 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Less, Infer Faster: Efficient Model Finetuning and Compression via Structured Sparsity
Feb 09, 2026Fully finetuning foundation language models (LMs) with billions of parameters is often impractical due to high computational costs, memory requirements, and the risk of overfitting. Although methods like low-rank adapters help address these challenges by adding small trainable modules to the frozen LM, they also increase memory usage and do not reduce inference latency. We uncover an intriguing phenomenon: sparsifying specific model rows and columns enables efficient task adaptation without requiring weight tuning. We propose a scheme for effective finetuning via sparsification using training stochastic gates, which requires minimal trainable parameters, reduces inference time, and removes 20--40\% of model parameters without significant accuracy loss. Empirical results show it outperforms recent finetuning baselines in efficiency and performance. Additionally, we provide theoretical guarantees for the convergence of this stochastic gating process, and show that our method admits a simpler and better-conditioned optimization landscape compared to LoRA. Our results highlight sparsity as a compelling mechanism for task-specific adaptation in LMs.
FineGates: LLMs Finetuning with Compression using Stochastic Gates
Dec 17, 2024



Large Language Models (LLMs), with billions of parameters, present significant challenges for full finetuning due to the high computational demands, memory requirements, and impracticality of many real-world applications. When faced with limited computational resources or small datasets, updating all model parameters can often result in overfitting. To address this, lightweight finetuning techniques have been proposed, like learning low-rank adapter layers. These methods aim to train only a few additional parameters combined with the base model, which remains frozen, reducing resource usage and mitigating overfitting risks. In this work, we propose an adaptor model based on stochastic gates that simultaneously sparsify the frozen base model with task-specific adaptation. Our method comes with a small number of trainable parameters and allows us to speed up the base model inference with competitive accuracy. We evaluate it in additional variants by equipping it with additional low-rank parameters and comparing it to several recent baselines. Our results show that the proposed method improves the finetuned model accuracy comparatively to the several baselines and allows the removal of up to 20-40\% without significant accuracy loss.
AdaRankGrad: Adaptive Gradient-Rank and Moments for Memory-Efficient LLMs Training and Fine-Tuning
Oct 23, 2024



Training and fine-tuning large language models (LLMs) come with challenges related to memory and computational requirements due to the increasing size of the model weights and the optimizer states. Various techniques have been developed to tackle these challenges, such as low-rank adaptation (LoRA), which involves introducing a parallel trainable low-rank matrix to the fixed pre-trained weights at each layer. However, these methods often fall short compared to the full-rank weight training approach, as they restrict the parameter search to a low-rank subspace. This limitation can disrupt training dynamics and require a full-rank warm start to mitigate the impact. In this paper, we introduce a new method inspired by a phenomenon we formally prove: as training progresses, the rank of the estimated layer gradients gradually decreases, and asymptotically approaches rank one. Leveraging this, our approach involves adaptively reducing the rank of the gradients during Adam optimization steps, using an efficient online-updating low-rank projections rule. We further present a randomized SVD scheme for efficiently finding the projection matrix. Our technique enables full-parameter fine-tuning with adaptive low-rank gradient updates, significantly reducing overall memory requirements during training compared to state-of-the-art methods while improving model performance in both pretraining and fine-tuning. Finally, we provide a convergence analysis of our method and demonstrate its merits for training and fine-tuning language and biological foundation models.
Sparse Binarization for Fast Keyword Spotting
Jun 09, 2024



With the increasing prevalence of voice-activated devices and applications, keyword spotting (KWS) models enable users to interact with technology hands-free, enhancing convenience and accessibility in various contexts. Deploying KWS models on edge devices, such as smartphones and embedded systems, offers significant benefits for real-time applications, privacy, and bandwidth efficiency. However, these devices often possess limited computational power and memory. This necessitates optimizing neural network models for efficiency without significantly compromising their accuracy. To address these challenges, we propose a novel keyword-spotting model based on sparse input representation followed by a linear classifier. The model is four times faster than the previous state-of-the-art edge device-compatible model with better accuracy. We show that our method is also more robust in noisy environments while being fast. Our code is available at: https://github.com/jsvir/sparknet.
Self Supervised Correlation-based Permutations for Multi-View Clustering
Feb 26, 2024



Fusing information from different modalities can enhance data analysis tasks, including clustering. However, existing multi-view clustering (MVC) solutions are limited to specific domains or rely on a suboptimal and computationally demanding two-stage procedure of representation and clustering. We propose an end-to-end deep learning-based MVC framework for general data (image, tabular, etc.). Our approach involves learning meaningful fused data representations with a novel permutation-based canonical correlation objective. Concurrently, we learn cluster assignments by identifying consistent pseudo-labels across multiple views. We demonstrate the effectiveness of our model using ten MVC benchmark datasets. Theoretically, we show that our model approximates the supervised linear discrimination analysis (LDA) representation. Additionally, we provide an error bound induced by false-pseudo label annotations.
Interpretable Deep Clustering
Jun 07, 2023



Clustering is a fundamental learning task widely used as a first step in data analysis. For example, biologists often use cluster assignments to analyze genome sequences, medical records, or images. Since downstream analysis is typically performed at the cluster level, practitioners seek reliable and interpretable clustering models. We propose a new deep-learning framework that predicts interpretable cluster assignments at the instance and cluster levels. First, we present a self-supervised procedure to identify a subset of informative features from each data point. Then, we design a model that predicts cluster assignments and a gate matrix that leads to cluster-level feature selection. We show that the proposed method can reliably predict cluster assignments using synthetic and real data. Furthermore, we verify that our model leads to interpretable results at a sample and cluster level.
SG-VAD: Stochastic Gates Based Speech Activity Detection
Oct 28, 2022



We propose a novel voice activity detection (VAD) model in a low-resource environment. Our key idea is to model VAD as a denoising task, and construct a network that is designed to identify nuisance features for a speech classification task. We train the model to simultaneously identify irrelevant features while predicting the type of speech event. Our model contains only 7.8K parameters, outperforms the previously proposed methods on the AVA-Speech evaluation set, and provides comparative results on the HAVIC dataset. We present its architecture, experimental results, and ablation study on the model's components. We publish the code and the models here https://www.github.com/jsvir/vad.
Single Independent Component Recovery and Applications
Oct 12, 2021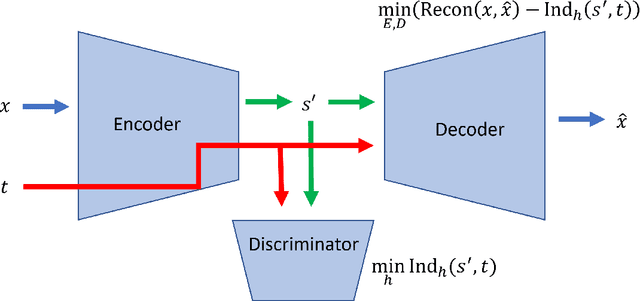
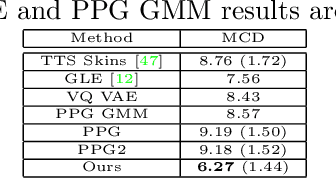
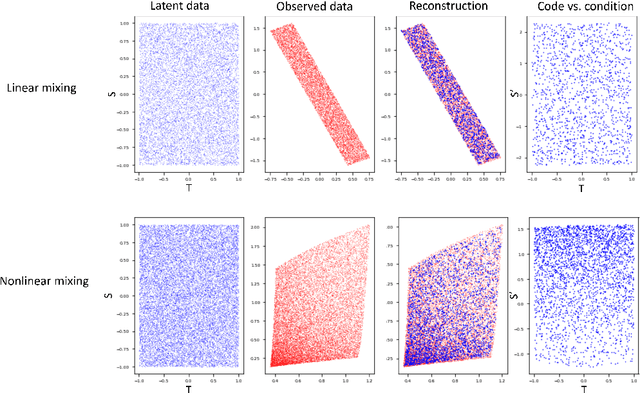
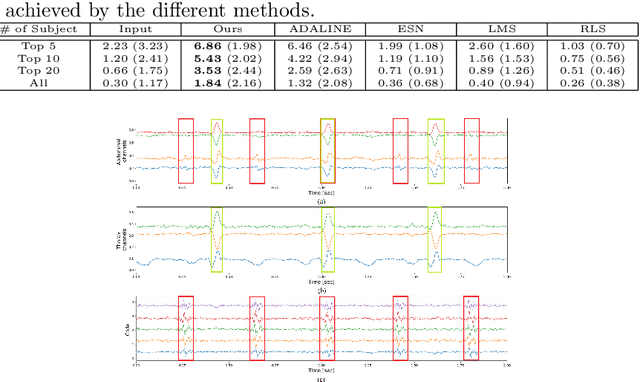
Latent variable discovery is a central problem in data analysis with a broad range of applications in applied science. In this work, we consider data given as an invertible mixture of two statistically independent components, and assume that one of the components is observed while the other is hidden. Our goal is to recover the hidden component. For this purpose, we propose an autoencoder equipped with a discriminator. Unlike the standard nonlinear ICA problem, which was shown to be non-identifiable, in the special case of ICA we consider here, we show that our approach can recover the component of interest up to entropy-preserving transformation. We demonstrate the performance of the proposed approach on several datasets, including image synthesis, voice cloning, and fetal ECG extraction.
Deep Unsupervised Feature Selection by Discarding Nuisance and Correlated Features
Oct 11, 2021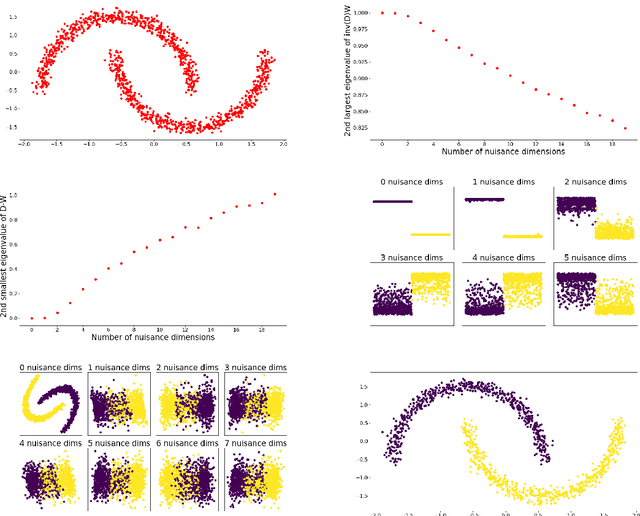
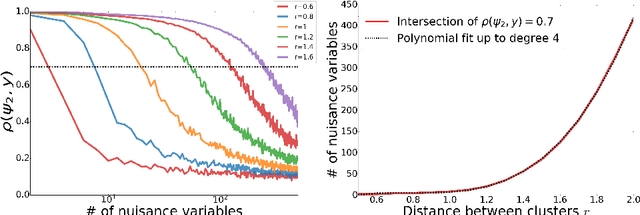
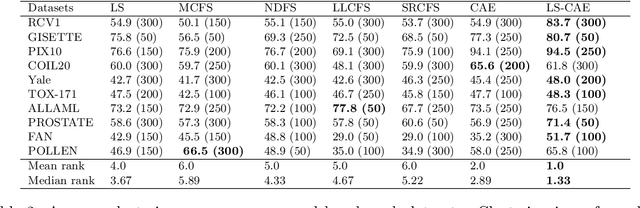
Modern datasets often contain large subsets of correlated features and nuisance features, which are not or loosely related to the main underlying structures of the data. Nuisance features can be identified using the Laplacian score criterion, which evaluates the importance of a given feature via its consistency with the Graph Laplacians' leading eigenvectors. We demonstrate that in the presence of large numbers of nuisance features, the Laplacian must be computed on the subset of selected features rather than on the complete feature set. To do this, we propose a fully differentiable approach for unsupervised feature selection, utilizing the Laplacian score criterion to avoid the selection of nuisance features. We employ an autoencoder architecture to cope with correlated features, trained to reconstruct the data from the subset of selected features. Building on the recently proposed concrete layer that allows controlling for the number of selected features via architectural design, simplifying the optimization process. Experimenting on several real-world datasets, we demonstrate that our proposed approach outperforms similar approaches designed to avoid only correlated or nuisance features, but not both. Several state-of-the-art clustering results are reported.
Deep Ordinal Regression using Optimal Transport Loss and Unimodal Output Probabilities
Nov 15, 2020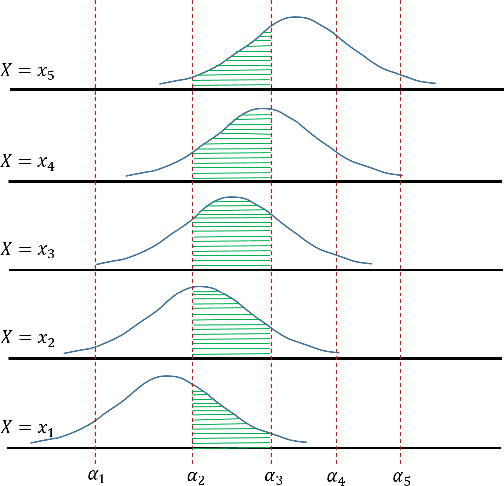
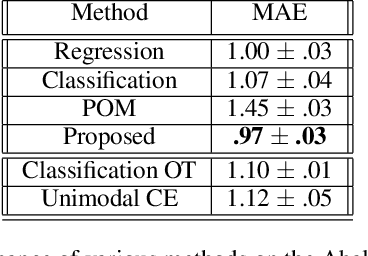
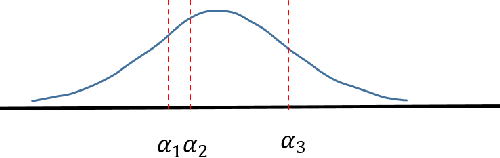
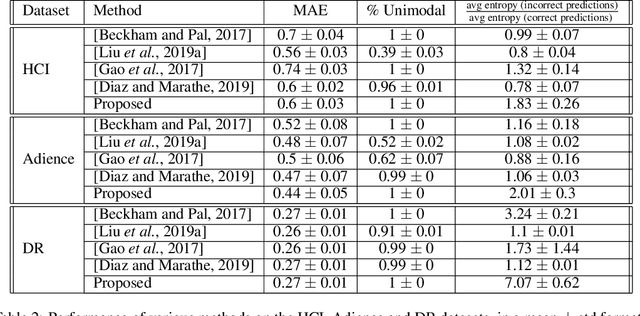
We propose a framework for deep ordinal regression, based on unimodal output distribution and optimal transport loss. Despite being seemingly appropriate, in many recent works the unimodality requirement is either absent, or implemented using soft targets, which do not guarantee unimodal outputs at inference. In addition, we argue that the standard maximum likelihood objective is not suitable for ordinal regression problems, and that optimal transport is better suited for this task, as it naturally captures the order of the classes. Inspired by the well-known Proportional Odds model, we propose to modify its design by using an architectural mechanism which guarantees that the model output distribution will be unimodal. We empirically analyze the different components of our propose approach and demonstrate their contribution to the performance of the model. Experimental results on three real-world datasets demonstrate that our proposed approach performs on par with several recently proposed deep learning approaches for deep ordinal regression with unimodal output probabilities, while having guarantee on the output unimodality. In addition, we demonstrate that the level of prediction uncertainty of the model correlates with its accuracy.