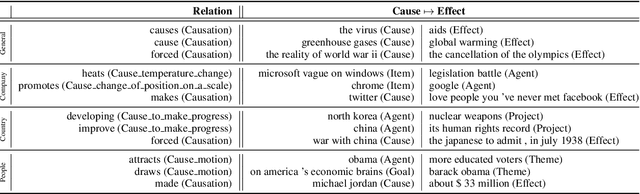
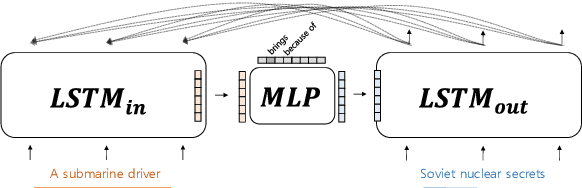
Explaining underlying causes or effects about events is a challenging but valuable task. We define a novel problem of generating explanations of a time series event by (1) searching cause and effect relationships of the time series with textual data and (2) constructing a connecting chain between them to generate an explanation. To detect causal features from text, we propose a novel method based on the Granger causality of time series between features extracted from text such as N-grams, topics, sentiments, and their composition. The generation of the sequence of causal entities requires a commonsense causative knowledge base with efficient reasoning. To ensure good interpretability and appropriate lexical usage we combine symbolic and neural representations, using a neural reasoning algorithm trained on commonsense causal tuples to predict the next cause step. Our quantitative and human analysis show empirical evidence that our method successfully extracts meaningful causality relationships between time series with textual features and generates appropriate explanation between them.
CharManteau: Character Embedding Models For Portmanteau Creation
Jul 24, 2017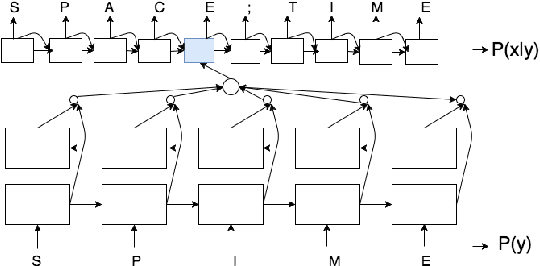
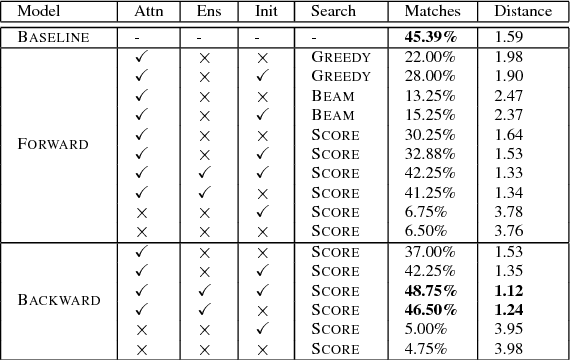
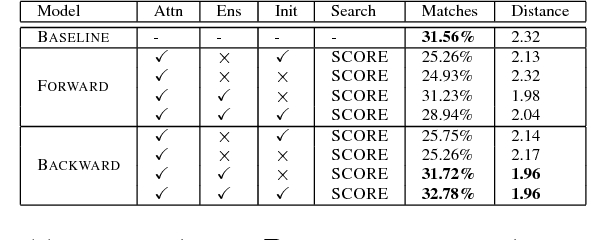

Portmanteaus are a word formation phenomenon where two words are combined to form a new word. We propose character-level neural sequence-to-sequence (S2S) methods for the task of portmanteau generation that are end-to-end-trainable, language independent, and do not explicitly use additional phonetic information. We propose a noisy-channel-style model, which allows for the incorporation of unsupervised word lists, improving performance over a standard source-to-target model. This model is made possible by an exhaustive candidate generation strategy specifically enabled by the features of the portmanteau task. Experiments find our approach superior to a state-of-the-art FST-based baseline with respect to ground truth accuracy and human evaluation.
Shakespearizing Modern Language Using Copy-Enriched Sequence-to-Sequence Models
Jul 20, 2017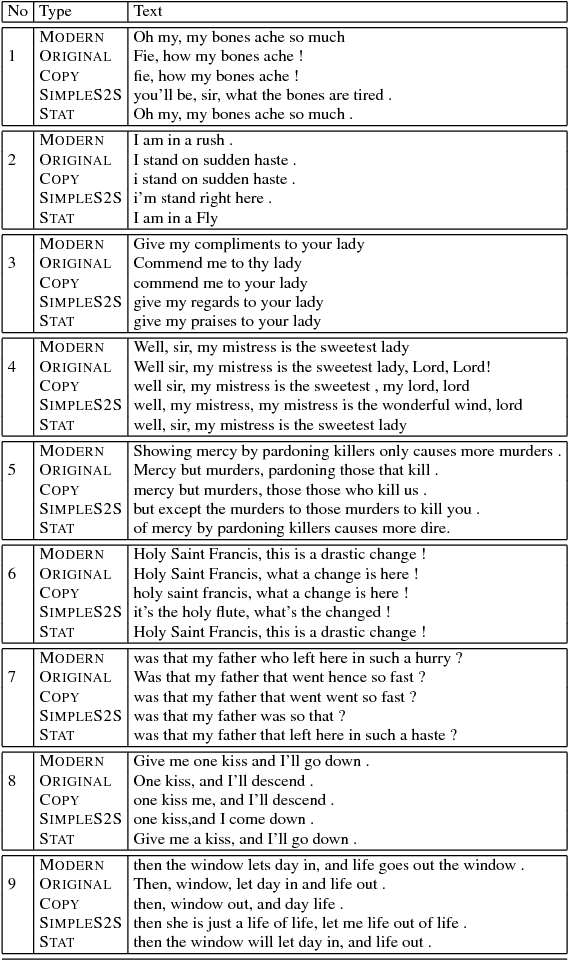
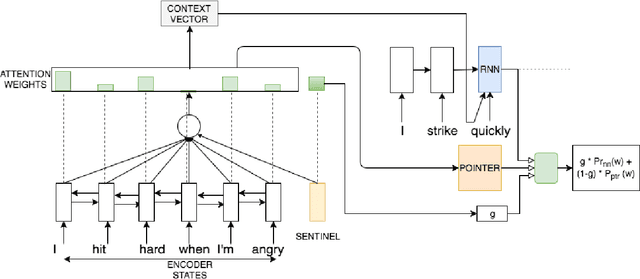
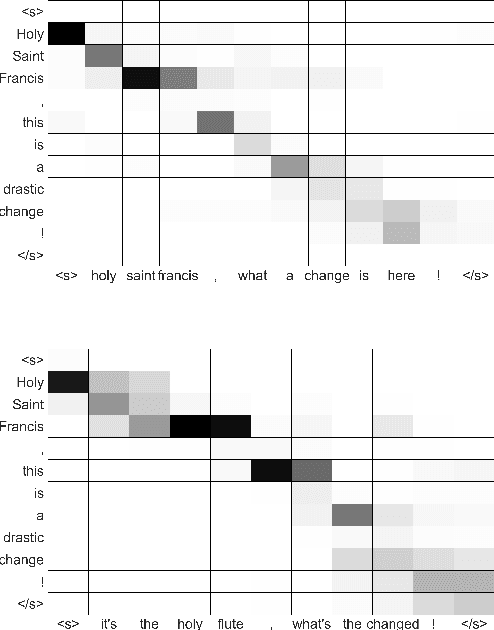
Variations in writing styles are commonly used to adapt the content to a specific context, audience, or purpose. However, applying stylistic variations is still by and large a manual process, and there have been little efforts towards automating it. In this paper we explore automated methods to transform text from modern English to Shakespearean English using an end to end trainable neural model with pointers to enable copy action. To tackle limited amount of parallel data, we pre-train embeddings of words by leveraging external dictionaries mapping Shakespearean words to modern English words as well as additional text. Our methods are able to get a BLEU score of 31+, an improvement of ~6 points above the strongest baseline. We publicly release our code to foster further research in this area.