 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint)
Oct 01, 2023



Liveness Detection (LivDet) is an international competition series open to academia and industry with the objec-tive to assess and report state-of-the-art in Presentation Attack Detection (PAD). LivDet-2023 Noncontact Fingerprint is the first edition of the noncontact fingerprint-based PAD competition for algorithms and systems. The competition serves as an important benchmark in noncontact-based fingerprint PAD, offering (a) independent assessment of the state-of-the-art in noncontact-based fingerprint PAD for algorithms and systems, and (b) common evaluation protocol, which includes finger photos of a variety of Presentation Attack Instruments (PAIs) and live fingers to the biometric research community (c) provides standard algorithm and system evaluation protocols, along with the comparative analysis of state-of-the-art algorithms from academia and industry with both old and new android smartphones. The winning algorithm achieved an APCER of 11.35% averaged overall PAIs and a BPCER of 0.62%. The winning system achieved an APCER of 13.0.4%, averaged over all PAIs tested over all the smartphones, and a BPCER of 1.68% over all smartphones tested. Four-finger systems that make individual finger-based PAD decisions were also tested. The dataset used for competition will be available 1 to all researchers as per data share protocol
Twins Recognition Using Hierarchical Score Level Fusion
Oct 27, 2019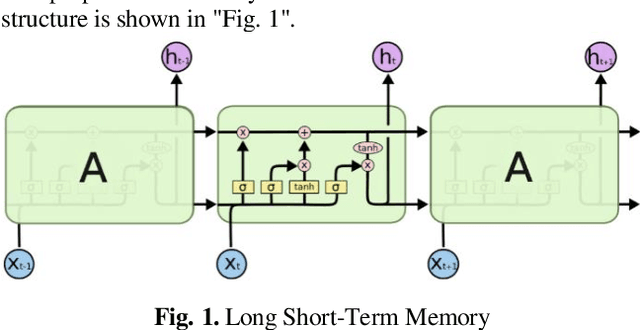
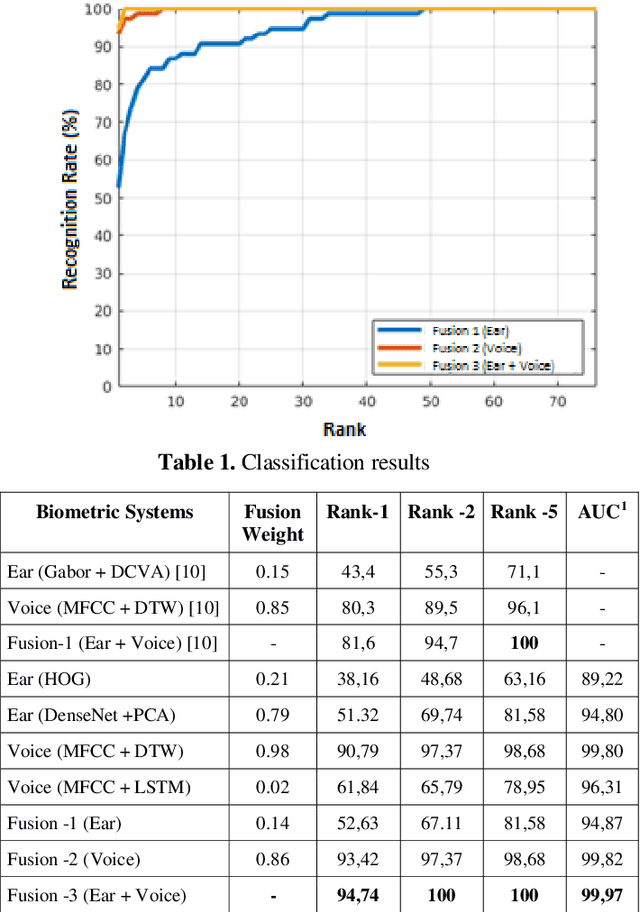
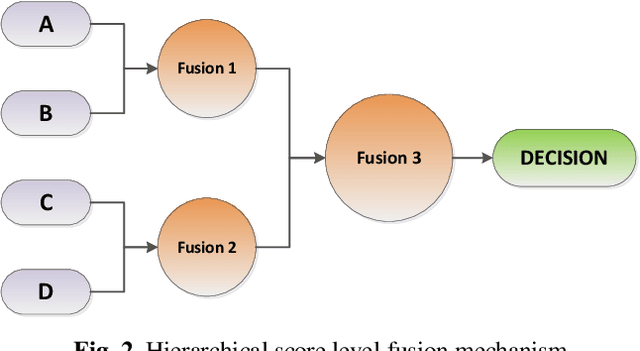
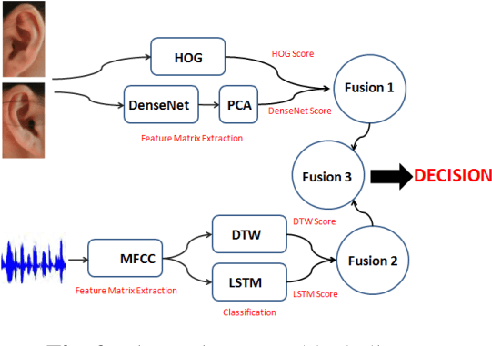
With the development of technology, the usage areas and importance of biometric systems have started to increase. Since the characteristics of each person are different from each other, a single model biometric system can yield successful results. However, because the characteristics of twin people are very close to each other, multiple biometric systems including multiple characteristics of individuals will be more appropriate and will increase the recognition rate. In this study, a multiple biometric recognition system consisting of a combination of multiple algorithms and multiple models was developed to distinguish people from other people and their twins. Ear and voice biometric data were used for the multimodal model and 38 pair of twin ear images and sound recordings were used in the data set. Sound and ear recognition rates were obtained using classical (hand-crafted) and deep learning algorithms. The results obtained were combined with the hierarchical score level fusion method to achieve a success rate of 94.74% in rank-1 and 100% in rank -2.
Twins Recognition with Multi Biometric System: Handcrafted-Deep Learning Based Multi Algorithm with Voice-Ear Recognition Based Multi Modal
Mar 15, 2019With the development of technology, the usage areas and importance of biometric systems have started to increase. Since the characteristics of each person are different from each other, a single model biometric system can yield successful results. However, because the characteristics of twin people are very close to each other, multiple biometric systems including multiple characteristics of individuals will be more appropriate and will increase the recognition rate. In this study, a multiple biometric recognition system consisting of a combination of multiple algorithms and multiple models was developed to distinguish people from other people and their twins. Ear and voice biometric data were used for the multimodal model and 38 pair of twin ear images and sound recordings were used in the data set. Sound and ear recognition rates were obtained using classical (hand-crafted) and deep learning algorithms. The results obtained were combined with the score level fusion method to achieve a success rate of 94.74% in rank-1 and 100% in rank -2.
A Multi-Biometrics for Twins Identification Based Speech and Ear
Jan 27, 2018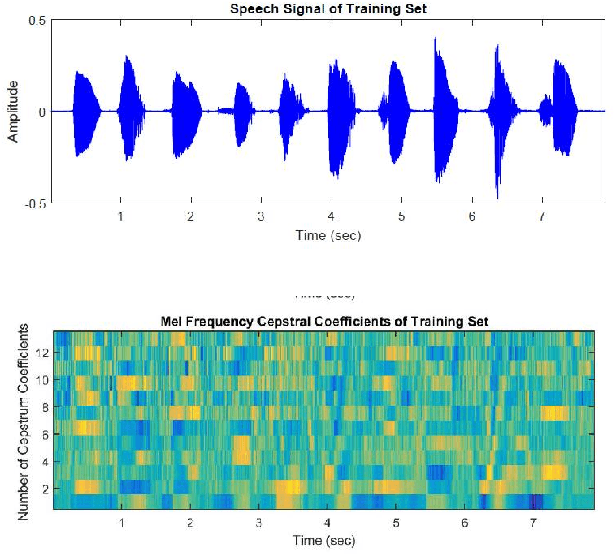
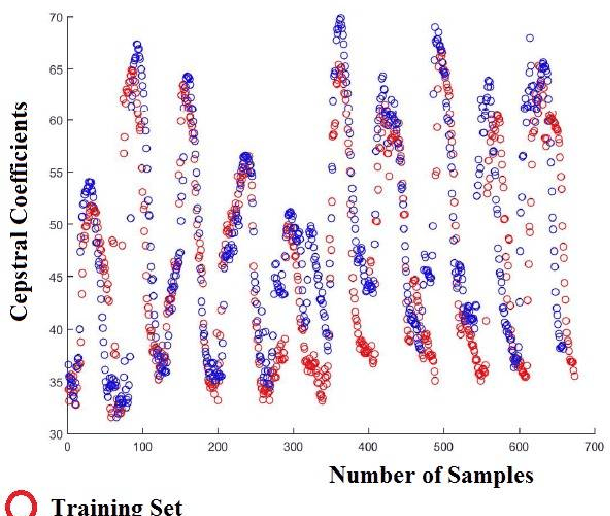
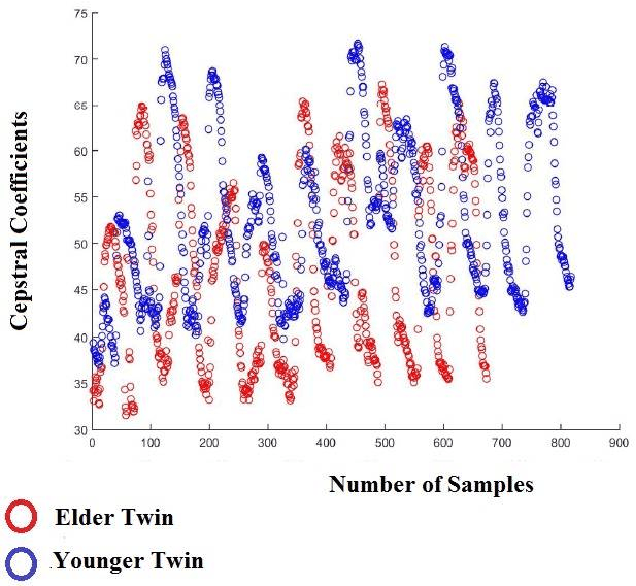
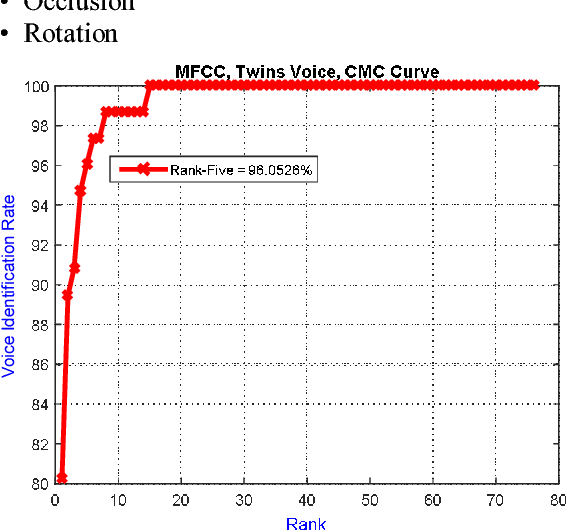
The development of technology biometrics becomes crucial more. To define human characteristic biometric systems are used but because of inability of traditional biometric systems to recognize twins, multimodal biometric systems are developed. In this study a multimodal biometric recognition system is proposed to recognize twins from each other and from the other people by using image and speech data. The speech or image data can be enough to recognize people from each other but twins cannot be distinguished with one of these data. Therefore a robust recognition system with the combine of speech and ear images is needed. As database, the photos and speech data of 39 twins are used. For speech recognition MFCC and DTW algorithms are used. Also, Gabor filter and DCVA algorithms are used for ear identification. Multi-biometrics success rate is increased by making matching score level fusion. Especially, rank-5 is reached 100%. We think that speech and ear can be complementary. Therefore, it is result that multi-biometrics based speech and ear is effective for human identifications.
Ear Recognition With Score-Level Fusion Based On CMC In Long-Wave Infrared Spectrum
Jan 27, 2018
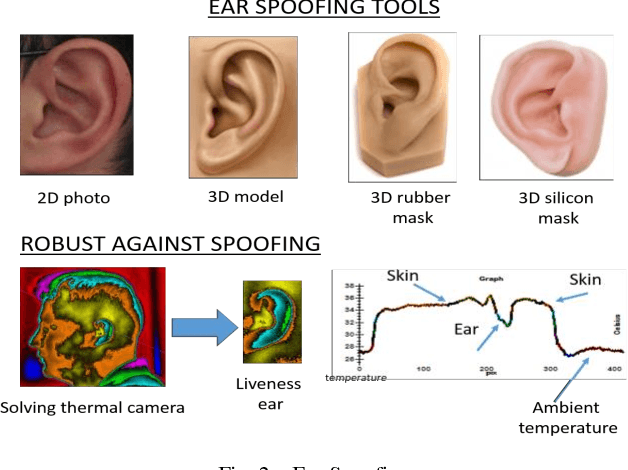
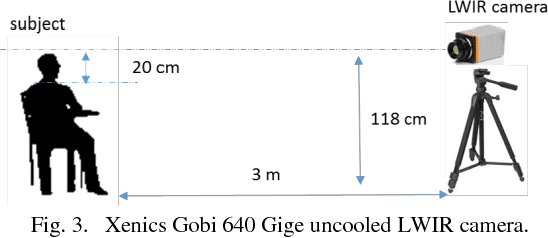
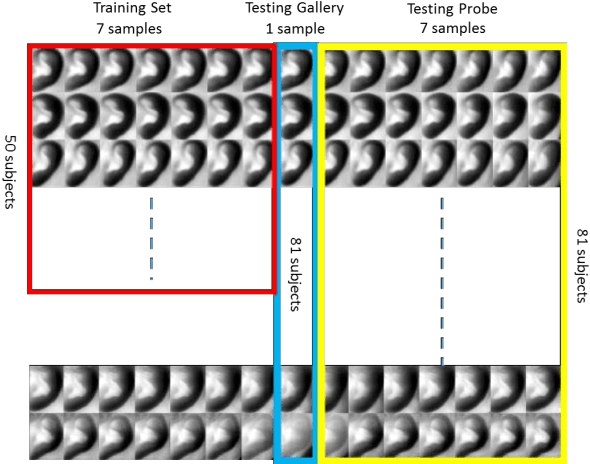
Only a few studies have been reported regarding human ear recognition in long wave infrared band. Thus, we have created ear database based on long wave infrared band. We have called that the database is long wave infrared band MIDAS consisting of 2430 records of 81 subjects. Thermal band provides seamless operation both night and day, robust against spoofing with understanding live ear and invariant to illumination conditions for human ear recognition. We have proposed to use different algorithms to reveal the distinctive features. Then, we have reduced the number of dimensions using subspace methods. Finally, the dimension of data is reduced in accordance with the classifier methods. After this, the decision is determined by the best sores or combining some of the best scores with matching fusion. The results have showed that the fusion technique was successful. We have reached 97.71% for rank-1 with 567 test probes. Furthermore, we have defined the perfect rank which is rank number when recognition rate reaches 100% in cumulative matching curve. This evaluation is important for especially forensics, for example corpse identification, criminal investigation etc.