 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIS: Self-Supervised Representation Learning For Writer Independent Offline Signature Verification
Feb 26, 2022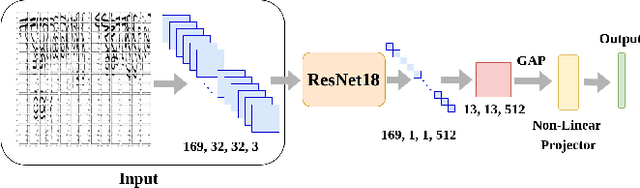

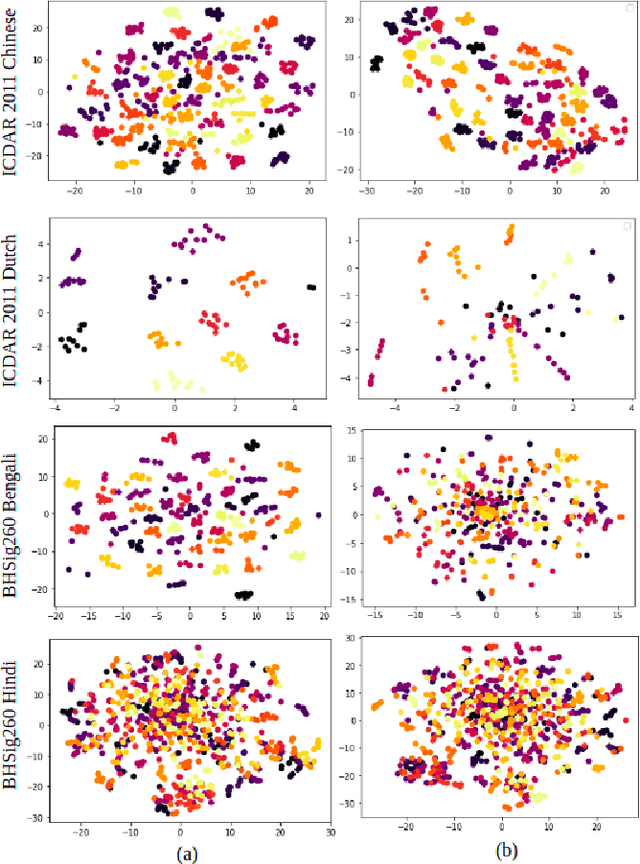
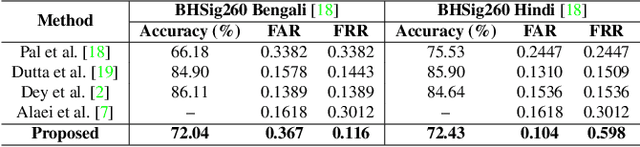
Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results.
Multi-scale Attention Guided Pose Transfer
Feb 14, 2022



Pose transfer refers to the probabilistic image generation of a person with a previously unseen novel pose from another image of that person having a different pose. Due to potential academic and commercial applications, this problem is extensively studied in recent years. Among the various approaches to the problem, attention guided progressive generation is shown to produce state-of-the-art results in most cases. In this paper, we present an improved network architecture for pose transfer by introducing attention links at every resolution level of the encoder and decoder. By utilizing such dense multi-scale attention guided approach, we are able to achieve significant improvement over the existing methods both visually and analytically. We conclude our findings with extensive qualitative and quantitative comparisons against several existing methods on the DeepFashion dataset.
DocSegTr: An Instance-Level End-to-End Document Image Segmentation Transformer
Jan 27, 2022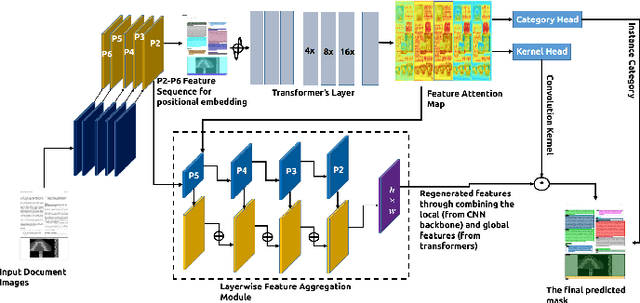
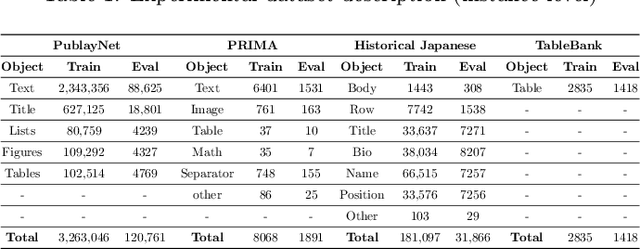

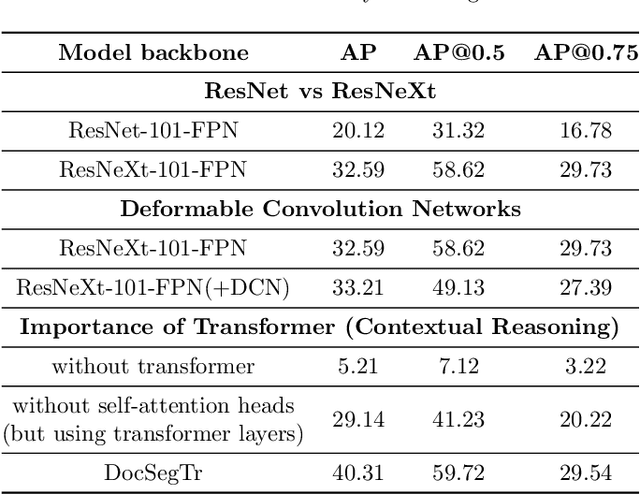
Understanding documents with rich layouts is an essential step towards information extraction. Business intelligence processes often require the extraction of useful semantic content from documents at a large scale for subsequent decision-making tasks. In this context, instance-level segmentation of different document objects(title, sections, figures, tables and so on) has emerged as an interesting problem for the document layout analysis community. To advance the research in this direction, we present a transformer-based model for end-to-end segmentation of complex layouts in document images. To our knowledge, this is the first work on transformer-based document segmentation. Extensive experimentation on the PubLayNet dataset shows that our model achieved comparable or better segmentation performance than the existing state-of-the-art approaches. We hope our simple and flexible framework could serve as a promising baseline for instance-level recognition tasks in document images.
DocEnTr: An End-to-End Document Image Enhancement Transformer
Jan 25, 2022Document images can be affected by many degradation scenarios, which cause recognition and processing difficulties. In this age of digitization, it is important to denoise them for proper usage. To address this challenge, we present a new encoder-decoder architecture based on vision transformers to enhance both machine-printed and handwritten document images, in an end-to-end fashion. The encoder operates directly on the pixel patches with their positional information without the use of any convolutional layers, while the decoder reconstructs a clean image from the encoded patches. Conducted experiments show a superiority of the proposed model compared to the state-of the-art methods on several DIBCO benchmarks. Code and models will be publicly available at: \url{https://github.com/dali92002/DocEnTR}.
SURDS: Self-Supervised Attention-guided Reconstruction and Dual Triplet Loss for Writer Independent Offline Signature Verification
Jan 25, 2022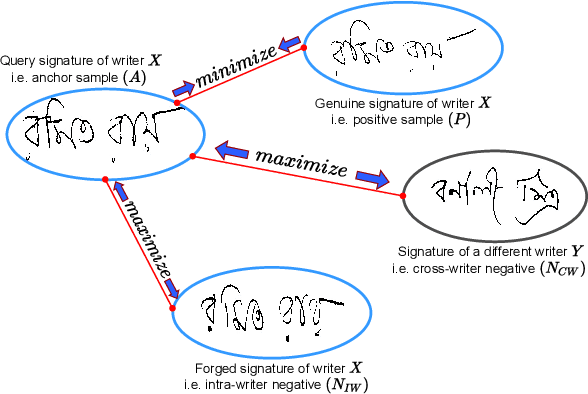

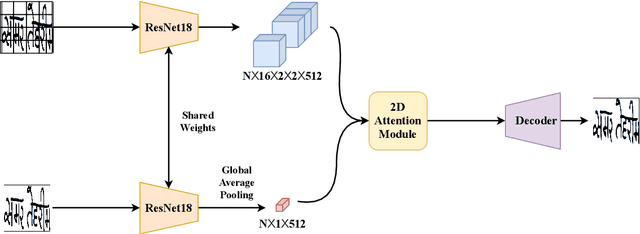
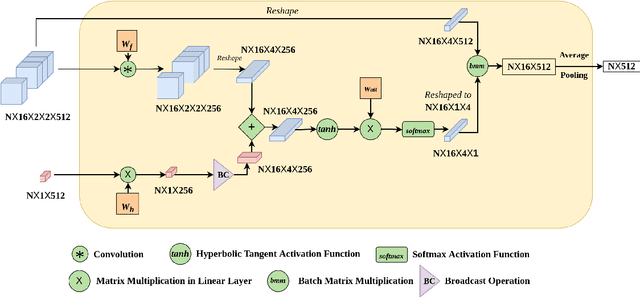
Offline Signature Verification (OSV) is a fundamental biometric task across various forensic, commercial and legal applications. The underlying task at hand is to carefully model fine-grained features of the signatures to distinguish between genuine and forged ones, which differ only in minute deformities. This makes OSV more challenging compared to other verification problems. In this work, we propose a two-stage deep learning framework that leverages self-supervised representation learning as well as metric learning for writer-independent OSV. First, we train an image reconstruction network using an encoder-decoder architecture that is augmented by a 2D spatial attention mechanism using signature image patches. Next, the trained encoder backbone is fine-tuned with a projector head using a supervised metric learning framework, whose objective is to optimize a novel dual triplet loss by sampling negative samples from both within the same writer class as well as from other writers. The intuition behind this is to ensure that a signature sample lies closer to its positive counterpart compared to negative samples from both intra-writer and cross-writer sets. This results in robust discriminative learning of the embedding space. To the best of our knowledge, this is the first work of using self-supervised learning frameworks for OSV. The proposed two-stage framework has been evaluated on two publicly available offline signature datasets and compared with various state-of-the-art methods. It is noted that the proposed method provided promising results outperforming several existing pieces of work.
MIO : Mutual Information Optimization using Self-Supervised Binary Contrastive Learning
Nov 24, 2021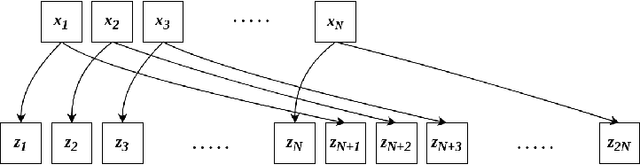
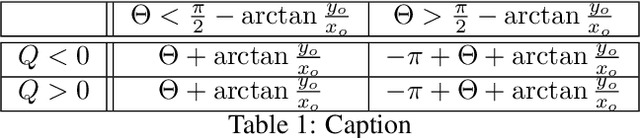
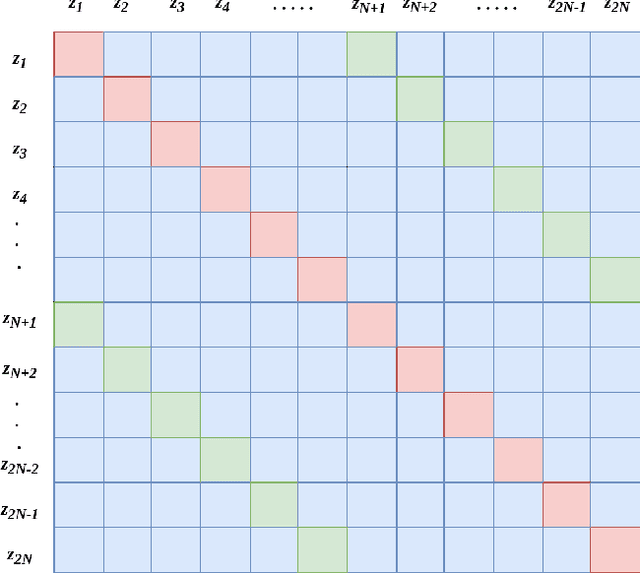
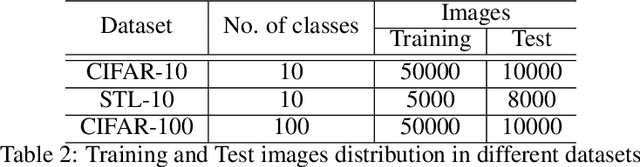
Self-supervised contrastive learning is one of the domains which has progressed rapidly over the last few years. Most of the state-of-the-art self-supervised algorithms use a large number of negative samples, momentum updates, specific architectural modifications, or extensive training to learn good representations. Such arrangements make the overall training process complex and challenging to realize analytically. In this paper, we propose a mutual information optimization based loss function for contrastive learning where we model contrastive learning into a binary classification problem to predict if a pair is positive or not. This formulation not only helps us to track the problem mathematically but also helps us to outperform existing algorithms. Unlike the existing methods that only maximize the mutual information in a positive pair, the proposed loss function optimizes the mutual information in both positive and negative pairs. We also present a mathematical expression for the parameter gradients flowing into the projector and the displacement of the feature vectors in the feature space. This helps us to get a mathematical insight into the working principle of contrastive learning. An additive $L_2$ regularizer is also used to prevent diverging of the feature vectors and to improve performance. The proposed method outperforms the state-of-the-art algorithms on benchmark datasets like STL-10, CIFAR-10, CIFAR-100. After only 250 epochs of pre-training, the proposed model achieves the best accuracy of 85.44\%, 60.75\%, 56.81\% on CIFAR-10, STL-10, CIFAR-100 datasets, respectively.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021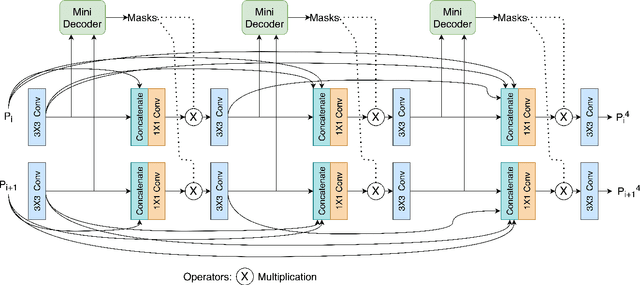
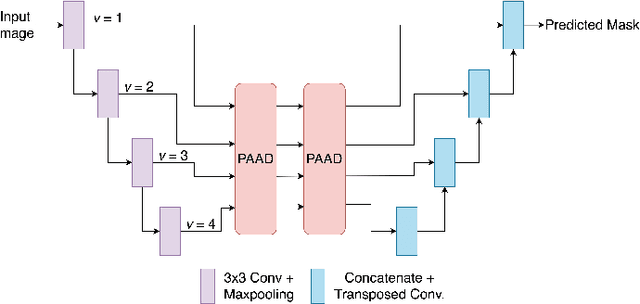
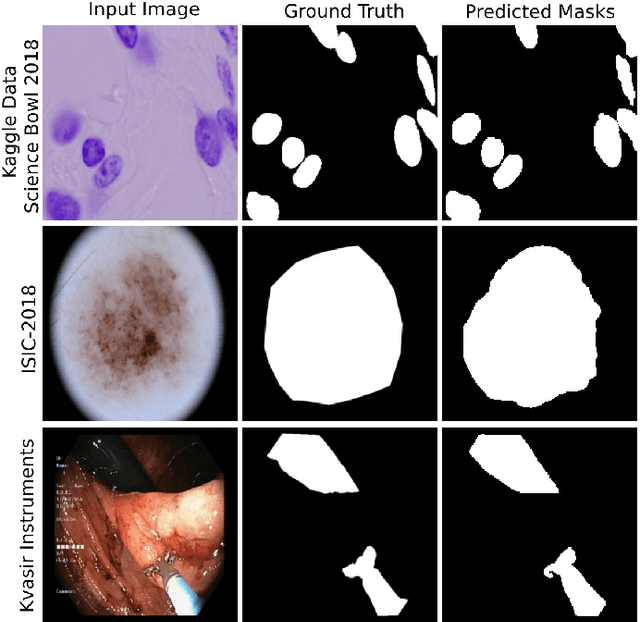
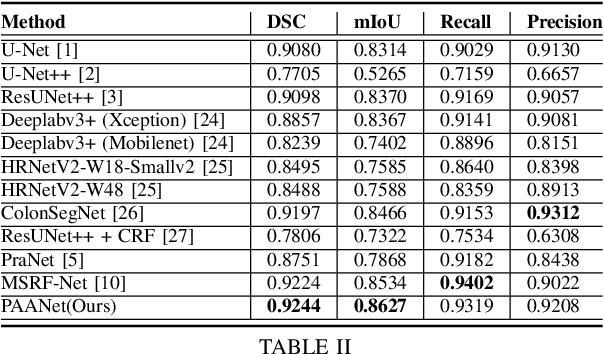
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
GMSRF-Net: An improved generalizability with global multi-scale residual fusion network for polyp segmentation
Nov 20, 2021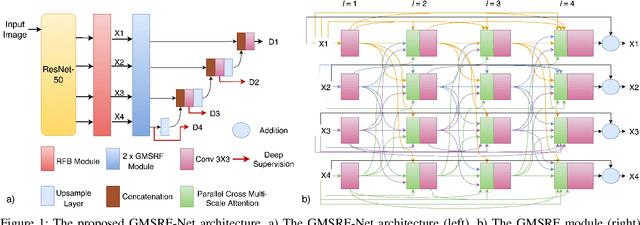
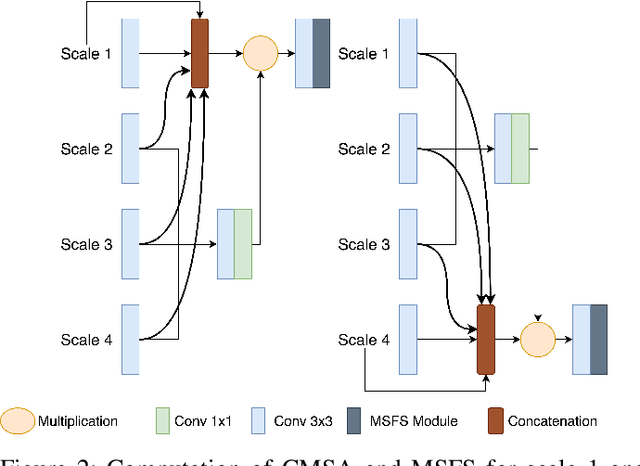
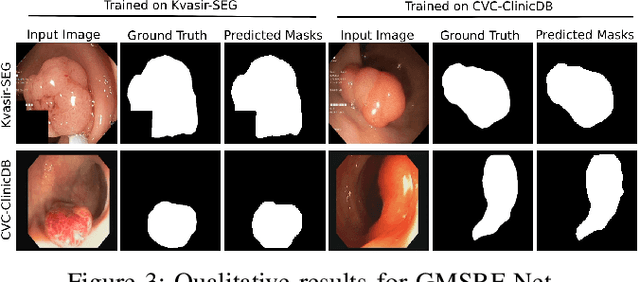
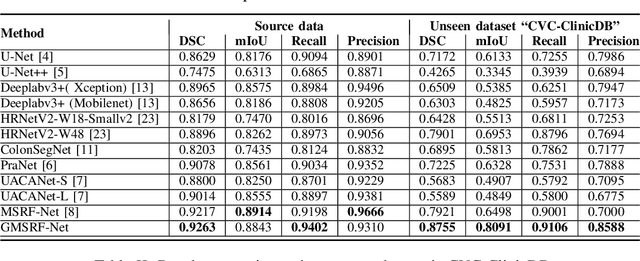
Colonoscopy is a gold standard procedure but is highly operator-dependent. Efforts have been made to automate the detection and segmentation of polyps, a precancerous precursor, to effectively minimize missed rate. Widely used computer-aided polyp segmentation systems actuated by encoder-decoder have achieved high performance in terms of accuracy. However, polyp segmentation datasets collected from varied centers can follow different imaging protocols leading to difference in data distribution. As a result, most methods suffer from performance drop and require re-training for each specific dataset. We address this generalizability issue by proposing a global multi-scale residual fusion network (GMSRF-Net). Our proposed network maintains high-resolution representations while performing multi-scale fusion operations for all resolution scales. To further leverage scale information, we design cross multi-scale attention (CMSA) and multi-scale feature selection (MSFS) modules within the GMSRF-Net. The repeated fusion operations gated by CMSA and MSFS demonstrate improved generalizability of the network. Experiments conducted on two different polyp segmentation datasets show that our proposed GMSRF-Net outperforms the previous top-performing state-of-the-art method by 8.34% and 10.31% on unseen CVC-ClinicDB and unseen Kvasir-SEG, in terms of dice coefficient.
Exploiting Multi-Scale Fusion, Spatial Attention and Patch Interaction Techniques for Text-Independent Writer Identification
Nov 20, 2021
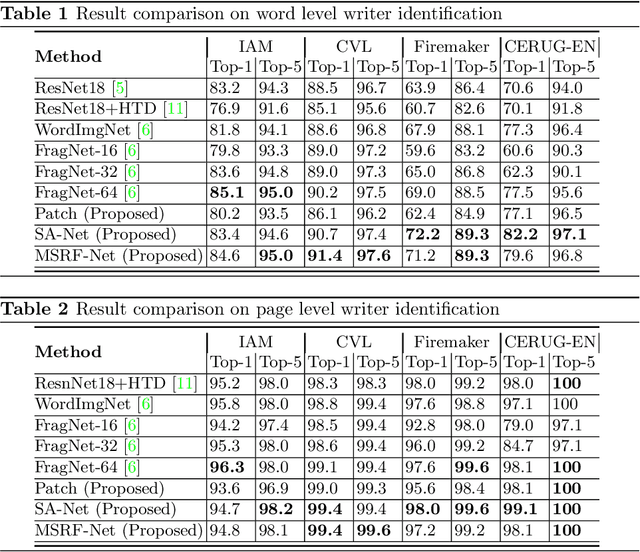
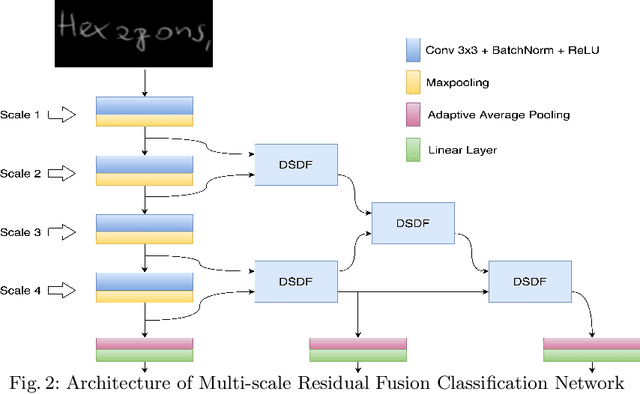
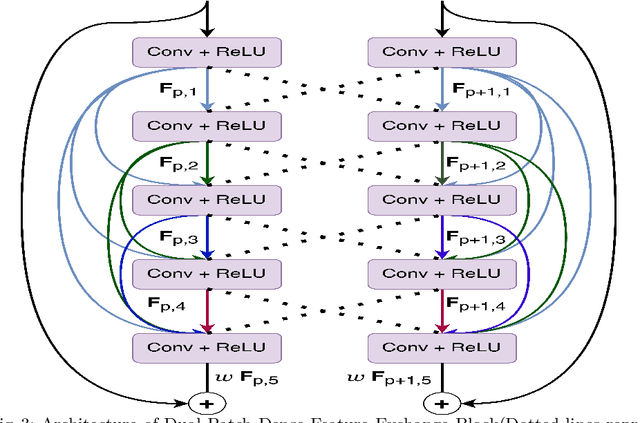
Text independent writer identification is a challenging problem that differentiates between different handwriting styles to decide the author of the handwritten text. Earlier writer identification relied on handcrafted features to reveal pieces of differences between writers. Recent work with the advent of convolutional neural network, deep learning-based methods have evolved. In this paper, three different deep learning techniques - spatial attention mechanism, multi-scale feature fusion and patch-based CNN were proposed to effectively capture the difference between each writer's handwriting. Our methods are based on the hypothesis that handwritten text images have specific spatial regions which are more unique to a writer's style, multi-scale features propagate characteristic features with respect to individual writers and patch-based features give more general and robust representations that helps to discriminate handwriting from different writers. The proposed methods outperforms various state-of-the-art methodologies on word-level and page-level writer identification methods on three publicly available datasets - CVL, Firemaker, CERUG-EN datasets and give comparable performance on the IAM dataset.
AGA-GAN: Attribute Guided Attention Generative Adversarial Network with U-Net for Face Hallucination
Nov 20, 2021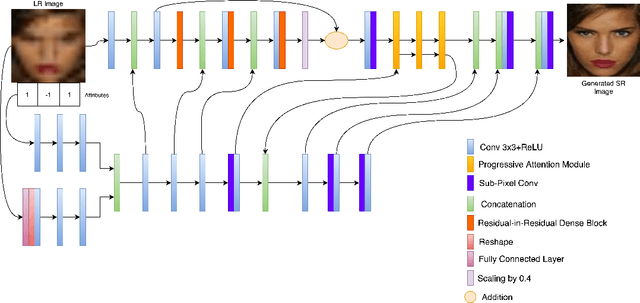
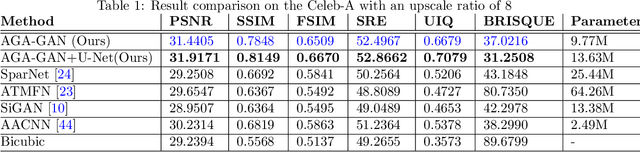
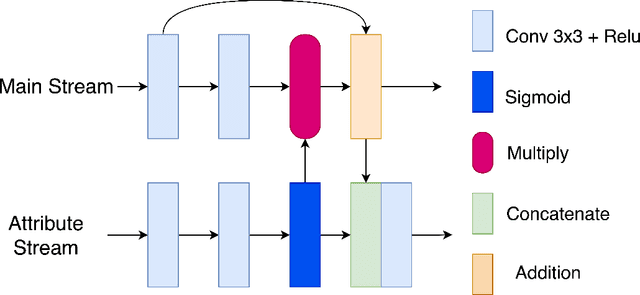
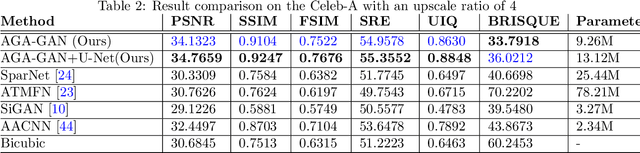
The performance of facial super-resolution methods relies on their ability to recover facial structures and salient features effectively. Even though the convolutional neural network and generative adversarial network-based methods deliver impressive performances on face hallucination tasks, the ability to use attributes associated with the low-resolution images to improve performance is unsatisfactory. In this paper, we propose an Attribute Guided Attention Generative Adversarial Network which employs novel attribute guided attention (AGA) modules to identify and focus the generation process on various facial features in the image. Stacking multiple AGA modules enables the recovery of both high and low-level facial structures. We design the discriminator to learn discriminative features exploiting the relationship between the high-resolution image and their corresponding facial attribute annotations. We then explore the use of U-Net based architecture to refine existing predictions and synthesize further facial details. Extensive experiments across several metrics show that our AGA-GAN and AGA-GAN+U-Net framework outperforms several other cutting-edge face hallucination state-of-the-art methods. We also demonstrate the viability of our method when every attribute descriptor is not known and thus, establishing its application in real-world scenarios.