 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Causal Effect Inference Failure with Uncertainty-Aware Models
Jul 01, 2020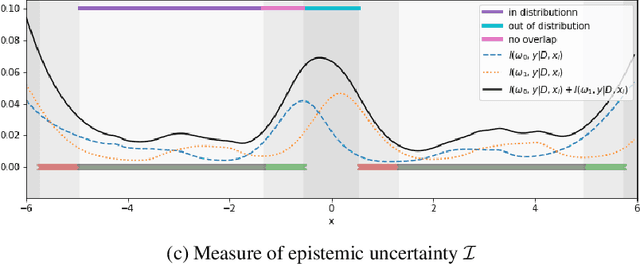
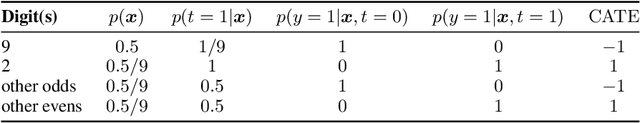
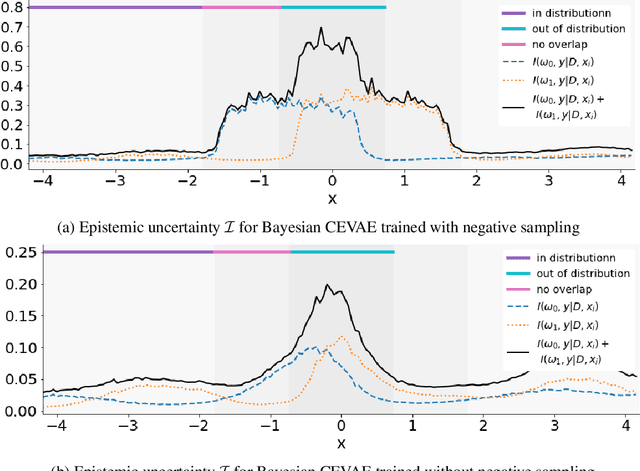
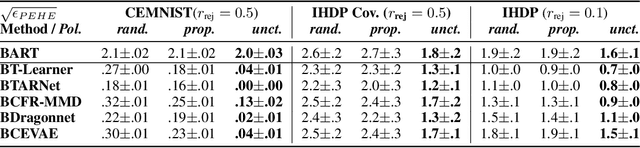
Recommending the best course of action for an individual is a major application of individual-level causal effect estimation. This application is often needed in safety-critical domains such as healthcare, where estimating and communicating uncertainty to decision-makers is crucial. We introduce a practical approach for integrating uncertainty estimation into a class of state-of-the-art neural network methods used for individual-level causal estimates. We show that our methods enable us to deal gracefully with situations of "no-overlap", common in high-dimensional data, where standard applications of causal effect approaches fail. Further, our methods allow us to handle covariate shift, where test distribution differs to train distribution, common when systems are deployed in practice. We show that when such a covariate shift occurs, correctly modeling uncertainty can keep us from giving overconfident and potentially harmful recommendations. We demonstrate our methodology with a range of state-of-the-art models. Under both covariate shift and lack of overlap, our uncertainty-equipped methods can alert decisions makers when predictions are not to be trusted while outperforming their uncertainty-oblivious counterparts.
A causal view of compositional zero-shot recognition
Jun 25, 2020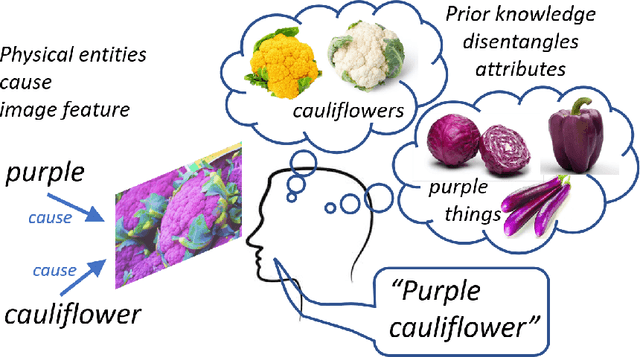
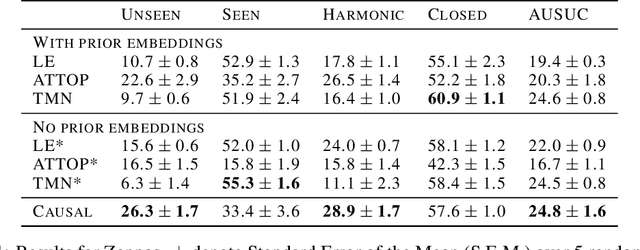
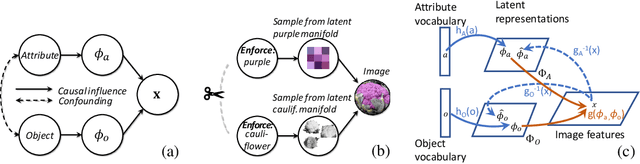

People easily recognize new visual categories that are new combinations of known components. This compositional generalization capacity is critical for learning in real-world domains like vision and language because the long tail of new combinations dominates the distribution. Unfortunately, learning systems struggle with compositional generalization because they often build on features that are correlated with class labels even if they are not "essential" for the class. This leads to consistent misclassification of samples from a new distribution, like new combinations of known components. Here we describe an approach for compositional generalization that builds on causal ideas. First, we describe compositional zero-shot learning from a causal perspective, and propose to view zero-shot inference as finding "which intervention caused the image?". Second, we present a causal-inspired embedding model that learns disentangled representations of elementary components of visual objects from correlated (confounded) training data. We evaluate this approach on two datasets for predicting new combinations of attribute-object pairs: A well-controlled synthesized images dataset and a real world dataset which consists of fine-grained types of shoes. We show improvements compared to strong baselines.
CausaLM: Causal Model Explanation Through Counterfactual Language Models
Jun 14, 2020
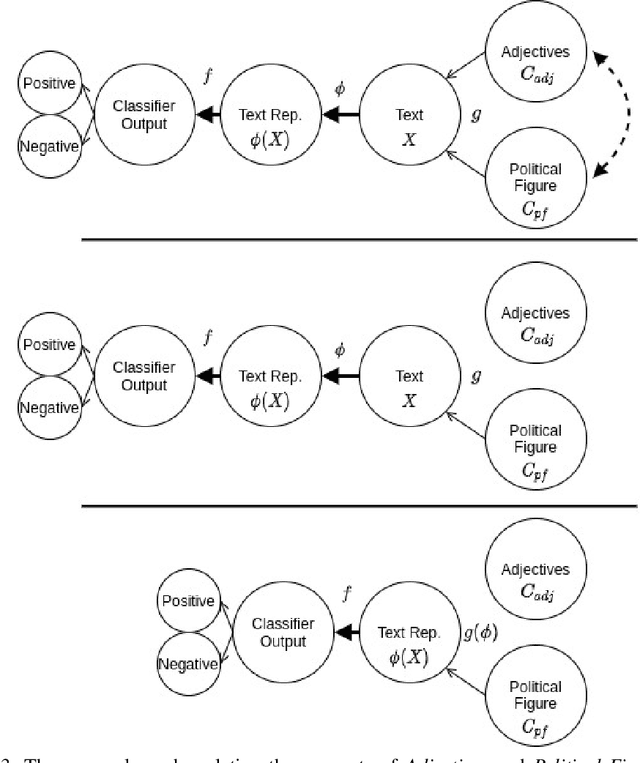

Understanding predictions made by deep neural networks is notoriously difficult, but also crucial to their dissemination. As all ML-based methods, they are as good as their training data, and can also capture unwanted biases. While there are tools that can help understand whether such biases exist, they do not distinguish between correlation and causation, and might be ill-suited for text-based models and for reasoning about high level language concepts. A key problem of estimating the causal effect of a concept of interest on a given model is that this estimation requires the generation of counterfactual examples, which is challenging with existing generation technology. To bridge that gap, we propose CausaLM, a framework for producing causal model explanations using counterfactual language representation models. Our approach is based on fine-tuning of deep contextualized embedding models with auxiliary adversarial tasks derived from the causal graph of the problem. Concretely, we show that by carefully choosing auxiliary adversarial pre-training tasks, language representation models such as BERT can effectively learn a counterfactual representation for a given concept of interest, and be used to estimate its true causal effect on model performance. A byproduct of our method is a language representation model that is unaffected by the tested concept, which can be useful in mitigating unwanted bias ingrained in the data.
Bandits with Partially Observable Offline Data
Jun 11, 2020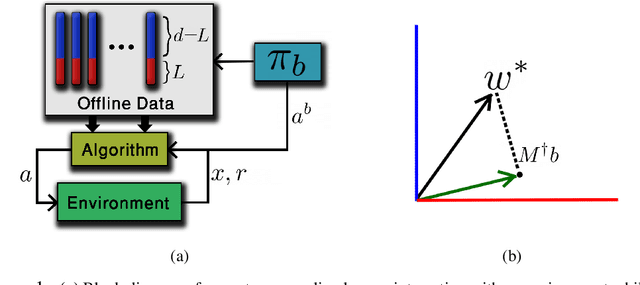
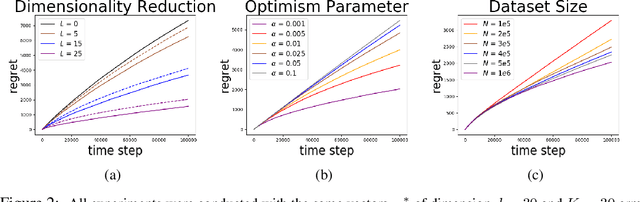
We study linear contextual bandits with access to a large, partially observable, offline dataset that was sampled from some fixed policy. We show that this problem is closely related to a variant of the bandit problem with side information. We construct a linear bandit algorithm that takes advantage of the projected information, and prove regret bounds. Our results demonstrate the ability to take full advantage of partially observable offline data. Particularly, we prove regret bounds that improve current bounds by a factor related to the visible dimensionality of the contexts in the data. Our results indicate that partially observable offline data can significantly improve online learning algorithms. Finally, we demonstrate various characteristics of our approach through synthetic simulations.
Generative ODE Modeling with Known Unknowns
Mar 24, 2020
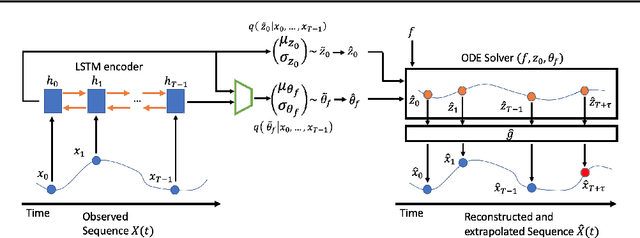
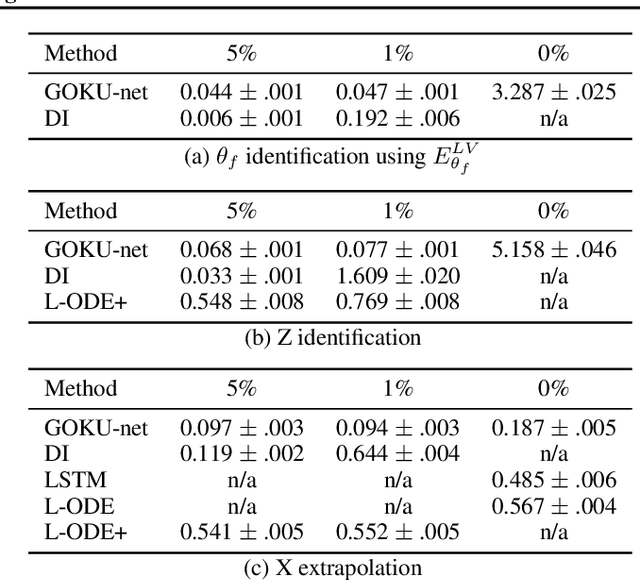
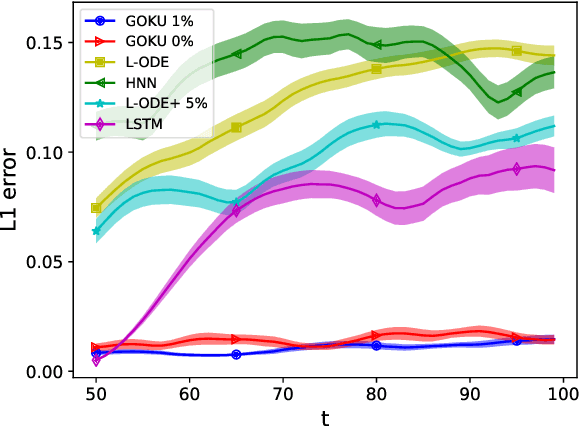
In several crucial applications, domain knowledge is encoded by a system of ordinary differential equations (ODE). A motivating example is intensive care unit patients: The dynamics of some vital physiological variables such as heart rate, blood pressure and arterial compliance can be approximately described by a known system of ODEs. Typically, some of the ODE variables are directly observed while some are unobserved, and in addition many other variables are observed but not modeled by the ODE, for example body temperature. Importantly, the unobserved ODE variables are ``known-unknowns'': We know they exist and their functional dynamics, but cannot measure them directly, nor do we know the function tying them to all observed measurements. Estimating these known-unknowns is often highly valuable to physicians. Under this scenario we wish to: (i) learn the static parameters of the ODE generating each observed time-series (ii) infer the dynamic sequence of all ODE variables including the known-unknowns, and (iii) extrapolate the future of the ODE variables and the observations of the time-series. We address this task with a variational autoencoder incorporating the known ODE function, called GOKU-net for Generative ODE modeling with Known Unknowns. We test our method on videos of pendulums with unknown length, and a model of the cardiovascular system.
Generalization Bounds and Representation Learning for Estimation of Potential Outcomes and Causal Effects
Jan 21, 2020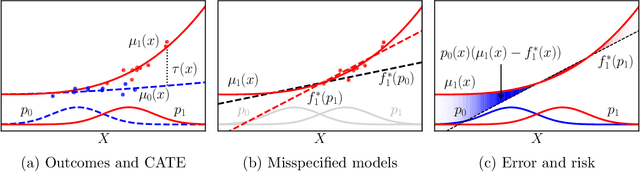
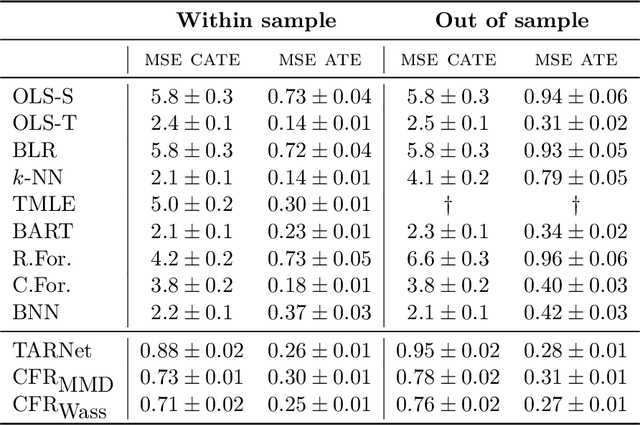
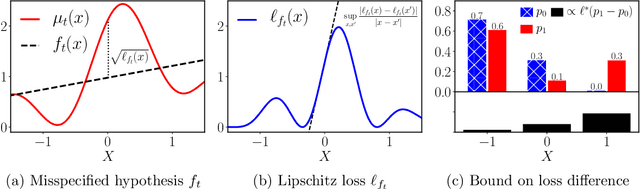
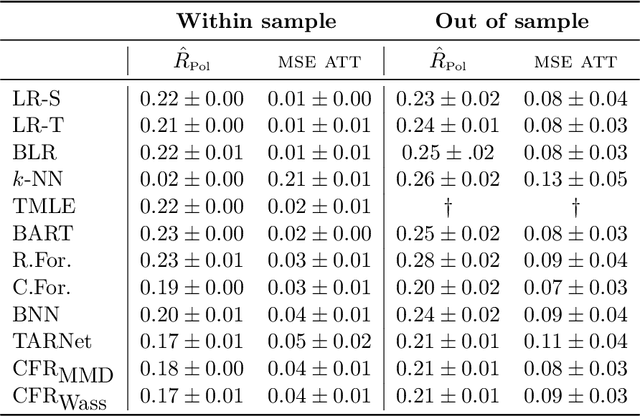
Practitioners in diverse fields such as healthcare, economics and education are eager to apply machine learning to improve decision making. The cost and impracticality of performing experiments and a recent monumental increase in electronic record keeping has brought attention to the problem of evaluating decisions based on non-experimental observational data. This is the setting of this work. In particular, we study estimation of individual-level causal effects, such as a single patient's response to alternative medication, from recorded contexts, decisions and outcomes. We give generalization bounds on the error in estimated effects based on distance measures between groups receiving different treatments, allowing for sample re-weighting. We provide conditions under which our bound is tight and show how it relates to results for unsupervised domain adaptation. Led by our theoretical results, we devise representation learning algorithms that minimize our bound, by regularizing the representation's induced treatment group distance, and encourage sharing of information between treatment groups. We extend these algorithms to simultaneously learn a weighted representation to further reduce treatment group distances. Finally, an experimental evaluation on real and synthetic data shows the value of our proposed representation architecture and regularization scheme.
Robust learning with the Hilbert-Schmidt independence criterion
Oct 24, 2019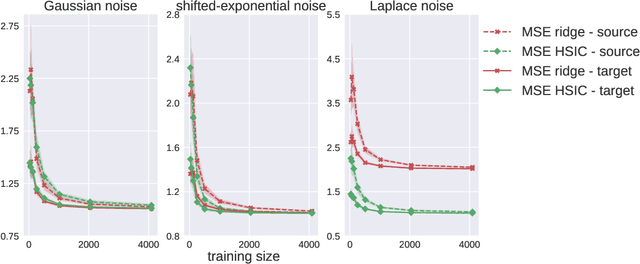
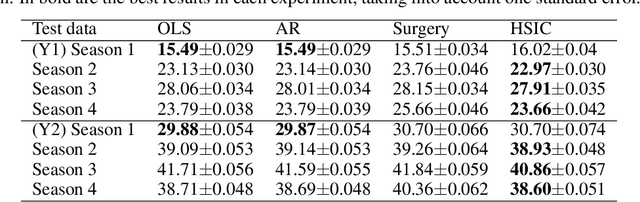
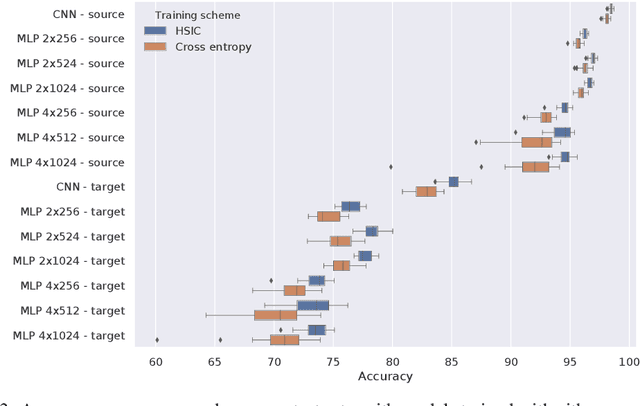
We investigate the use of a non-parametric independence measure, the Hilbert-Schmidt Independence Criterion (HSIC), as a loss-function for learning robust regression and classification models. This loss-function encourages learning models where the distribution of the residuals between the label and the model-prediction is statistically independent of the distribution of the instances themselves. This loss-function was first proposed by Mooij et al. [2009] in the context of learning causal graphs. We adapt it to the task of robust learning for unsupervised covariate shift: learning on a source domain without access to any instances or labels from the unknown target domain. We prove that the proposed loss is expected to generalize to a class of target domains described in terms of the complexity of their density ratio function with respect to the source domain. Experiments on tasks of unsupervised covariate shift demonstrate that models learned with the proposed loss-function outperform several baseline methods.
Off-Policy Evaluation in Partially Observable Environments
Sep 09, 2019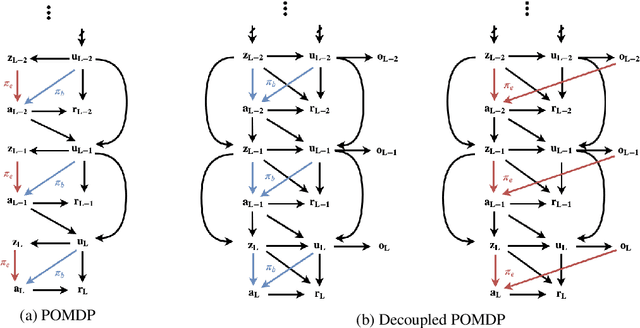
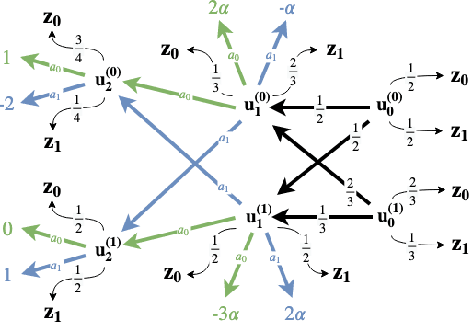
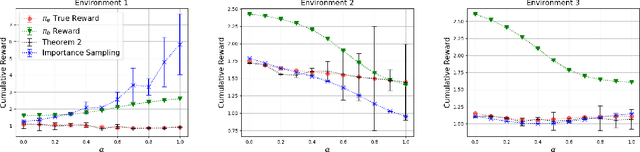
This work studies the problem of batch off-policy evaluation for Reinforcement Learning in partially observable environments. Off-policy evaluation under partial observability is inherently prone to bias, with risk of arbitrarily large errors. We define the problem of off-policy evaluation for Partially Observable Markov Decision Processes (POMDPs) and establish what we believe is the first off-policy evaluation result for POMDPs. In addition, we formulate a model in which observed and unobserved variables are decoupled into two dynamic processes, called a Decoupled POMDP. We show how off-policy evaluation can be performed under this new model, mitigating estimation errors inherent to the procedure we provided for general POMDPs. We demonstrate the pitfalls of off-policy evaluation in POMDPs using a well-known off-policy method, importance sampling, and compare with our result on synthetic medical data.
Explaining Classifiers with Causal Concept Effect (CaCE)
Jul 16, 2019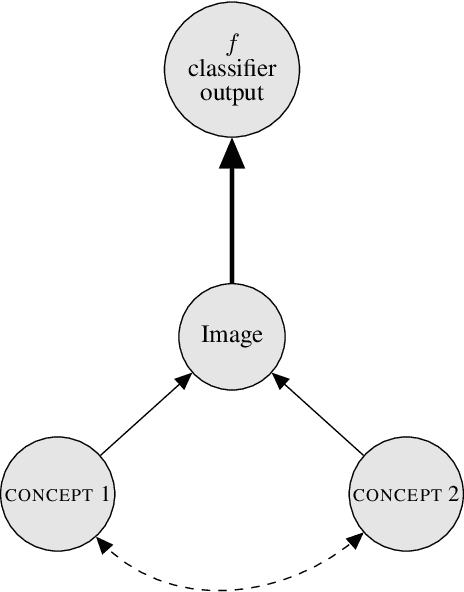
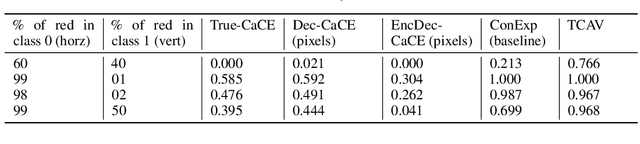


How can we understand classification decisions made by deep neural nets? We propose answering this question by using ideas from causal inference. We define the ``Causal Concept Effect'' (CaCE) as the causal effect that the presence or absence of a concept has on the prediction of a given deep neural net. We then use this measure as a mean to understand what drives the network's prediction and what does not. Yet many existing interpretability methods rely solely on correlations, resulting in potentially misleading explanations. We show how CaCE can avoid such mistakes. In high-risk domains such as medicine, knowing the root cause of the prediction is crucial. If we knew that the network's prediction was caused by arbitrary concepts such as the lighting conditions in an X-ray room instead of medically meaningful concept, this would prevent us from disastrous deployment of such models. Estimating CaCE is difficult in situations where we cannot easily simulate the do-operator. As a simple solution, we propose learning a generative model, specifically a Variational AutoEncoder (VAE) on image pixels or image embeddings extracted from the classifier to measure VAE-CaCE. We show that VAE-CaCE is able to correctly estimate the true causal effect as compared to other baselines in controlled settings with synthetic and semi-natural high dimensional images.
Removing Hidden Confounding by Experimental Grounding
Oct 27, 2018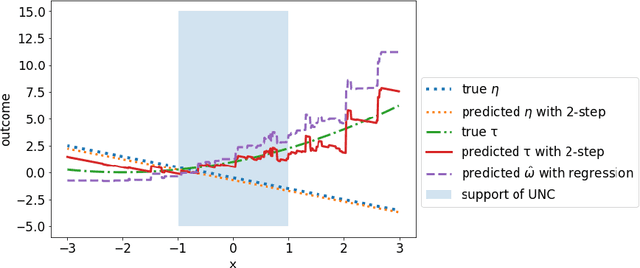
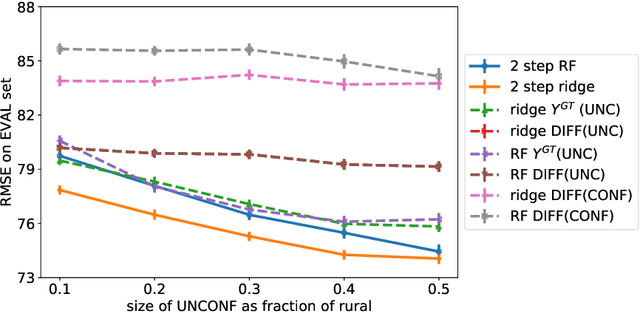
Observational data is increasingly used as a means for making individual-level causal predictions and intervention recommendations. The foremost challenge of causal inference from observational data is hidden confounding, whose presence cannot be tested in data and can invalidate any causal conclusion. Experimental data does not suffer from confounding but is usually limited in both scope and scale. We introduce a novel method of using limited experimental data to correct the hidden confounding in causal effect models trained on larger observational data, even if the observational data does not fully overlap with the experimental data. Our method makes strictly weaker assumptions than existing approaches, and we prove conditions under which it yields a consistent estimator. We demonstrate our method's efficacy using real-world data from a large educational experiment.