 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKronecker Decomposition for GPT Compression
Oct 15, 2021



GPT is an auto-regressive Transformer-based pre-trained language model which has attracted a lot of attention in the natural language processing (NLP) domain due to its state-of-the-art performance in several downstream tasks. The success of GPT is mostly attributed to its pre-training on huge amount of data and its large number of parameters (from ~100M to billions of parameters). Despite the superior performance of GPT (especially in few-shot or zero-shot setup), this overparameterized nature of GPT can be very prohibitive for deploying this model on devices with limited computational power or memory. This problem can be mitigated using model compression techniques; however, compressing GPT models has not been investigated much in the literature. In this work, we use Kronecker decomposition to compress the linear mappings of the GPT-22 model. Our Kronecker GPT-2 model (KnGPT2) is initialized based on the Kronecker decomposed version of the GPT-2 model and then is undergone a very light pre-training on only a small portion of the training data with intermediate layer knowledge distillation (ILKD). Finally, our KnGPT2 is fine-tuned on down-stream tasks using ILKD as well. We evaluate our model on both language modeling and General Language Understanding Evaluation benchmark tasks and show that with more efficient pre-training and similar number of parameters, our KnGPT2 outperforms the existing DistilGPT2 model significantly.
Convolutional Neural Network Compression through Generalized Kronecker Product Decomposition
Sep 29, 2021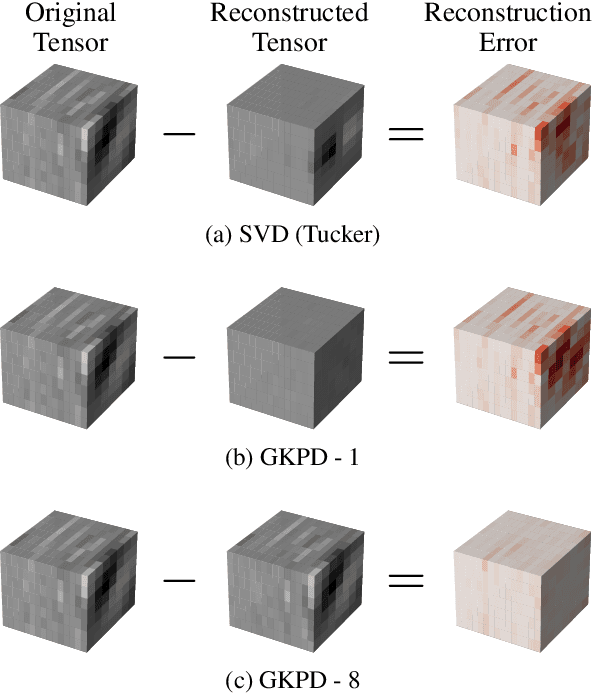
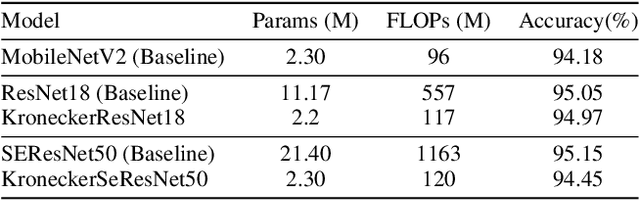
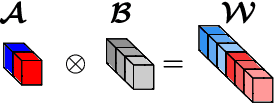
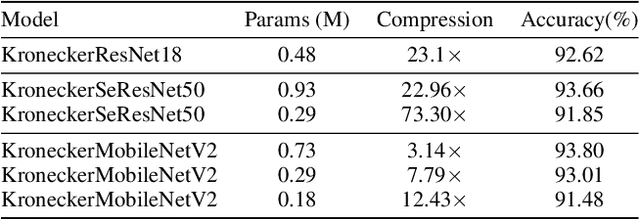
Modern Convolutional Neural Network (CNN) architectures, despite their superiority in solving various problems, are generally too large to be deployed on resource constrained edge devices. In this paper, we reduce memory usage and floating-point operations required by convolutional layers in CNNs. We compress these layers by generalizing the Kronecker Product Decomposition to apply to multidimensional tensors, leading to the Generalized Kronecker Product Decomposition(GKPD). Our approach yields a plug-and-play module that can be used as a drop-in replacement for any convolutional layer. Experimental results for image classification on CIFAR-10 and ImageNet datasets using ResNet, MobileNetv2 and SeNet architectures substantiate the effectiveness of our proposed approach. We find that GKPD outperforms state-of-the-art decomposition methods including Tensor-Train and Tensor-Ring as well as other relevant compression methods such as pruning and knowledge distillation.
iRNN: Integer-only Recurrent Neural Network
Sep 20, 2021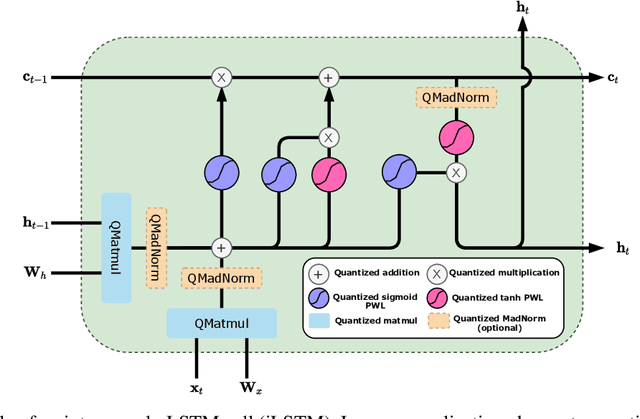

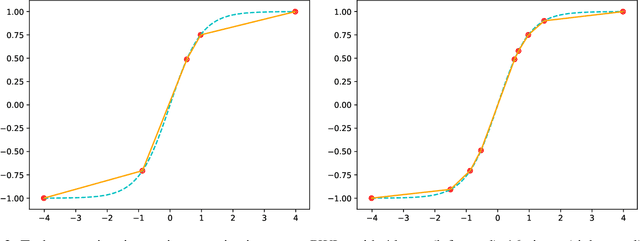

Recurrent neural networks (RNN) are used in many real-world text and speech applications. They include complex modules such as recurrence, exponential-based activation, gate interaction, unfoldable normalization, bi-directional dependence, and attention. The interaction between these elements prevents running them on integer-only operations without a significant performance drop. Deploying RNNs that include layer normalization and attention on integer-only arithmetic is still an open problem. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear approximation of activations, to serve a wide range of RNNs on various applications. The proposed method is proven to work on RNN-based language models and automatic speech recognition. Our iRNN maintains similar performance as its full-precision counterpart, their deployment on smartphones improves the runtime performance by $2\times$, and reduces the model size by $4\times$.
KroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation
Sep 13, 2021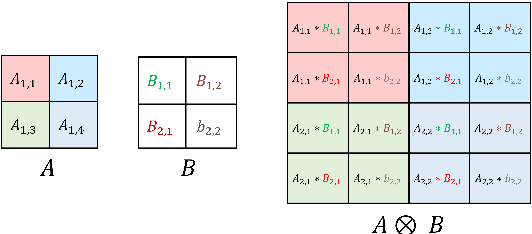
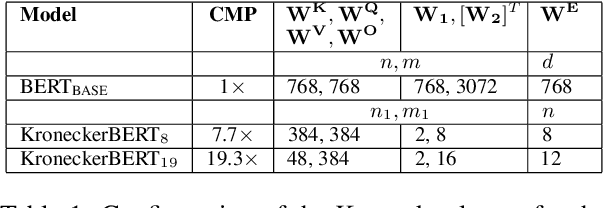
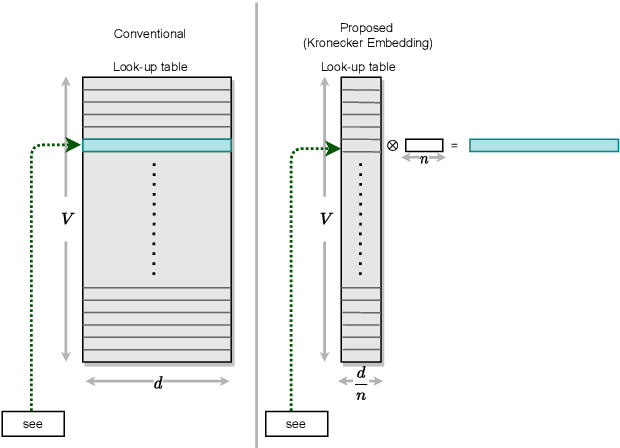

The development of over-parameterized pre-trained language models has made a significant contribution toward the success of natural language processing. While over-parameterization of these models is the key to their generalization power, it makes them unsuitable for deployment on low-capacity devices. We push the limits of state-of-the-art Transformer-based pre-trained language model compression using Kronecker decomposition. We use this decomposition for compression of the embedding layer, all linear mappings in the multi-head attention, and the feed-forward network modules in the Transformer layer. We perform intermediate-layer knowledge distillation using the uncompressed model as the teacher to improve the performance of the compressed model. We present our KroneckerBERT, a compressed version of the BERT_BASE model obtained using this framework. We evaluate the performance of KroneckerBERT on well-known NLP benchmarks and show that for a high compression factor of 19 (5% of the size of the BERT_BASE model), our KroneckerBERT outperforms state-of-the-art compression methods on the GLUE. Our experiments indicate that the proposed model has promising out-of-distribution robustness and is superior to the state-of-the-art compression methods on SQuAD.
$S^3$: Sign-Sparse-Shift Reparametrization for Effective Training of Low-bit Shift Networks
Jul 07, 2021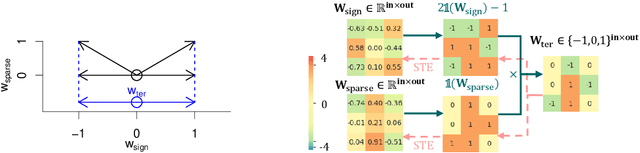



Shift neural networks reduce computation complexity by removing expensive multiplication operations and quantizing continuous weights into low-bit discrete values, which are fast and energy efficient compared to conventional neural networks. However, existing shift networks are sensitive to the weight initialization, and also yield a degraded performance caused by vanishing gradient and weight sign freezing problem. To address these issues, we propose S low-bit re-parameterization, a novel technique for training low-bit shift networks. Our method decomposes a discrete parameter in a sign-sparse-shift 3-fold manner. In this way, it efficiently learns a low-bit network with a weight dynamics similar to full-precision networks and insensitive to weight initialization. Our proposed training method pushes the boundaries of shift neural networks and shows 3-bit shift networks out-performs their full-precision counterparts in terms of top-1 accuracy on ImageNet.
A Twin Neural Model for Uplift
May 11, 2021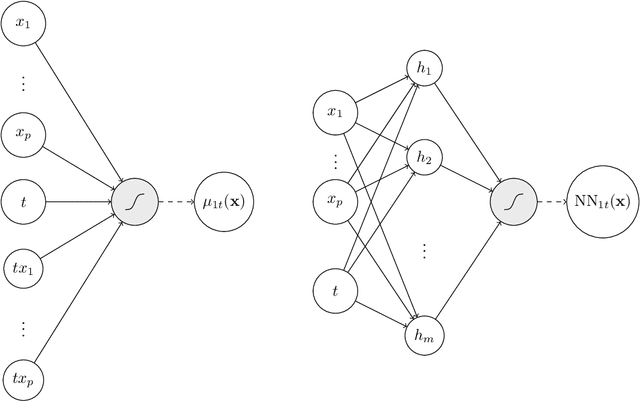
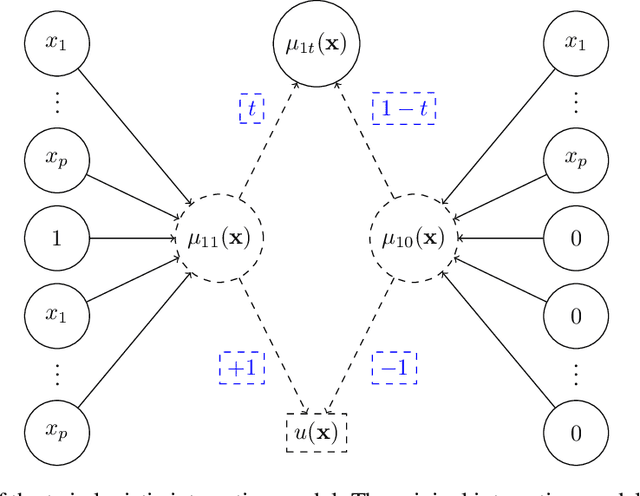
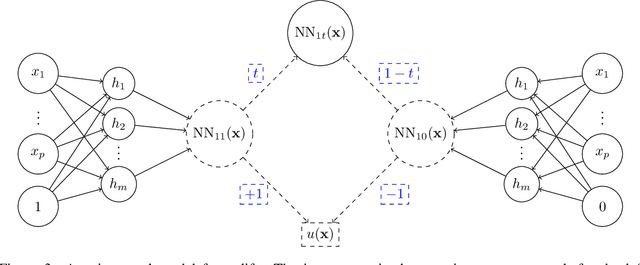
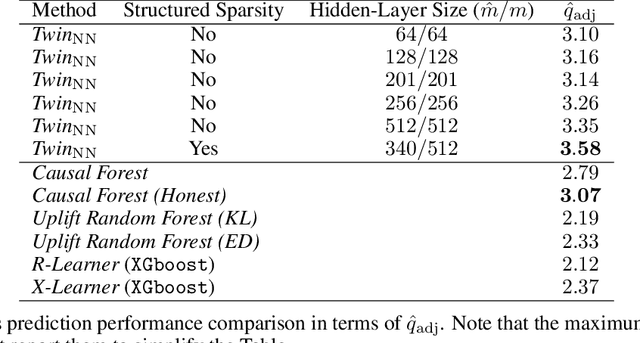
Uplift is a particular case of conditional treatment effect modeling. Such models deal with cause-and-effect inference for a specific factor, such as a marketing intervention or a medical treatment. In practice, these models are built on individual data from randomized clinical trials where the goal is to partition the participants into heterogeneous groups depending on the uplift. Most existing approaches are adaptations of random forests for the uplift case. Several split criteria have been proposed in the literature, all relying on maximizing heterogeneity. However, in practice, these approaches are prone to overfitting. In this work, we bring a new vision to uplift modeling. We propose a new loss function defined by leveraging a connection with the Bayesian interpretation of the relative risk. Our solution is developed for a specific twin neural network architecture allowing to jointly optimize the marginal probabilities of success for treated and control individuals. We show that this model is a generalization of the uplift logistic interaction model. We modify the stochastic gradient descent algorithm to allow for structured sparse solutions. This helps training our uplift models to a great extent. We show our proposed method is competitive with the state-of-the-art in simulation setting and on real data from large scale randomized experiments.
Tensor train decompositions on recurrent networks
Jun 09, 2020


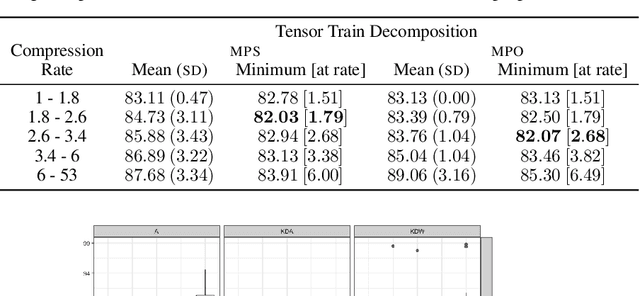
Recurrent neural networks (RNN) such as long-short-term memory (LSTM) networks are essential in a multitude of daily live tasks such as speech, language, video, and multimodal learning. The shift from cloud to edge computation intensifies the need to contain the growth of RNN parameters. Current research on RNN shows that despite the performance obtained on convolutional neural networks (CNN), keeping a good performance in compressed RNNs is still a challenge. Most of the literature on compression focuses on CNNs using matrix product (MPO) operator tensor trains. However, matrix product state (MPS) tensor trains have more attractive features than MPOs, in terms of storage reduction and computing time at inference. We show that MPS tensor trains should be at the forefront of LSTM network compression through a theoretical analysis and practical experiments on NLP task.
Clustering Causal Additive Noise Models
Jun 08, 2020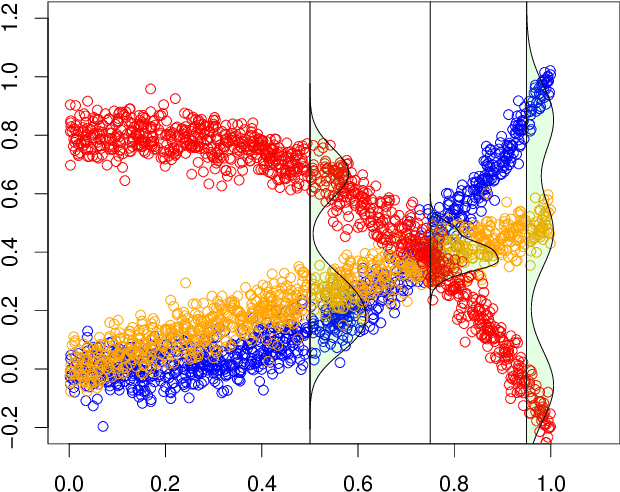
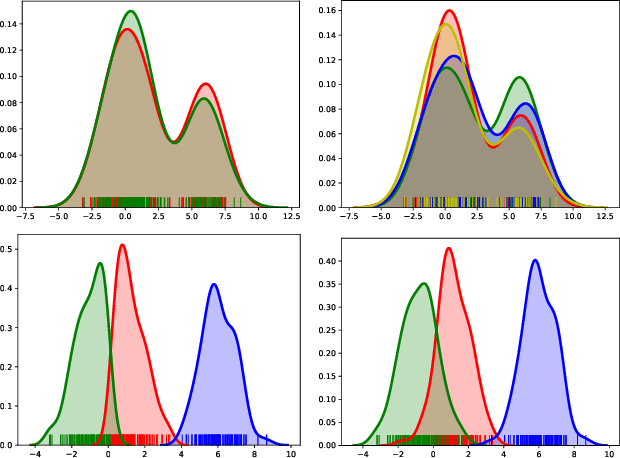
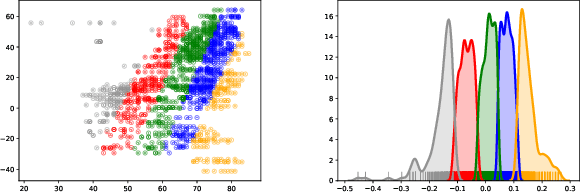
Additive noise models are commonly used to infer the causal direction for a given set of observed data. Most causal models assume a single homogeneous population. However, observations may be collected under different conditions in practice. Such data often require models that can accommodate possible heterogeneity caused by different conditions under which data have been collected. We propose a clustering algorithm inspired by the $k$-means algorithm, but with unknown $k$. Using the proposed algorithm, both the labels and the number of components are estimated from the collected data. The estimated labels are used to adjust the causal direction test statistic. The adjustment significantly improves the performance of the test statistic in identifying the correct causal direction.
Batch Normalization in Quantized Networks
Apr 29, 2020Implementation of quantized neural networks on computing hardware leads to considerable speed up and memory saving. However, quantized deep networks are difficult to train and batch~normalization (BatchNorm) layer plays an important role in training full-precision and quantized networks. Most studies on BatchNorm are focused on full-precision networks, and there is little research in understanding BatchNorm affect in quantized training which we address here. We show BatchNorm avoids gradient explosion which is counter-intuitive and recently observed in numerical experiments by other researchers.
Importance of Data Loading Pipeline in Training Deep Neural Networks
Apr 21, 2020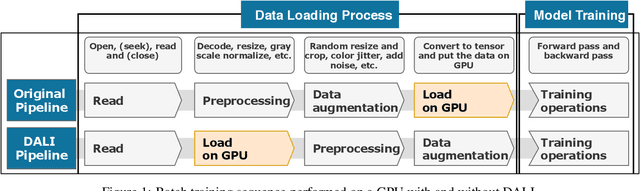
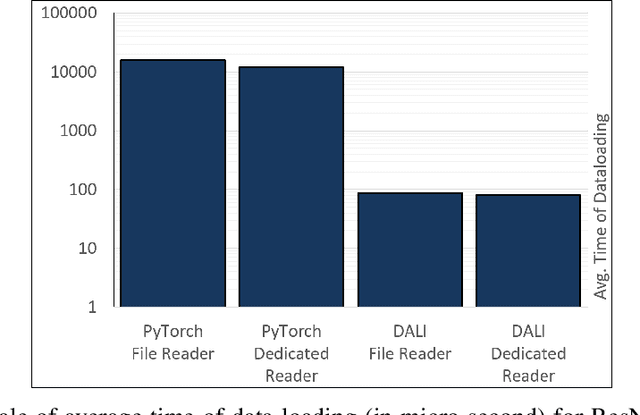
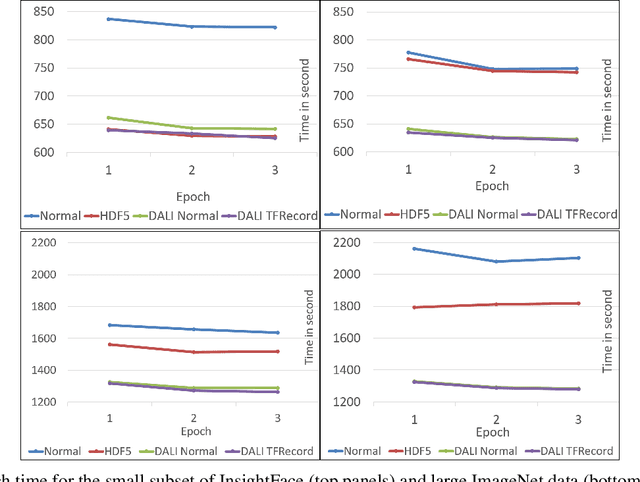
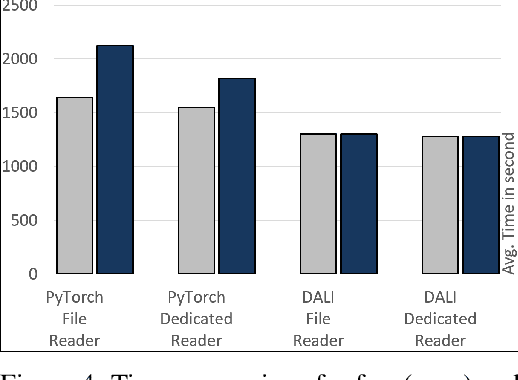
Training large-scale deep neural networks is a long, time-consuming operation, often requiring many GPUs to accelerate. In large models, the time spent loading data takes a significant portion of model training time. As GPU servers are typically expensive, tricks that can save training time are valuable.Slow training is observed especially on real-world applications where exhaustive data augmentation operations are required. Data augmentation techniques include: padding, rotation, adding noise, down sampling, up sampling, etc. These additional operations increase the need to build an efficient data loading pipeline, and to explore existing tools to speed up training time. We focus on the comparison of two main tools designed for this task, namely binary data format to accelerate data reading, and NVIDIA DALI to accelerate data augmentation. Our study shows improvement on the order of 20% to 40% if such dedicated tools are used.