 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryptonite: A Cryptic Crossword Benchmark for Extreme Ambiguity in Language
Mar 01, 2021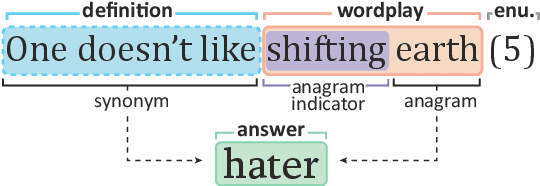


Current NLP datasets targeting ambiguity can be solved by a native speaker with relative ease. We present Cryptonite, a large-scale dataset based on cryptic crosswords, which is both linguistically complex and naturally sourced. Each example in Cryptonite is a cryptic clue, a short phrase or sentence with a misleading surface reading, whose solving requires disambiguating semantic, syntactic, and phonetic wordplays, as well as world knowledge. Cryptic clues pose a challenge even for experienced solvers, though top-tier experts can solve them with almost 100% accuracy. Cryptonite is a challenging task for current models; fine-tuning T5-Large on 470k cryptic clues achieves only 7.6% accuracy, on par with the accuracy of a rule-based clue solver (8.6%).
Deep Ordinal Regression using Optimal Transport Loss and Unimodal Output Probabilities
Nov 15, 2020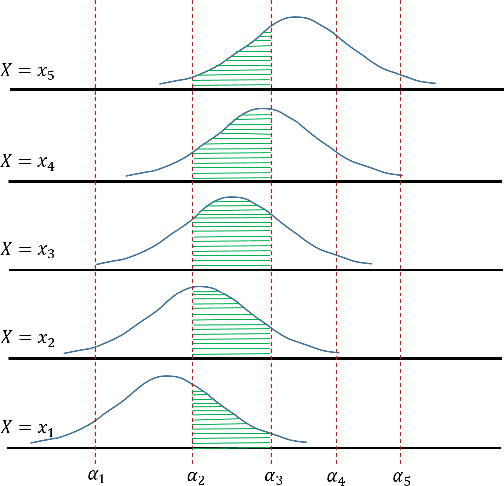
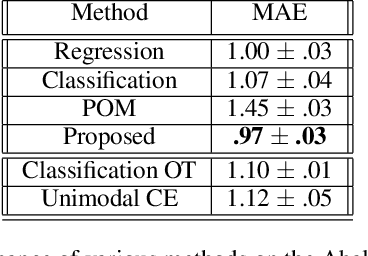
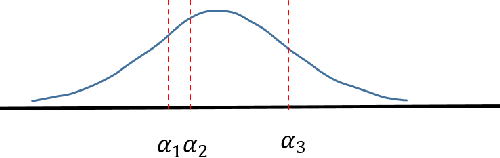
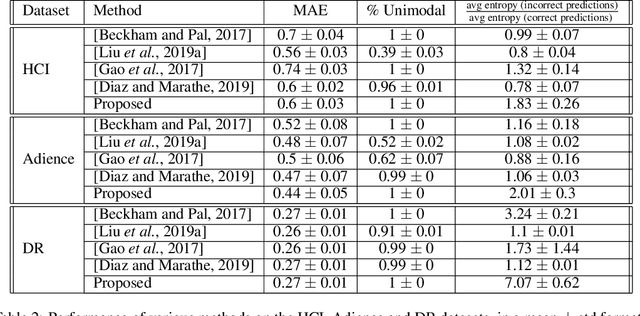
We propose a framework for deep ordinal regression, based on unimodal output distribution and optimal transport loss. Despite being seemingly appropriate, in many recent works the unimodality requirement is either absent, or implemented using soft targets, which do not guarantee unimodal outputs at inference. In addition, we argue that the standard maximum likelihood objective is not suitable for ordinal regression problems, and that optimal transport is better suited for this task, as it naturally captures the order of the classes. Inspired by the well-known Proportional Odds model, we propose to modify its design by using an architectural mechanism which guarantees that the model output distribution will be unimodal. We empirically analyze the different components of our propose approach and demonstrate their contribution to the performance of the model. Experimental results on three real-world datasets demonstrate that our proposed approach performs on par with several recently proposed deep learning approaches for deep ordinal regression with unimodal output probabilities, while having guarantee on the output unimodality. In addition, we demonstrate that the level of prediction uncertainty of the model correlates with its accuracy.
Neural Machine Translation without Embeddings
Aug 21, 2020
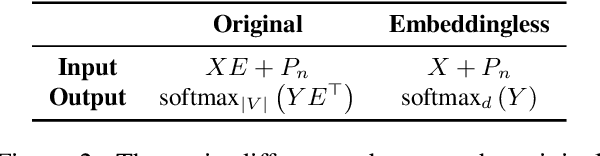
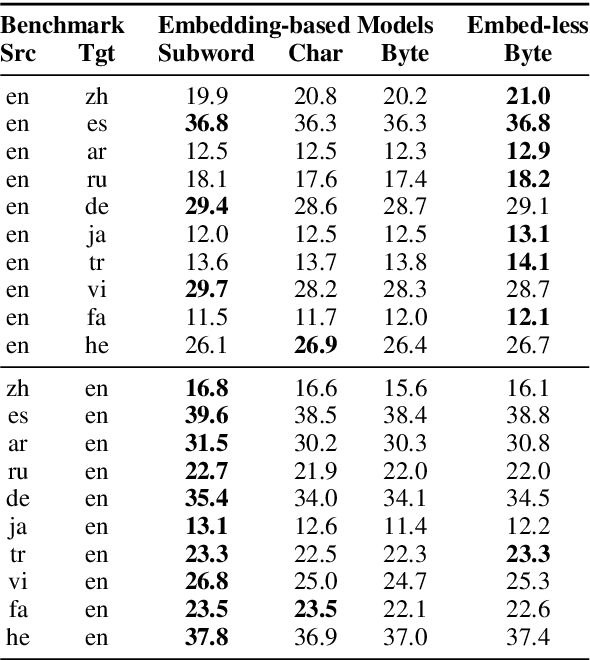
Many NLP models follow the embed-contextualize-predict paradigm, in which each sequence token is represented as a dense vector via an embedding matrix, and fed into a contextualization component that aggregates the information from the entire sequence in order to make a prediction. Could NLP models work without the embedding component? To that end, we omit the input and output embeddings from a standard machine translation model, and represent text as a sequence of bytes via UTF-8 encoding, using a constant 256-dimension one-hot representation for each byte. Experiments on 10 language pairs show that removing the embedding matrix consistently improves the performance of byte-to-byte models, often outperforms character-to-character models, and sometimes even produces better translations than standard subword models.
Let the Data Choose its Features: Differentiable Unsupervised Feature Selection
Jul 11, 2020

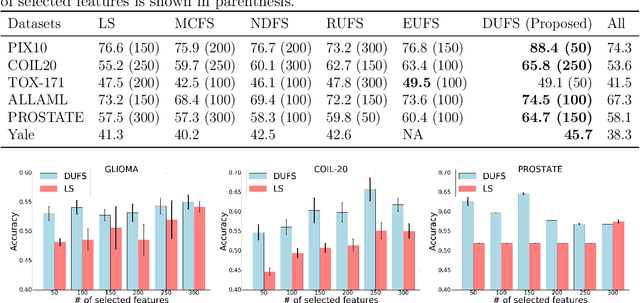
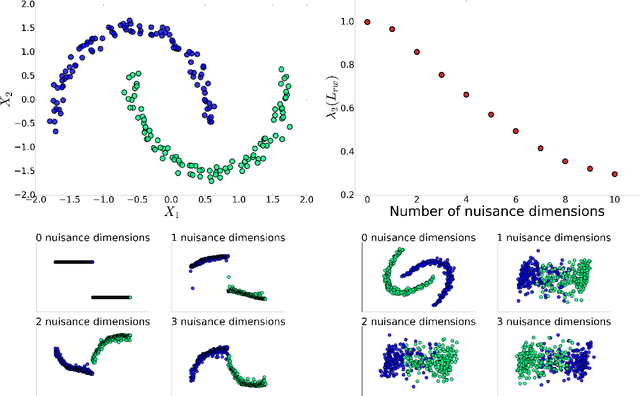
Scientific observations often consist of a large number of variables (features). Identifying a subset of meaningful features is often ignored in unsupervised learning, despite its potential for unraveling clear patterns hidden in the ambient space. In this paper, we present a method for unsupervised feature selection, tailored for the task of clustering. We propose a differentiable loss function which combines the graph Laplacian with a gating mechanism based on continuous approximation of Bernoulli random variables. The Laplacian is used to define a scoring term that favors low-frequency features, while the parameters of the Bernoulli variables are trained to enable selection of the most informative features. We mathematically motivate the proposed approach and demonstrate that in the high noise regime, it is crucial to compute the Laplacian on the gated inputs, rather than on the full feature set. Experimental demonstration of the efficacy of the proposed approach and its advantage over current baselines is provided using several real-world examples.
Learning to Ask Medical Questions using Reinforcement Learning
Mar 31, 2020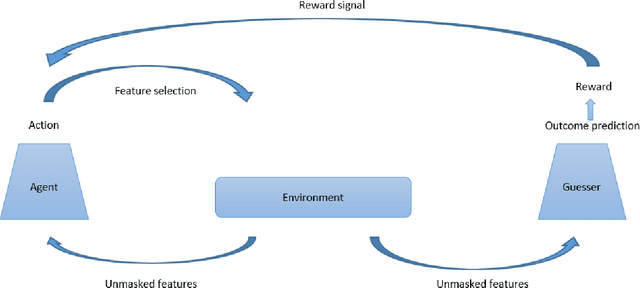


We propose a novel reinforcement learning-based approach for adaptive and iterative feature selection. Given a masked vector of input features, a reinforcement learning agent iteratively selects certain features to be unmasked, and uses them to predict an outcome when it is sufficiently confident. The algorithm makes use of a novel environment setting, corresponding to a non-stationary Markov Decision Process. A key component of our approach is a guesser network, trained to predict the outcome from the selected features and parametrizing the reward function. Applying our method to a national survey dataset, we show that it not only outperforms strong baselines when requiring the prediction to be made based on a small number of input features, but is also highly more interpretable. Our code is publicly available at \url{https://github.com/ushaham/adaptiveFS}.
Automated Characterization of Stenosis in Invasive Coronary Angiography Images with Convolutional Neural Networks
Jul 19, 2018
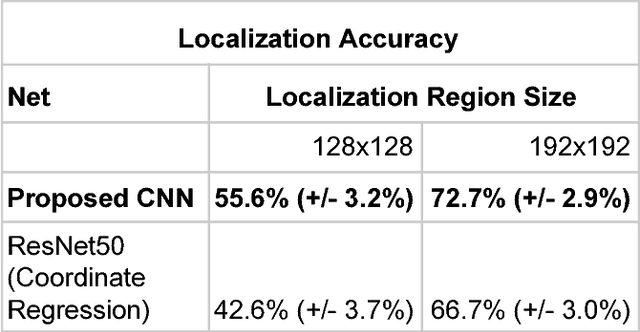
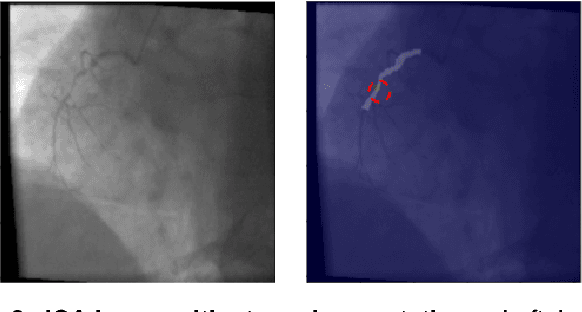
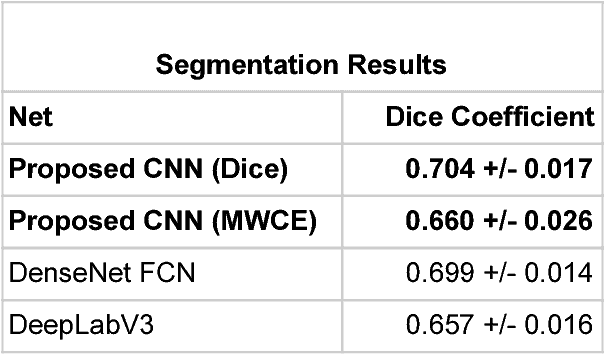
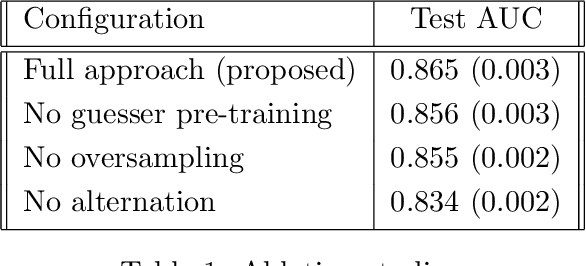
The determination of a coronary stenosis and its severity in current clinical workflow is typically accomplished manually via physician visual assessment (PVA) during invasive coronary angiography. While PVA has shown large inter-rater variability, the more reliable and accurate alternative of Quantitative Coronary Angiography (QCA) is challenging to perform in real-time due to the busy workflow in cardiac catheterization laboratories. We propose a deep learning approach based on Convolutional Neural Networks (CNN) that automatically characterizes and analyzes coronary stenoses in real-time by automating clinical tasks performed during QCA. Our deep learning methods for localization, segmentation and classification of stenosis in still-frame invasive coronary angiography (ICA) images of the right coronary artery (RCA) achieve performance of 72.7% localization accuracy, 0.704 dice coefficient and 0.825 C-statistic in each respective task. Integrated in an end-to-end approach, our model's performance shows statistically significant improvement in false discovery rate over the current standard in real-time clinical stenosis assessment, PVA. To the best of the authors' knowledge, this is the first time an automated machine learning system has been developed that can implement tasks performed in QCA, and the first time an automated machine learning system has demonstrated significant improvement over the current clinical standard for rapid RCA stenosis analysis.
Defending against Adversarial Images using Basis Functions Transformations
Apr 16, 2018
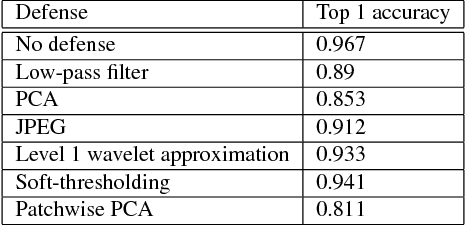

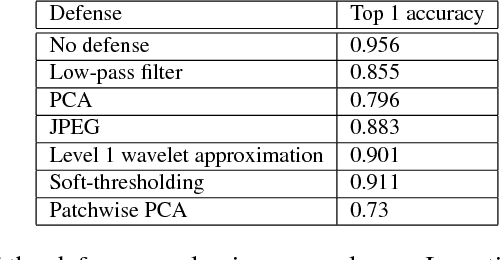
We study the effectiveness of various approaches that defend against adversarial attacks on deep networks via manipulations based on basis function representations of images. Specifically, we experiment with low-pass filtering, PCA, JPEG compression, low resolution wavelet approximation, and soft-thresholding. We evaluate these defense techniques using three types of popular attacks in black, gray and white-box settings. Our results show JPEG compression tends to outperform the other tested defenses in most of the settings considered, in addition to soft-thresholding, which performs well in specific cases, and yields a more mild decrease in accuracy on benign examples. In addition, we also mathematically derive a novel white-box attack in which the adversarial perturbation is composed only of terms corresponding a to pre-determined subset of the basis functions, of which a "low frequency attack" is a special case.
SpectralNet: Spectral Clustering using Deep Neural Networks
Apr 04, 2018
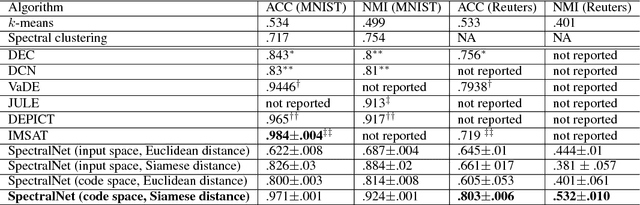
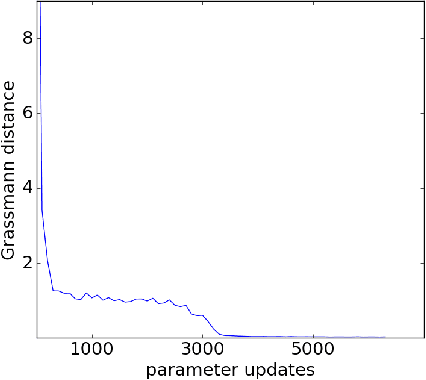
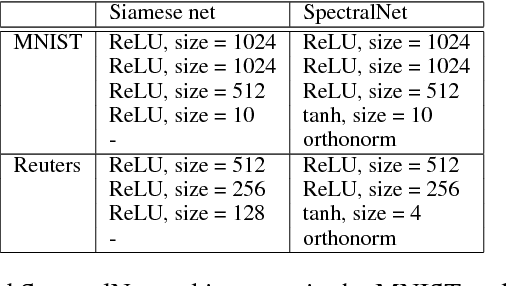
Spectral clustering is a leading and popular technique in unsupervised data analysis. Two of its major limitations are scalability and generalization of the spectral embedding (i.e., out-of-sample-extension). In this paper we introduce a deep learning approach to spectral clustering that overcomes the above shortcomings. Our network, which we call SpectralNet, learns a map that embeds input data points into the eigenspace of their associated graph Laplacian matrix and subsequently clusters them. We train SpectralNet using a procedure that involves constrained stochastic optimization. Stochastic optimization allows it to scale to large datasets, while the constraints, which are implemented using a special-purpose output layer, allow us to keep the network output orthogonal. Moreover, the map learned by SpectralNet naturally generalizes the spectral embedding to unseen data points. To further improve the quality of the clustering, we replace the standard pairwise Gaussian affinities with affinities leaned from unlabeled data using a Siamese network. Additional improvement can be achieved by applying the network to code representations produced, e.g., by standard autoencoders. Our end-to-end learning procedure is fully unsupervised. In addition, we apply VC dimension theory to derive a lower bound on the size of SpectralNet. State-of-the-art clustering results are reported on the Reuters dataset. Our implementation is publicly available at https://github.com/kstant0725/SpectralNet .
Removal of Batch Effects using Distribution-Matching Residual Networks
Jan 08, 2018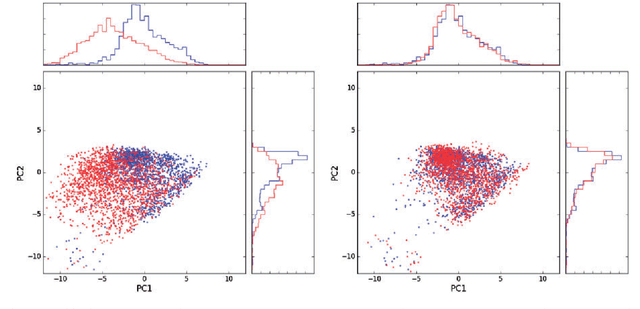
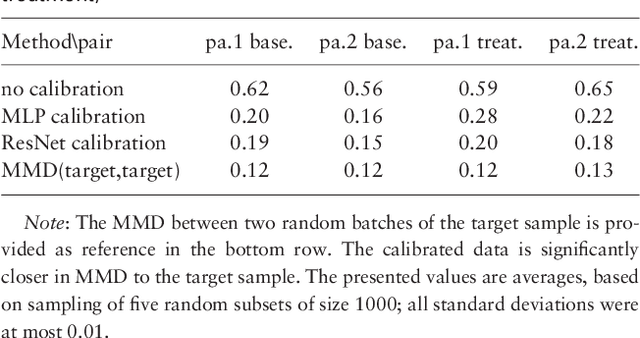
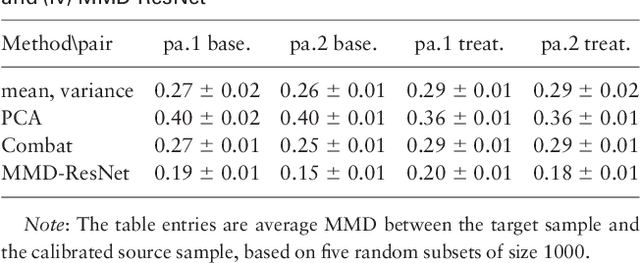
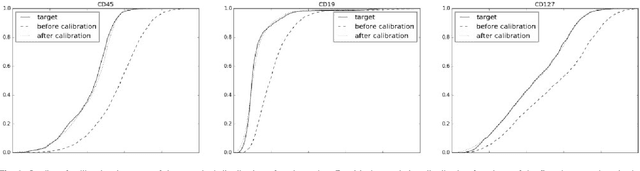
Sources of variability in experimentally derived data include measurement error in addition to the physical phenomena of interest. This measurement error is a combination of systematic components, originating from the measuring instrument, and random measurement errors. Several novel biological technologies, such as mass cytometry and single-cell RNA-seq, are plagued with systematic errors that may severely affect statistical analysis if the data is not properly calibrated. We propose a novel deep learning approach for removing systematic batch effects. Our method is based on a residual network, trained to minimize the Maximum Mean Discrepancy (MMD) between the multivariate distributions of two replicates, measured in different batches. We apply our method to mass cytometry and single-cell RNA-seq datasets, and demonstrate that it effectively attenuates batch effects.
DeepSurv: Personalized Treatment Recommender System Using A Cox Proportional Hazards Deep Neural Network
Aug 09, 2017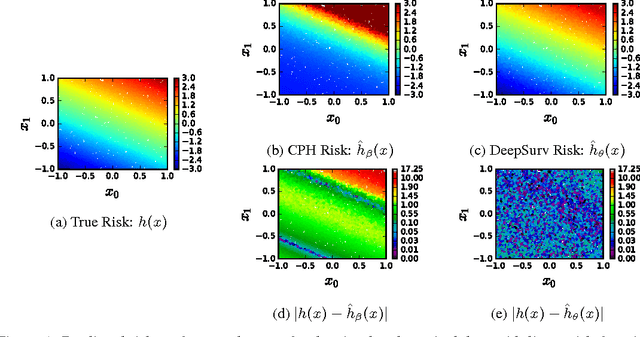
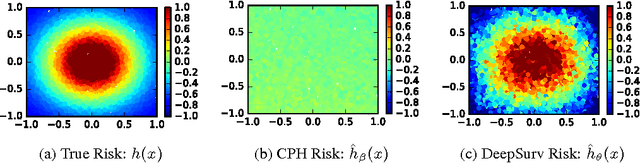
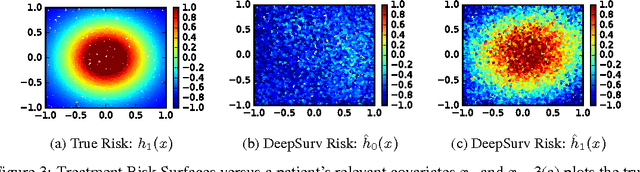
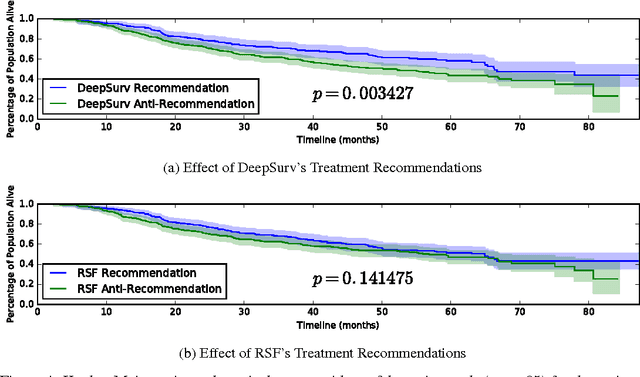
Medical practitioners use survival models to explore and understand the relationships between patients' covariates (e.g. clinical and genetic features) and the effectiveness of various treatment options. Standard survival models like the linear Cox proportional hazards model require extensive feature engineering or prior medical knowledge to model treatment interaction at an individual level. While nonlinear survival methods, such as neural networks and survival forests, can inherently model these high-level interaction terms, they have yet to be shown as effective treatment recommender systems. We introduce DeepSurv, a Cox proportional hazards deep neural network and state-of-the-art survival method for modeling interactions between a patient's covariates and treatment effectiveness in order to provide personalized treatment recommendations. We perform a number of experiments training DeepSurv on simulated and real survival data. We demonstrate that DeepSurv performs as well as or better than other state-of-the-art survival models and validate that DeepSurv successfully models increasingly complex relationships between a patient's covariates and their risk of failure. We then show how DeepSurv models the relationship between a patient's features and effectiveness of different treatment options to show how DeepSurv can be used to provide individual treatment recommendations. Finally, we train DeepSurv on real clinical studies to demonstrate how it's personalized treatment recommendations would increase the survival time of a set of patients. The predictive and modeling capabilities of DeepSurv will enable medical researchers to use deep neural networks as a tool in their exploration, understanding, and prediction of the effects of a patient's characteristics on their risk of failure.