 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwins Recognition Using Hierarchical Score Level Fusion
Oct 27, 2019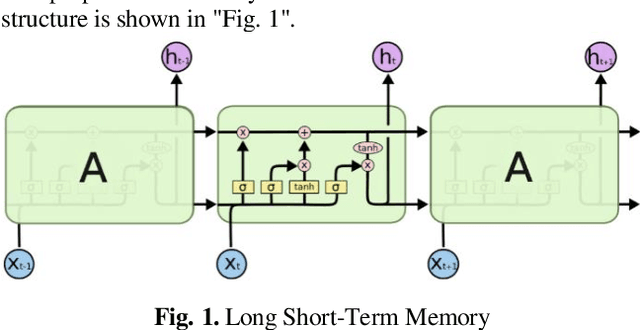
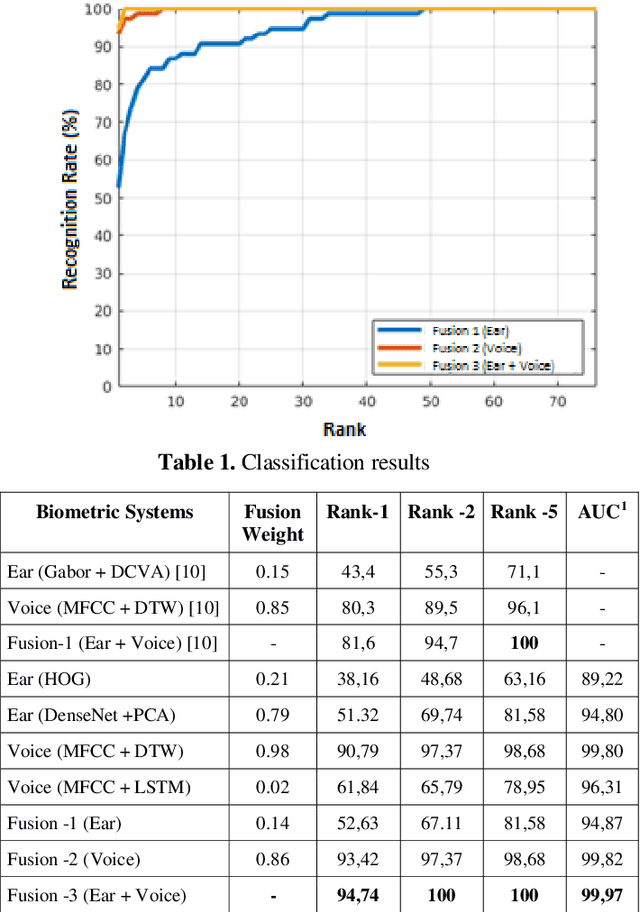
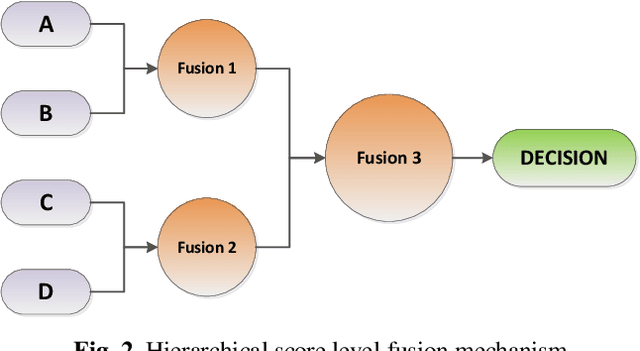
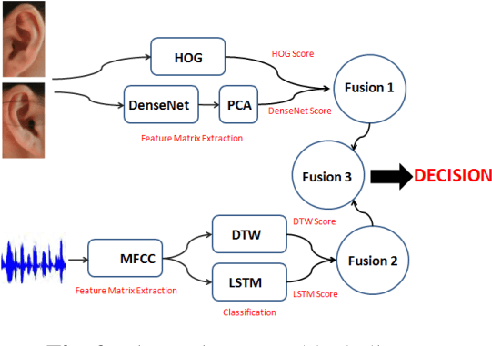
With the development of technology, the usage areas and importance of biometric systems have started to increase. Since the characteristics of each person are different from each other, a single model biometric system can yield successful results. However, because the characteristics of twin people are very close to each other, multiple biometric systems including multiple characteristics of individuals will be more appropriate and will increase the recognition rate. In this study, a multiple biometric recognition system consisting of a combination of multiple algorithms and multiple models was developed to distinguish people from other people and their twins. Ear and voice biometric data were used for the multimodal model and 38 pair of twin ear images and sound recordings were used in the data set. Sound and ear recognition rates were obtained using classical (hand-crafted) and deep learning algorithms. The results obtained were combined with the hierarchical score level fusion method to achieve a success rate of 94.74% in rank-1 and 100% in rank -2.
A Multi-Biometrics for Twins Identification Based Speech and Ear
Jan 27, 2018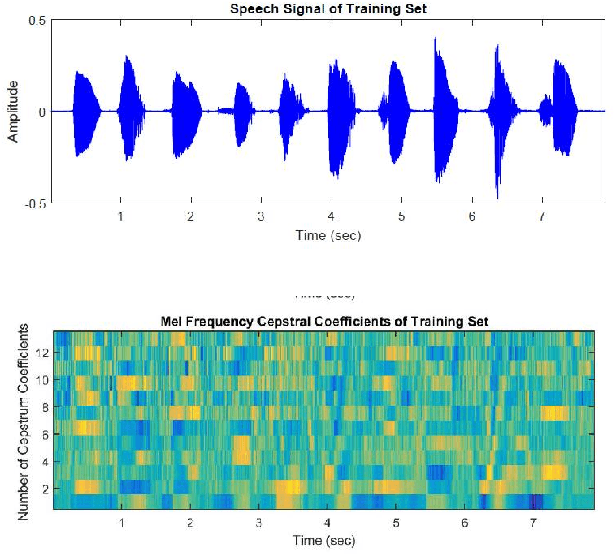
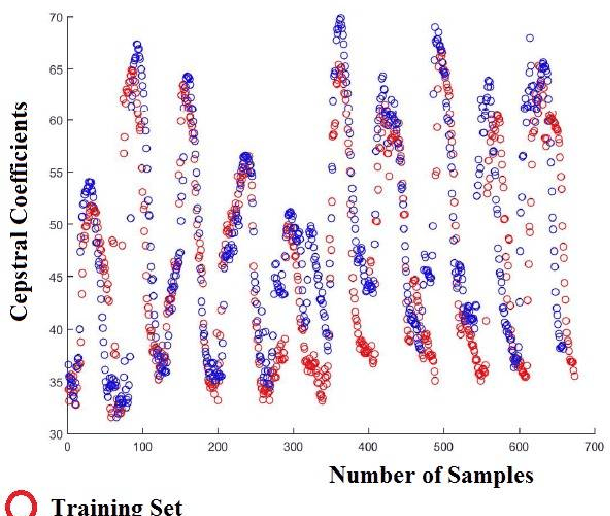
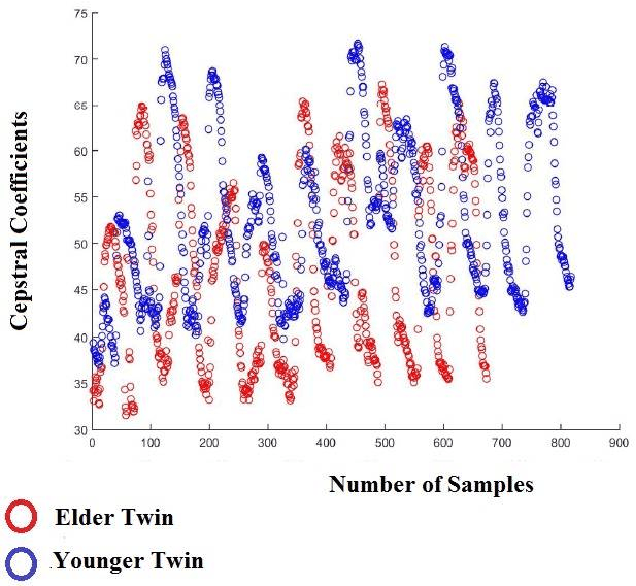
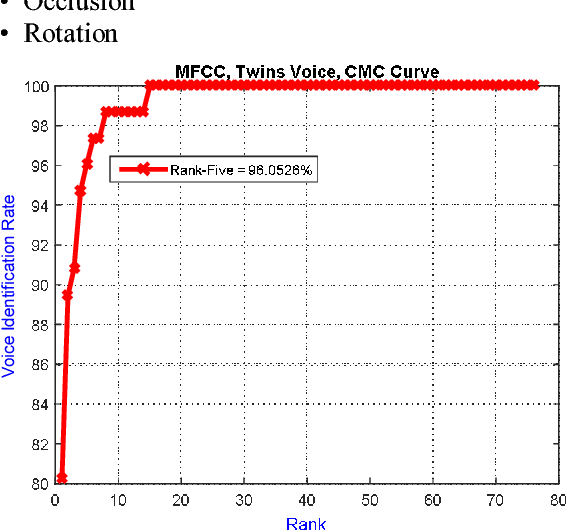
The development of technology biometrics becomes crucial more. To define human characteristic biometric systems are used but because of inability of traditional biometric systems to recognize twins, multimodal biometric systems are developed. In this study a multimodal biometric recognition system is proposed to recognize twins from each other and from the other people by using image and speech data. The speech or image data can be enough to recognize people from each other but twins cannot be distinguished with one of these data. Therefore a robust recognition system with the combine of speech and ear images is needed. As database, the photos and speech data of 39 twins are used. For speech recognition MFCC and DTW algorithms are used. Also, Gabor filter and DCVA algorithms are used for ear identification. Multi-biometrics success rate is increased by making matching score level fusion. Especially, rank-5 is reached 100%. We think that speech and ear can be complementary. Therefore, it is result that multi-biometrics based speech and ear is effective for human identifications.