 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Multi-Target Multi-Domain Recommender Systems with Assisted AutoEncoders
Oct 26, 2021
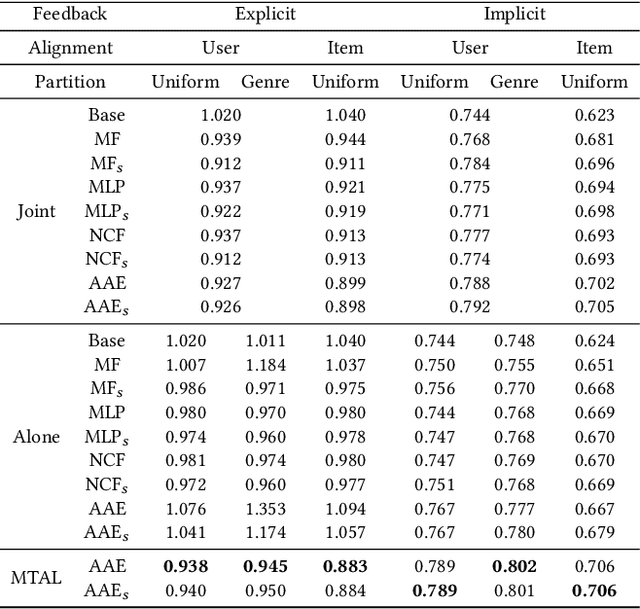
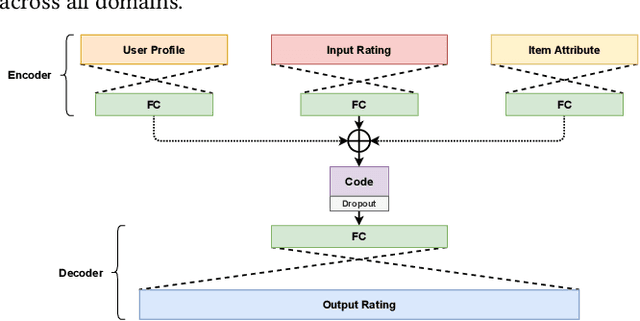
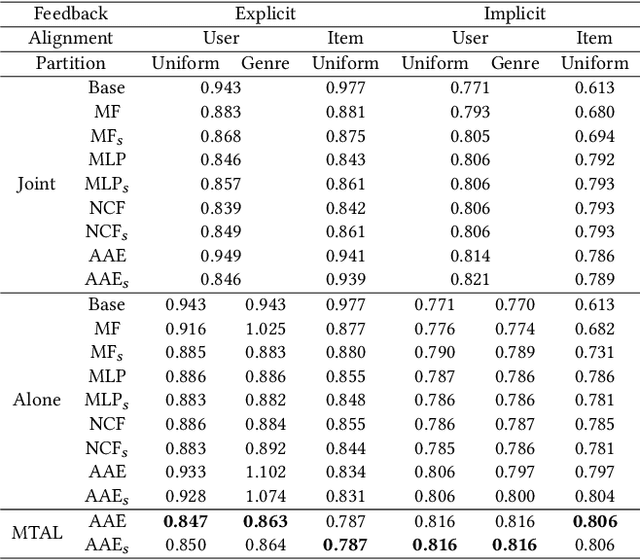
A long-standing challenge in Recommender Systems (RCs) is the data sparsity problem that often arises when users rate very few items. Multi-Target Multi-Domain Recommender Systems (MTMDR) aim to improve the recommendation performance in multiple domains simultaneously. The existing works assume that the data of different domains can be fully shared, and the computation can be performed in a centralized manner. However, in many realistic scenarios, separate recommender systems are operated by different organizations, which do not allow the sharing of private data, models, and recommendation tasks. This work proposes an MTMDR based on Assisted AutoEncoders (AAE) and Multi-Target Assisted Learning (MTAL) to help organizational learners improve their recommendation performance simultaneously without sharing sensitive assets. Moreover, AAE has a broad application scope since it allows explicit or implicit feedback, user- or item-based alignment, and with or without side information. Extensive experiments demonstrate that our method significantly outperforms the case where each domain is locally trained, and it performs competitively with the centralized training where all data are shared. As a result, AAE can effectively integrate organizations from different domains to form a community of shared interest.
Task Affinity with Maximum Bipartite Matching in Few-Shot Learning
Oct 05, 2021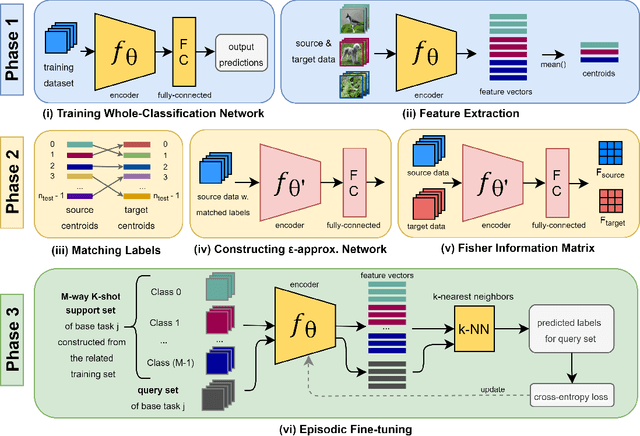
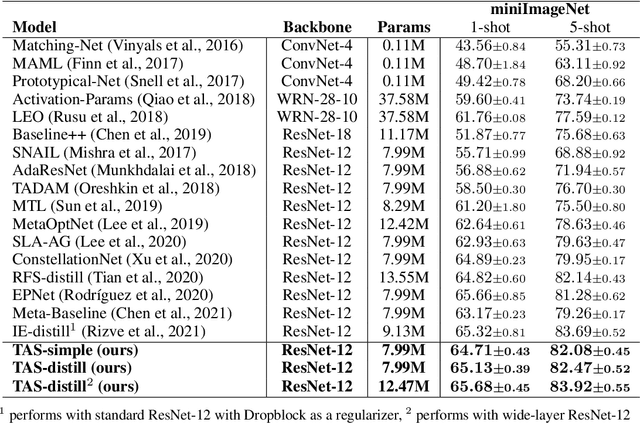
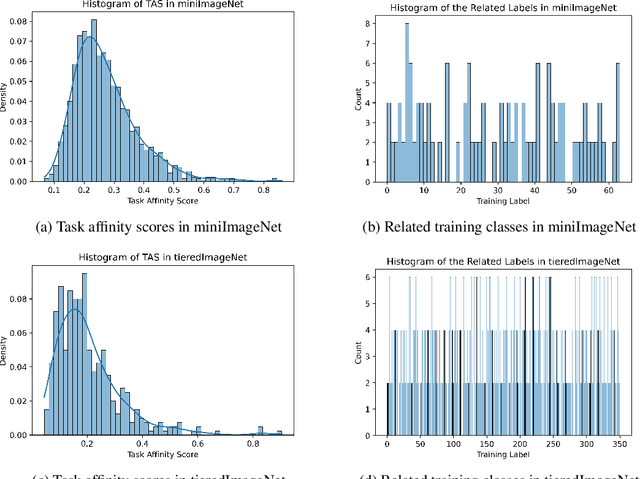
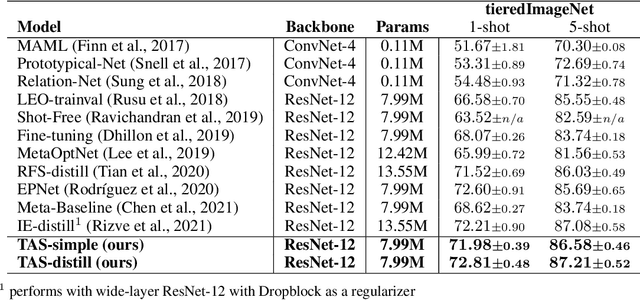
We propose an asymmetric affinity score for representing the complexity of utilizing the knowledge of one task for learning another one. Our method is based on the maximum bipartite matching algorithm and utilizes the Fisher Information matrix. We provide theoretical analyses demonstrating that the proposed score is mathematically well-defined, and subsequently use the affinity score to propose a novel algorithm for the few-shot learning problem. In particular, using this score, we find relevant training data labels to the test data and leverage the discovered relevant data for episodically fine-tuning a few-shot model. Results on various few-shot benchmark datasets demonstrate the efficacy of the proposed approach by improving the classification accuracy over the state-of-the-art methods even when using smaller models.
Semi-Empirical Objective Functions for MCMC Proposal Optimization
Jun 03, 2021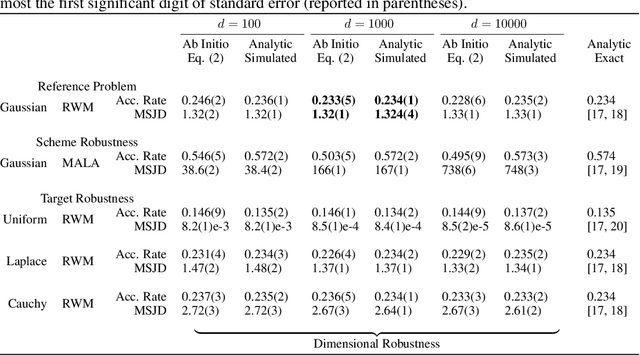
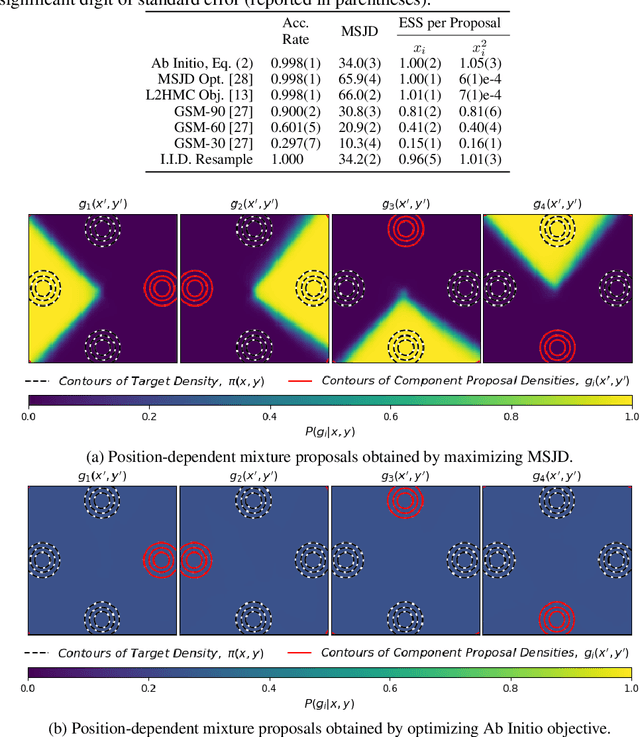
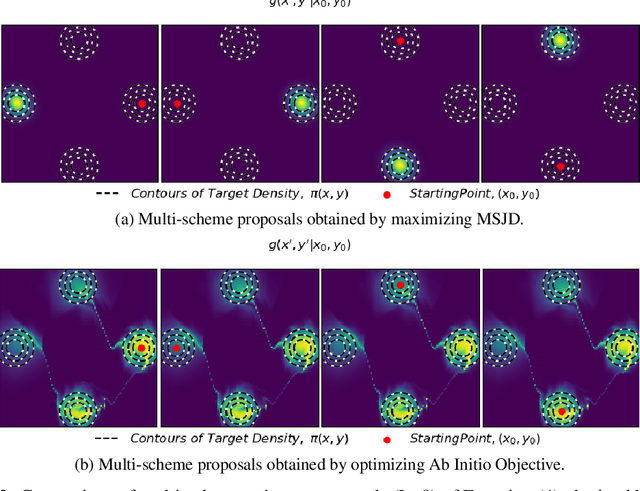
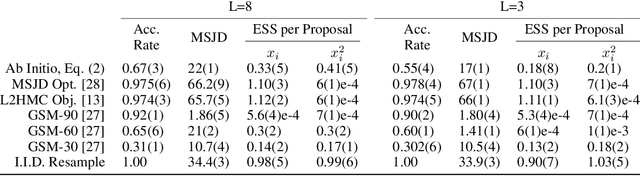
We introduce and demonstrate a semi-empirical procedure for determining approximate objective functions suitable for optimizing arbitrarily parameterized proposal distributions in MCMC methods. Our proposed Ab Initio objective functions consist of the weighted combination of functions following constraints on their global optima and of coordinate invariance that we argue should be upheld by general measures of MCMC efficiency for use in proposal optimization. The coefficients of Ab Initio objective functions are determined so as to recover the optimal MCMC behavior prescribed by established theoretical analysis for chosen reference problems. Our experimental results demonstrate that Ab Initio objective functions maintain favorable performance and preferable optimization behavior compared to existing objective functions for MCMC optimization when optimizing highly expressive proposal distributions. We argue that Ab Initio objective functions are sufficiently robust to enable the confident optimization of MCMC proposal distributions parameterized by deep generative networks that extend beyond the traditional limitations of individual MCMC schemes.
SemiFL: Communication Efficient Semi-Supervised Federated Learning with Unlabeled Clients
Jun 02, 2021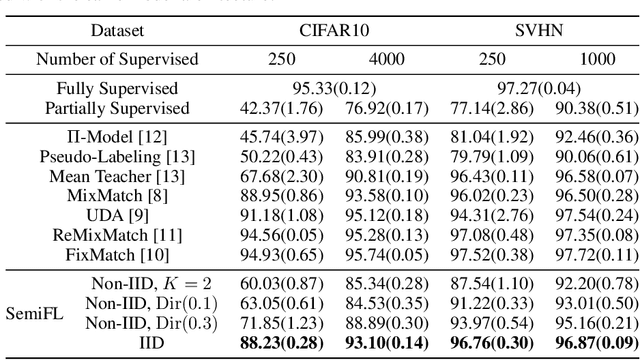

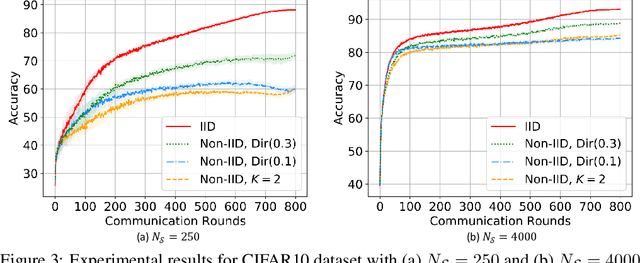
Federated Learning allows training machine learning models by using the computation and private data resources of a large number of distributed clients such as smartphones and IoT devices. Most existing works on Federated Learning (FL) assume the clients have ground-truth labels. However, in many practical scenarios, clients may be unable to label task-specific data, e.g., due to lack of expertise. In this work, we consider a server that hosts a labeled dataset, and wishes to leverage clients with unlabeled data for supervised learning. We propose a new Federated Learning framework referred to as SemiFL in order to address the problem of Semi-Supervised Federated Learning (SSFL). In SemiFL, clients have completely unlabeled data, while the server has a small amount of labeled data. SemiFL is communication efficient since it separates the training of server-side supervised data and client-side unsupervised data. We demonstrate various efficient strategies of SemiFL that enhance learning performance. Extensive empirical evaluations demonstrate that our communication efficient method can significantly improve the performance of a labeled server with unlabeled clients. Moreover, we demonstrate that SemiFL can outperform many existing FL results trained with fully supervised data, and perform competitively with the state-of-the-art centralized Semi-Supervised Learning (SSL) methods. For instance, in standard communication efficient scenarios, our method can perform 93% accuracy on the CIFAR10 dataset with only 4000 labeled samples at the server. Such accuracy is only 2% away from the result trained from 50000 fully labeled data, and it improves about 30% upon existing SSFL methods in the communication efficient setting.
Gradient Assisted Learning
Jun 02, 2021

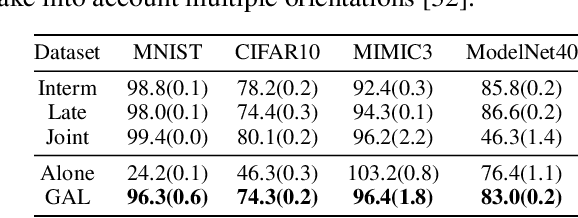
In distributed settings, collaborations between different entities, such as financial institutions, medical centers, and retail markets, are crucial to providing improved service and performance. However, the underlying entities may have little interest in sharing their private data, proprietary models, and objective functions. These privacy requirements have created new challenges for collaboration. In this work, we propose Gradient Assisted Learning (GAL), a new method for various entities to assist each other in supervised learning tasks without sharing data, models, and objective functions. In this framework, all participants collaboratively optimize the aggregate of local loss functions, and each participant autonomously builds its own model by iteratively fitting the gradients of the objective function. Experimental studies demonstrate that Gradient Assisted Learning can achieve performance close to centralized learning when all data, models, and objective functions are fully disclosed.
Towards Explainable Convolutional Features for Music Audio Modeling
May 31, 2021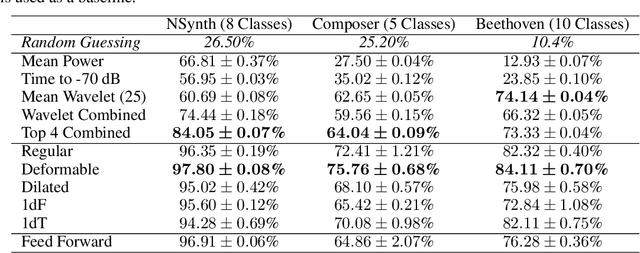
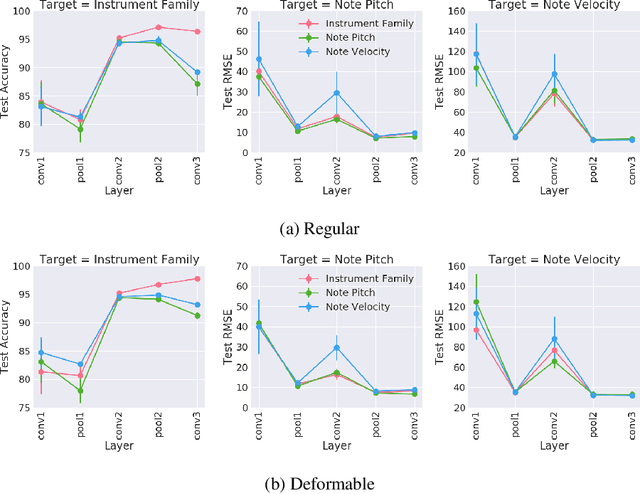

Audio signals are often represented as spectrograms and treated as 2D images. In this light, deep convolutional architectures are widely used for music audio tasks even though these two data types have very different structures. In this work, we attempt to "open the black-box" on deep convolutional models to inform future architectures for music audio tasks, and explain the excellent performance of deep convolutions that model spectrograms as 2D images. To this end, we expand recent explainability discussions in deep learning for natural image data to music audio data through systematic experiments using the deep features learned by various convolutional architectures. We demonstrate that deep convolutional features perform well across various target tasks, whether or not they are extracted from deep architectures originally trained on that task. Additionally, deep features exhibit high similarity to hand-crafted wavelet features, whether the deep features are extracted from a trained or untrained model.
Neural Architecture Search From Fréchet Task Distance
Mar 25, 2021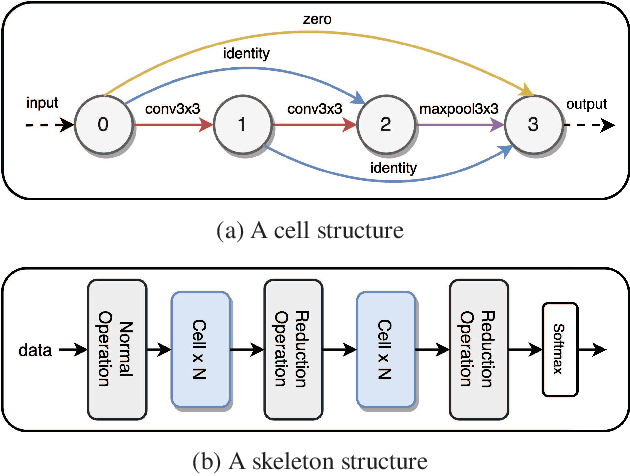
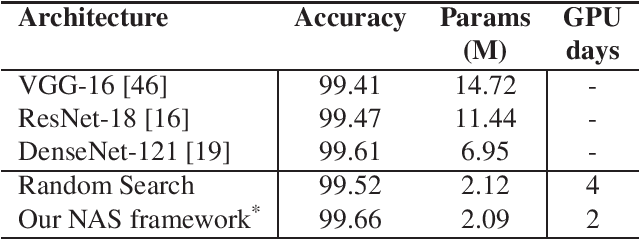
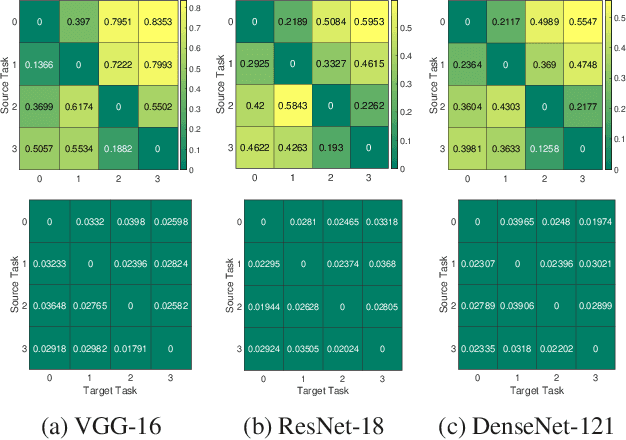
We formulate a Fr\'echet-type asymmetric distance between tasks based on Fisher Information Matrices. We show how the distance between a target task and each task in a given set of baseline tasks can be used to reduce the neural architecture search space for the target task. The complexity reduction in search space for task-specific architectures is achieved by building on the optimized architectures for similar tasks instead of doing a full search without using this side information. Experimental results demonstrate the efficacy of the proposed approach and its improvements over the state-of-the-art methods.
Neural Architecture Search From Task Similarity Measure
Mar 15, 2021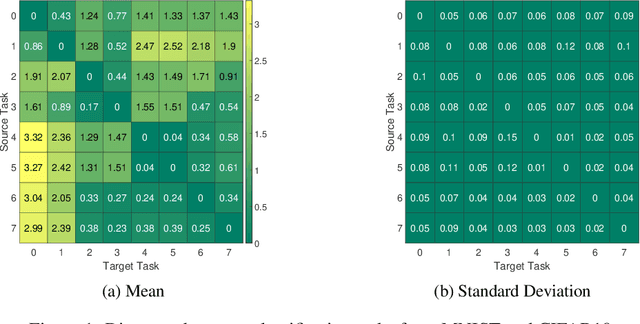
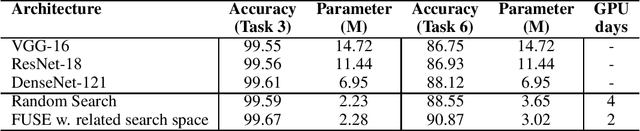
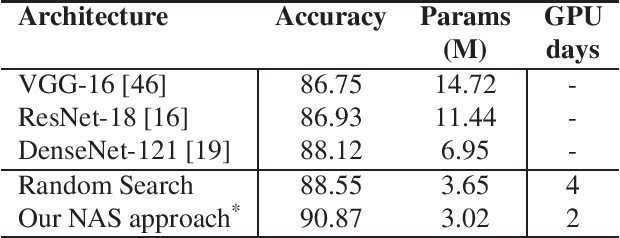
In this paper, we propose a neural architecture search framework based on a similarity measure between various tasks defined in terms of Fisher information. By utilizing the relation between a target and a set of existing tasks, the search space of architectures can be significantly reduced, making the discovery of the best candidates in the set of possible architectures tractable. This method eliminates the requirement for training the networks from scratch for the target task. Simulation results illustrate the efficacy of our proposed approach and its competitiveness with state-of-the-art methods.
Generative Archimedean Copulas
Feb 24, 2021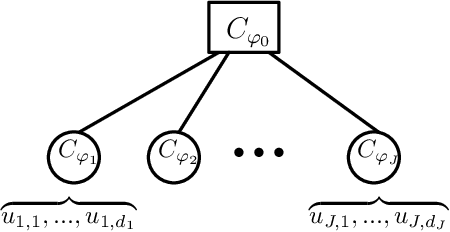
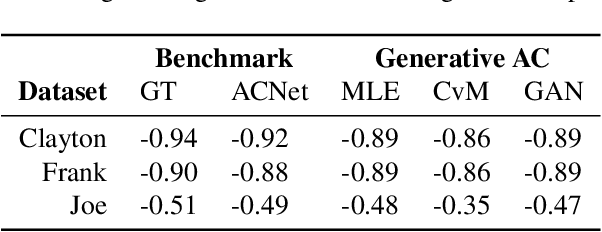
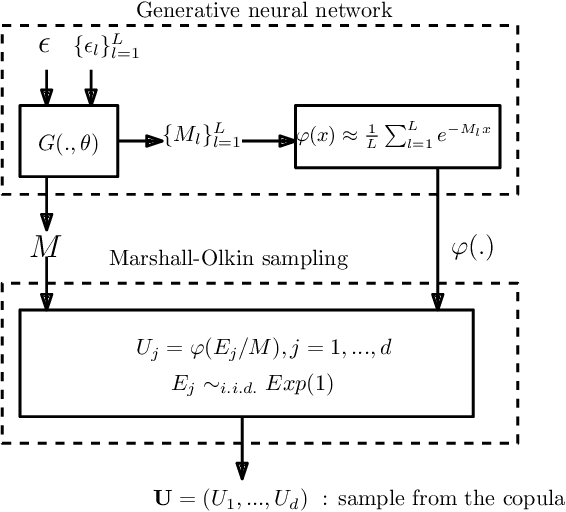
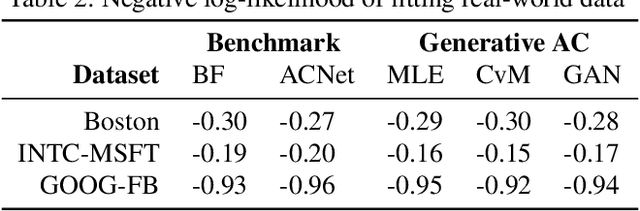
We propose a new generative modeling technique for learning multidimensional cumulative distribution functions (CDFs) in the form of copulas. Specifically, we consider certain classes of copulas known as Archimedean and hierarchical Archimedean copulas, popular for their parsimonious representation and ability to model different tail dependencies. We consider their representation as mixture models with Laplace transforms of latent random variables from generative neural networks. This alternative representation allows for easy sampling and computational efficiencies especially in high dimensions. We additionally describe multiple methods for optimizing the model parameters. Finally, we present empirical results that demonstrate the efficacy of our proposed method in learning multidimensional CDFs and its computational efficiency compared to existing methods.
Deep Extreme Value Copulas for Estimation and Sampling
Feb 17, 2021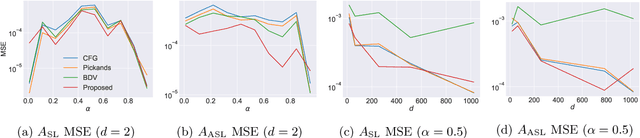

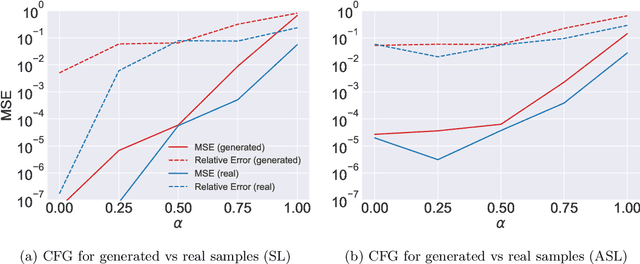
We propose a new method for modeling the distribution function of high dimensional extreme value distributions. The Pickands dependence function models the relationship between the covariates in the tails, and we learn this function using a neural network that is designed to satisfy its required properties. Moreover, we present new methods for recovering the spectral representation of extreme distributions and propose a generative model for sampling from extreme copulas. Numerical examples are provided demonstrating the efficacy and promise of our proposed methods.