 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinDocSegmenter: An End-to-End Unified Domain Adaptive Transformer for Document Instance Segmentation
May 08, 2023Instance-level segmentation of documents consists in assigning a class-aware and instance-aware label to each pixel of the image. It is a key step in document parsing for their understanding. In this paper, we present a unified transformer encoder-decoder architecture for en-to-end instance segmentation of complex layouts in document images. The method adapts a contrastive training with a mixed query selection for anchor initialization in the decoder. Later on, it performs a dot product between the obtained query embeddings and the pixel embedding map (coming from the encoder) for semantic reasoning. Extensive experimentation on competitive benchmarks like PubLayNet, PRIMA, Historical Japanese (HJ), and TableBank demonstrate that our model with SwinL backbone achieves better segmentation performance than the existing state-of-the-art approaches with the average precision of \textbf{93.72}, \textbf{54.39}, \textbf{84.65} and \textbf{98.04} respectively under one billion parameters. The code is made publicly available at: \href{https://github.com/ayanban011/SwinDocSegmenter}{github.com/ayanban011/SwinDocSegmenter}
SelfDocSeg: A Self-Supervised vision-based Approach towards Document Segmentation
May 02, 2023Document layout analysis is a known problem to the documents research community and has been vastly explored yielding a multitude of solutions ranging from text mining, and recognition to graph-based representation, visual feature extraction, etc. However, most of the existing works have ignored the crucial fact regarding the scarcity of labeled data. With growing internet connectivity to personal life, an enormous amount of documents had been available in the public domain and thus making data annotation a tedious task. We address this challenge using self-supervision and unlike, the few existing self-supervised document segmentation approaches which use text mining and textual labels, we use a complete vision-based approach in pre-training without any ground-truth label or its derivative. Instead, we generate pseudo-layouts from the document images to pre-train an image encoder to learn the document object representation and localization in a self-supervised framework before fine-tuning it with an object detection model. We show that our pipeline sets a new benchmark in this context and performs at par with the existing methods and the supervised counterparts, if not outperforms. The code is made publicly available at: https://github.com/MaitySubhajit/SelfDocSeg
MMC: Multi-Modal Colorization of Images using Textual Descriptions
Apr 25, 2023Handling various objects with different colors is a significant challenge for image colorization techniques. Thus, for complex real-world scenes, the existing image colorization algorithms often fail to maintain color consistency. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To do so, we have proposed a deep network that takes two inputs (grayscale image and the respective encoded text description) and tries to predict the relevant color components. Also, we have predicted each object in the image and have colorized them with their individual description to incorporate their specific attributes in the colorization process. After that, a fusion model fuses all the image objects (segments) to generate the final colorized image. As the respective textual descriptions contain color information of the objects present in the image, text encoding helps to improve the overall quality of predicted colors. In terms of performance, the proposed method outperforms existing colorization techniques in terms of LPIPS, PSNR and SSIM metrics.
ICDAR 2023 Video Text Reading Competition for Dense and Small Text
Apr 10, 2023



Recently, video text detection, tracking, and recognition in natural scenes are becoming very popular in the computer vision community. However, most existing algorithms and benchmarks focus on common text cases (e.g., normal size, density) and single scenarios, while ignoring extreme video text challenges, i.e., dense and small text in various scenarios. In this competition report, we establish a video text reading benchmark, DSText, which focuses on dense and small text reading challenges in the video with various scenarios. Compared with the previous datasets, the proposed dataset mainly include three new challenges: 1) Dense video texts, a new challenge for video text spotter. 2) High-proportioned small texts. 3) Various new scenarios, e.g., Game, sports, etc. The proposed DSText includes 100 video clips from 12 open scenarios, supporting two tasks (i.e., video text tracking (Task 1) and end-to-end video text spotting (Task 2)). During the competition period (opened on 15th February 2023 and closed on 20th March 2023), a total of 24 teams participated in the three proposed tasks with around 30 valid submissions, respectively. In this article, we describe detailed statistical information of the dataset, tasks, evaluation protocols and the results summaries of the ICDAR 2023 on DSText competition. Moreover, we hope the benchmark will promise video text research in the community.
A CNN Based Framework for Unistroke Numeral Recognition in Air-Writing
Mar 14, 2023Air-writing refers to virtually writing linguistic characters through hand gestures in three-dimensional space with six degrees of freedom. This paper proposes a generic video camera-aided convolutional neural network (CNN) based air-writing framework. Gestures are performed using a marker of fixed color in front of a generic video camera, followed by color-based segmentation to identify the marker and track the trajectory of the marker tip. A pre-trained CNN is then used to classify the gesture. The recognition accuracy is further improved using transfer learning with the newly acquired data. The performance of the system varies significantly on the illumination condition due to color-based segmentation. In a less fluctuating illumination condition, the system is able to recognize isolated unistroke numerals of multiple languages. The proposed framework has achieved 97.7%, 95.4% and 93.7% recognition rates in person independent evaluations on English, Bengali and Devanagari numerals, respectively.
Global Context-Aware Person Image Generation
Feb 28, 2023We propose a data-driven approach for context-aware person image generation. Specifically, we attempt to generate a person image such that the synthesized instance can blend into a complex scene. In our method, the position, scale, and appearance of the generated person are semantically conditioned on the existing persons in the scene. The proposed technique is divided into three sequential steps. At first, we employ a Pix2PixHD model to infer a coarse semantic mask that represents the new person's spatial location, scale, and potential pose. Next, we use a data-centric approach to select the closest representation from a precomputed cluster of fine semantic masks. Finally, we adopt a multi-scale, attention-guided architecture to transfer the appearance attributes from an exemplar image. The proposed strategy enables us to synthesize semantically coherent realistic persons that can blend into an existing scene without altering the global context. We conclude our findings with relevant qualitative and quantitative evaluations.
TIC: Text-Guided Image Colorization
Aug 04, 2022

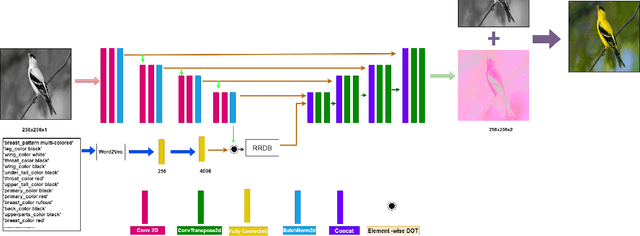
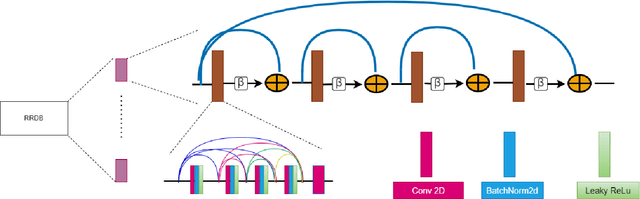
Image colorization is a well-known problem in computer vision. However, due to the ill-posed nature of the task, image colorization is inherently challenging. Though several attempts have been made by researchers to make the colorization pipeline automatic, these processes often produce unrealistic results due to a lack of conditioning. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To the best of our knowledge, this is one of the first attempts to incorporate textual conditioning in the colorization pipeline. To do so, we have proposed a novel deep network that takes two inputs (the grayscale image and the respective encoded text description) and tries to predict the relevant color gamut. As the respective textual descriptions contain color information of the objects present in the scene, the text encoding helps to improve the overall quality of the predicted colors. We have evaluated our proposed model using different metrics and found that it outperforms the state-of-the-art colorization algorithms both qualitatively and quantitatively.
TIPS: Text-Induced Pose Synthesis
Jul 24, 2022
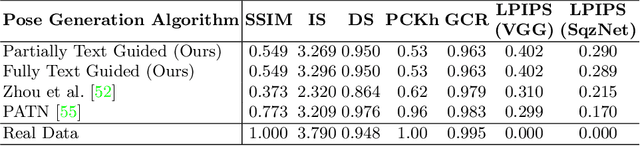
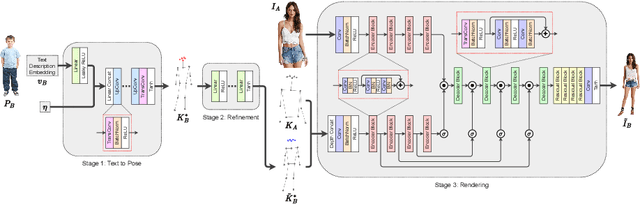
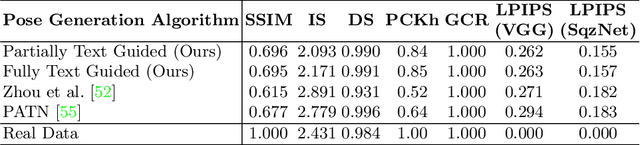
In computer vision, human pose synthesis and transfer deal with probabilistic image generation of a person in a previously unseen pose from an already available observation of that person. Though researchers have recently proposed several methods to achieve this task, most of these techniques derive the target pose directly from the desired target image on a specific dataset, making the underlying process challenging to apply in real-world scenarios as the generation of the target image is the actual aim. In this paper, we first present the shortcomings of current pose transfer algorithms and then propose a novel text-based pose transfer technique to address those issues. We divide the problem into three independent stages: (a) text to pose representation, (b) pose refinement, and (c) pose rendering. To the best of our knowledge, this is one of the first attempts to develop a text-based pose transfer framework where we also introduce a new dataset DF-PASS, by adding descriptive pose annotations for the images of the DeepFashion dataset. The proposed method generates promising results with significant qualitative and quantitative scores in our experiments.
SGBANet: Semantic GAN and Balanced Attention Network for Arbitrarily Oriented Scene Text Recognition
Jul 21, 2022
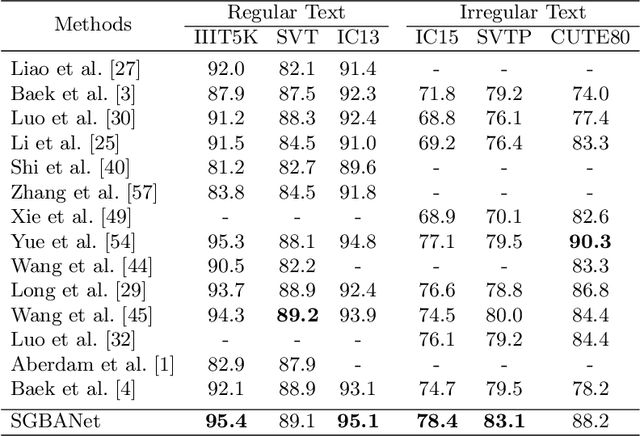
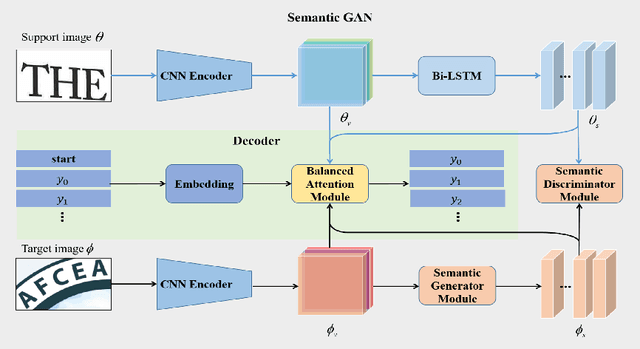

Scene text recognition is a challenging task due to the complex backgrounds and diverse variations of text instances. In this paper, we propose a novel Semantic GAN and Balanced Attention Network (SGBANet) to recognize the texts in scene images. The proposed method first generates the simple semantic feature using Semantic GAN and then recognizes the scene text with the Balanced Attention Module. The Semantic GAN aims to align the semantic feature distribution between the support domain and target domain. Different from the conventional image-to-image translation methods that perform at the image level, the Semantic GAN performs the generation and discrimination on the semantic level with the Semantic Generator Module (SGM) and Semantic Discriminator Module (SDM). For target images (scene text images), the Semantic Generator Module generates simple semantic features that share the same feature distribution with support images (clear text images). The Semantic Discriminator Module is used to distinguish the semantic features between the support domain and target domain. In addition, a Balanced Attention Module is designed to alleviate the problem of attention drift. The Balanced Attention Module first learns a balancing parameter based on the visual glimpse vector and semantic glimpse vector, and then performs the balancing operation for obtaining a balanced glimpse vector. Experiments on six benchmarks, including regular datasets, i.e., IIIT5K, SVT, ICDAR2013, and irregular datasets, i.e., ICDAR2015, SVTP, CUTE80, validate the effectiveness of our proposed method.
Scene Aware Person Image Generation through Global Contextual Conditioning
Jun 06, 2022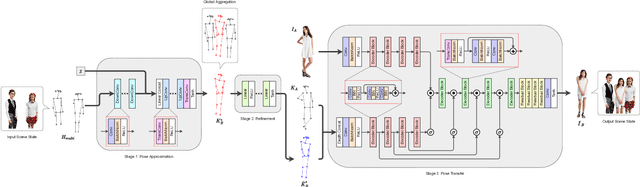
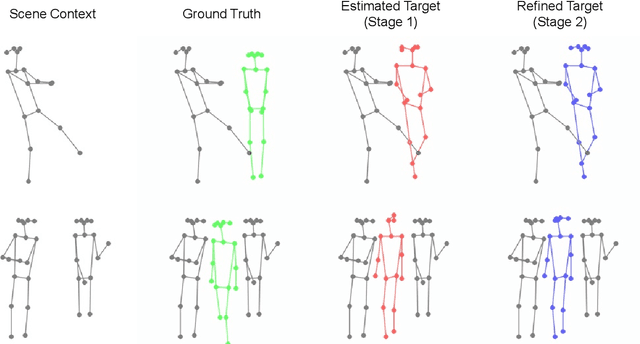


Person image generation is an intriguing yet challenging problem. However, this task becomes even more difficult under constrained situations. In this work, we propose a novel pipeline to generate and insert contextually relevant person images into an existing scene while preserving the global semantics. More specifically, we aim to insert a person such that the location, pose, and scale of the person being inserted blends in with the existing persons in the scene. Our method uses three individual networks in a sequential pipeline. At first, we predict the potential location and the skeletal structure of the new person by conditioning a Wasserstein Generative Adversarial Network (WGAN) on the existing human skeletons present in the scene. Next, the predicted skeleton is refined through a shallow linear network to achieve higher structural accuracy in the generated image. Finally, the target image is generated from the refined skeleton using another generative network conditioned on a given image of the target person. In our experiments, we achieve high-resolution photo-realistic generation results while preserving the general context of the scene. We conclude our paper with multiple qualitative and quantitative benchmarks on the results.