 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Performance-Improving Code Edits
Feb 21, 2023The waning of Moore's Law has shifted the focus of the tech industry towards alternative methods for continued performance gains. While optimizing compilers are a standard tool to help increase program efficiency, programmers continue to shoulder much responsibility in crafting and refactoring code with better performance characteristics. In this paper, we investigate the ability of large language models (LLMs) to suggest functionally correct, performance improving code edits. We hypothesize that language models can suggest such edits in ways that would be impractical for static analysis alone. We investigate these questions by curating a large-scale dataset of Performance-Improving Edits, PIE. PIE contains trajectories of programs, where a programmer begins with an initial, slower version and iteratively makes changes to improve the program's performance. We use PIE to evaluate and improve the capacity of large language models. Specifically, use examples from PIE to fine-tune multiple variants of CODEGEN, a billion-scale Transformer-decoder model. Additionally, we use examples from PIE to prompt OpenAI's CODEX using a few-shot prompting. By leveraging PIE, we find that both CODEX and CODEGEN can generate performance-improving edits, with speedups of more than 2.5x for over 25% of the programs, for C++ and Python, even after the C++ programs were compiled using the O3 optimization level. Crucially, we show that PIE allows CODEGEN, an open-sourced and 10x smaller model than CODEX, to match the performance of CODEX on this challenging task. Overall, this work opens new doors for creating systems and methods that can help programmers write efficient code.
CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code
Feb 10, 2023
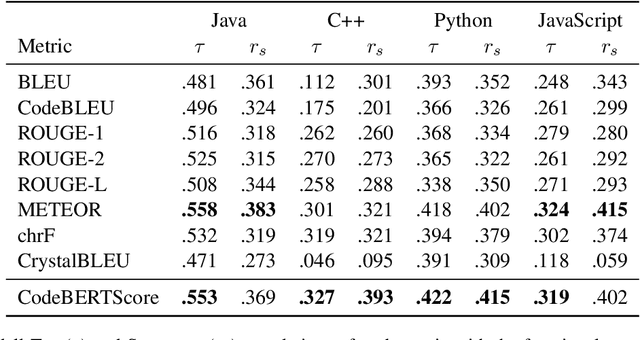
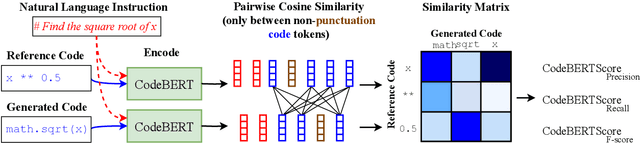
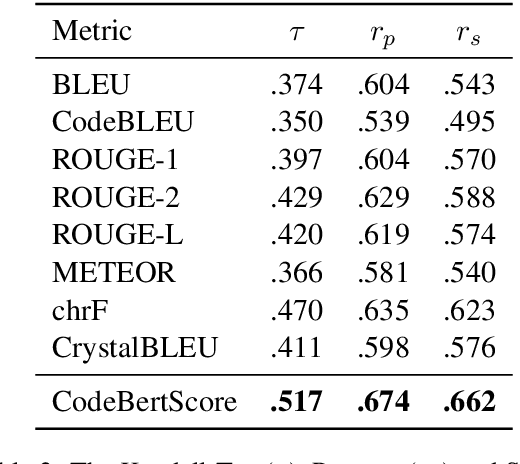
Since the rise of neural models of code that can generate long expressions and statements rather than a single next-token, one of the major problems has been reliably evaluating their generated output. In this paper, we propose CodeBERTScore: an automatic evaluation metric for code generation, which builds on BERTScore (Zhang et al., 2020). Instead of measuring exact token matching as BLEU, CodeBERTScore computes a soft similarity score between each token in the generated code and in the reference code, using the contextual encodings of large pretrained models. Further, instead of encoding only the generated tokens as in BERTScore, CodeBERTScore also encodes the programmatic context surrounding the generated code. We perform an extensive evaluation of CodeBERTScore across four programming languages. We find that CodeBERTScore achieves a higher correlation with human preference and with functional correctness than all existing metrics. That is, generated code that receives a higher score by CodeBERTScore is more likely to be preferred by humans, as well as to function correctly when executed. Finally, while CodeBERTScore can be used with a multilingual CodeBERT as its base model, we release five language-specific pretrained models to use with our publicly available code at https://github.com/neulab/code-bert-score . Our language-specific models have been downloaded more than 25,000 times from the Huggingface Hub.
Why do Nearest Neighbor Language Models Work?
Jan 17, 2023



Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
PAL: Program-aided Language Models
Nov 18, 2022



Large language models (LLMs) have recently demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks when provided with a few examples at test time (few-shot prompting). Much of this success can be attributed to prompting methods for reasoning, such as chain-of-thought, that employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is correctly decomposed. We present Program-Aided Language models (PaL): a new method that uses the LLM to understand natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a programmatic runtime such as a Python interpreter. With PaL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We experiment with 12 reasoning tasks from BIG-Bench Hard and other benchmarks, including mathematical reasoning, symbolic reasoning, and algorithmic problems. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models, and we set new state-of-the-art results in all 12 benchmarks. For example, PaL using Codex achieves state-of-the-art few-shot accuracy on the GSM benchmark of math word problems when the model is allowed only a single decoding, surpassing PaLM-540B with chain-of-thought prompting by an absolute 8% .In three reasoning tasks from the BIG-Bench Hard benchmark, PaL outperforms CoT by 11%. On GSM-hard, a more challenging version of GSM that we create, PaL outperforms chain-of-thought by an absolute 40%.
Language Models of Code are Few-Shot Commonsense Learners
Oct 13, 2022
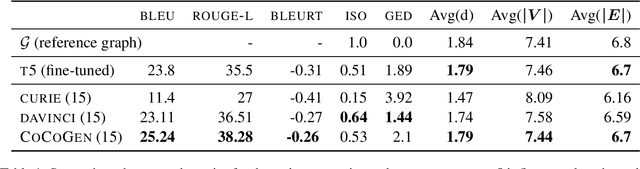

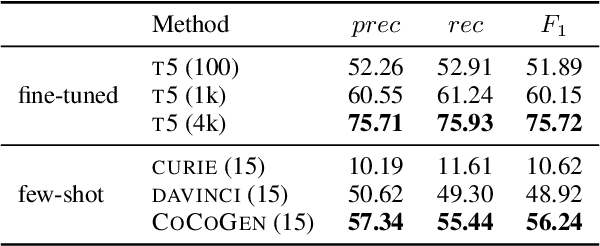
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event -- or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches ``serialize'' the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the few-shot setting.
Oversquashing in GNNs through the lens of information contraction and graph expansion
Aug 06, 2022The quality of signal propagation in message-passing graph neural networks (GNNs) strongly influences their expressivity as has been observed in recent works. In particular, for prediction tasks relying on long-range interactions, recursive aggregation of node features can lead to an undesired phenomenon called "oversquashing". We present a framework for analyzing oversquashing based on information contraction. Our analysis is guided by a model of reliable computation due to von Neumann that lends a new insight into oversquashing as signal quenching in noisy computation graphs. Building on this, we propose a graph rewiring algorithm aimed at alleviating oversquashing. Our algorithm employs a random local edge flip primitive motivated by an expander graph construction. We compare the spectral expansion properties of our algorithm with that of an existing curvature-based non-local rewiring strategy. Synthetic experiments show that while our algorithm in general has a slower rate of expansion, it is overall computationally cheaper, preserves the node degrees exactly and never disconnects the graph.
DocCoder: Generating Code by Retrieving and Reading Docs
Jul 13, 2022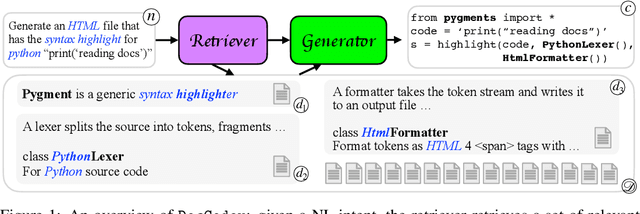
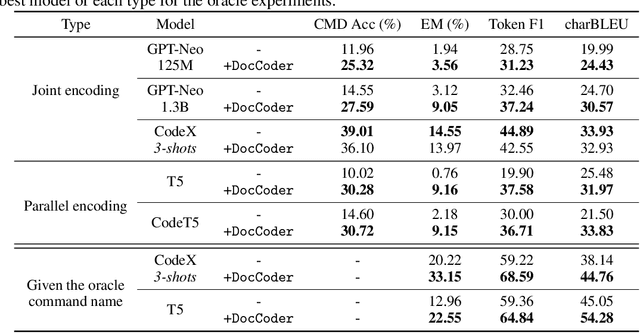
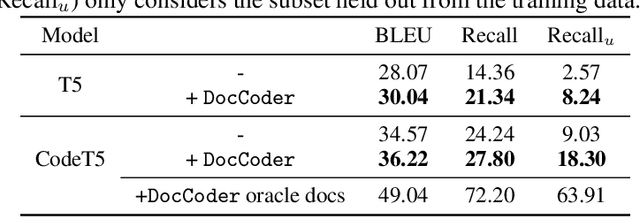
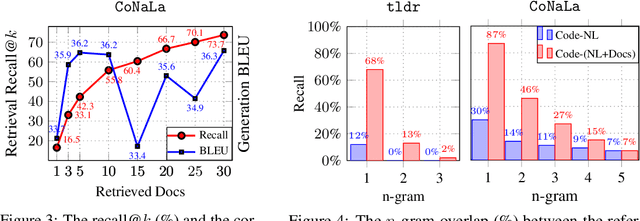
Natural-language-to-code models learn to generate a code snippet given a natural language (NL) intent. However, the rapid growth of both publicly available and proprietary libraries and functions makes it impossible to cover all APIs using training examples, as new libraries and functions are introduced daily. Thus, existing models inherently cannot generalize to using unseen functions and libraries merely through incorporating them into the training data. In contrast, when human programmers write programs, they frequently refer to textual resources such as code manuals, documentation, and tutorials, to explore and understand available library functionality. Inspired by this observation, we introduce DocCoder: an approach that explicitly leverages code manuals and documentation by (1) retrieving the relevant documentation given the NL intent, and (2) generating the code based on the NL intent and the retrieved documentation. Our approach is general, can be applied to any programming language, and is agnostic to the underlying neural model. We demonstrate that DocCoder consistently improves NL-to-code models: DocCoder achieves 11x higher exact match accuracy than strong baselines on a new Bash dataset tldr; on the popular Python CoNaLa benchmark, DocCoder improves over strong baselines by 1.65 BLEU.
A Systematic Evaluation of Large Language Models of Code
Mar 01, 2022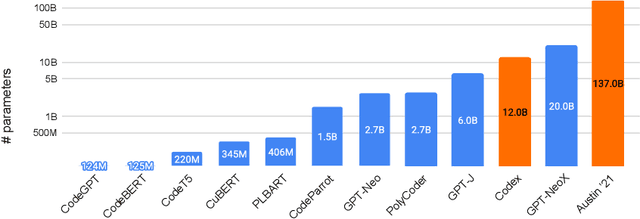
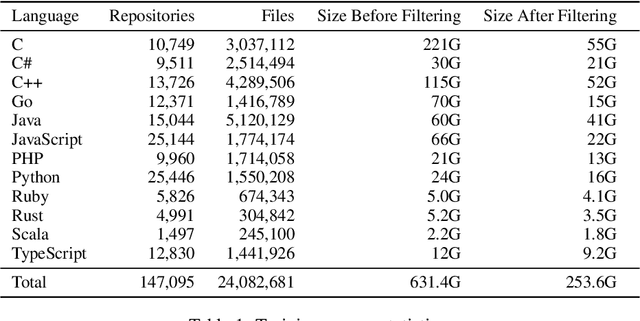

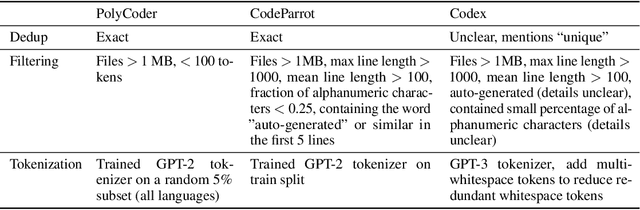
Large language models (LMs) of code have recently shown tremendous promise in completing code and synthesizing code from natural language descriptions. However, the current state-of-the-art code LMs (e.g., Codex (Chen et al., 2021)) are not publicly available, leaving many questions about their model and data design decisions. We aim to fill in some of these blanks through a systematic evaluation of the largest existing models: Codex, GPT-J, GPT-Neo, GPT-NeoX-20B, and CodeParrot, across various programming languages. Although Codex itself is not open-source, we find that existing open-source models do achieve close results in some programming languages, although targeted mainly for natural language modeling. We further identify an important missing piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code. We release a new model, PolyCoder, with 2.7B parameters based on the GPT-2 architecture, which was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex. Our trained models are open-source and publicly available at https://github.com/VHellendoorn/Code-LMs, which enables future research and application in this area.
Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
Jan 28, 2022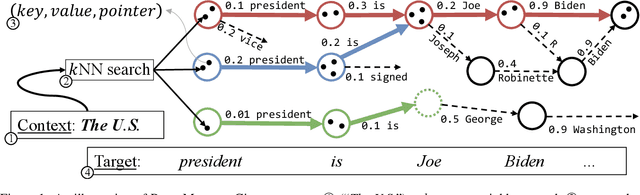
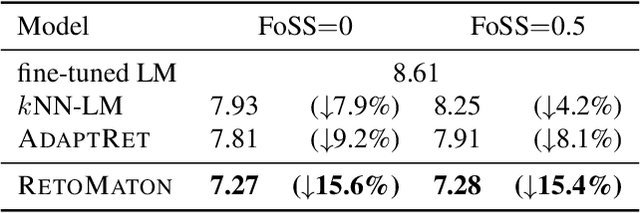
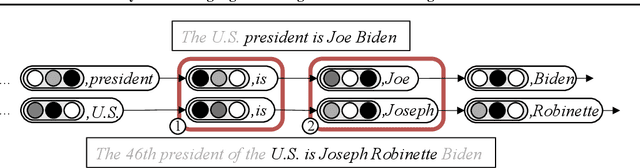

Retrieval-based language models (R-LM) model the probability of natural language text by combining a standard language model (LM) with examples retrieved from an external datastore at test time. While effective, a major bottleneck of using these models in practice is the computationally costly datastore search, which can be performed as frequently as every time step. In this paper, we present RetoMaton -- retrieval automaton -- which approximates the datastore search, based on (1) clustering of entries into "states", and (2) state transitions from previous entries. This effectively results in a weighted finite automaton built on top of the datastore, instead of representing the datastore as a flat list. The creation of the automaton is unsupervised, and a RetoMaton can be constructed from any text collection: either the original training corpus or from another domain. Traversing this automaton at inference time, in parallel to the LM inference, reduces its perplexity, or alternatively saves up to 83% of the nearest neighbor searches over kNN-LM (Khandelwal et al., 2020), without hurting perplexity.
How Attentive are Graph Attention Networks?
May 30, 2021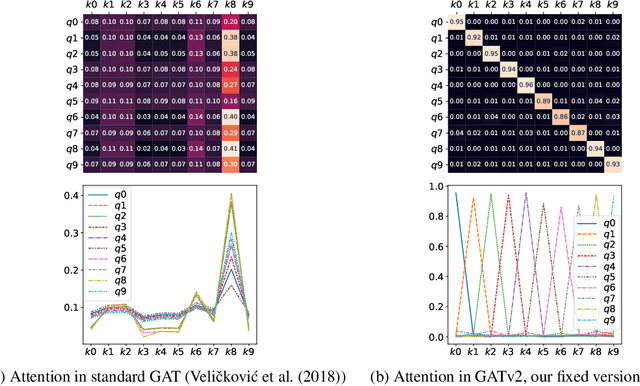
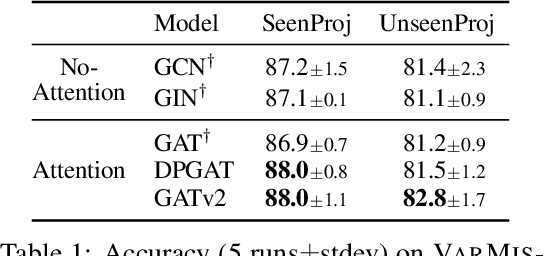
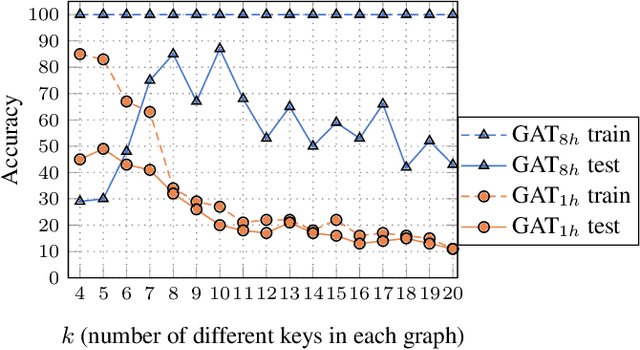
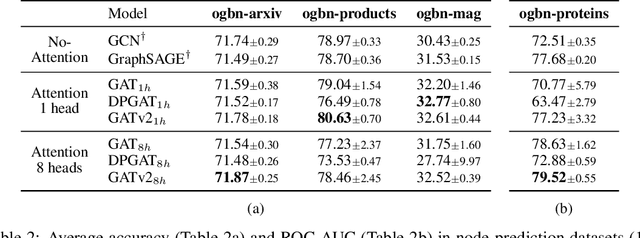
Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs. In GAT, every node attends to its neighbors given its own representation as the query. However, in this paper we show that GATs can only compute a restricted kind of attention where the ranking of attended nodes is unconditioned on the query node. We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention. Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data. To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2: a dynamic graph attention variant that is strictly more expressive than GAT. We perform an extensive evaluation and show that GATv2 outperforms GAT across 11 OGB and other benchmarks while we match their parametric costs. Our code is available at https://github.com/tech-srl/how_attentive_are_gats .