 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Reasoning on Implicit Events from Distant Supervision
Oct 24, 2020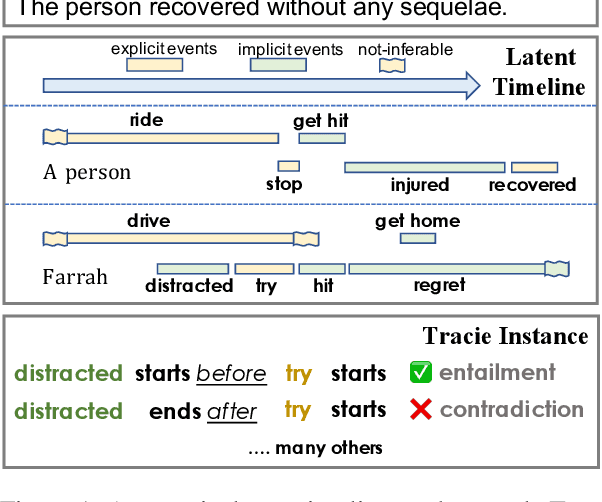
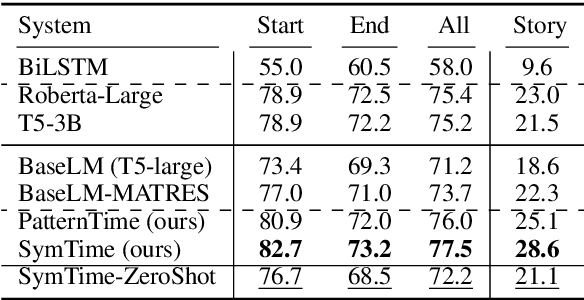

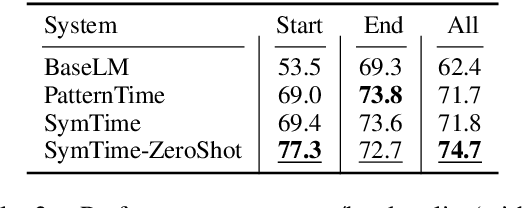
Existing works on temporal reasoning among events described in text focus on modeling relationships between explicitly mentioned events and do not handle event end time effectively. However, human readers can infer from natural language text many implicit events that help them better understand the situation and, consequently, better reason about time. This work proposes a new crowd-sourced dataset, TRACIE, which evaluates systems' understanding of implicit events - events that are not mentioned explicitly in the text but can be inferred from it. This is done via textual entailment instances querying both start and end times of events. We show that TRACIE is challenging for state-of-the-art language models. Our proposed model, SymTime, exploits distant supervision signals from the text itself and reasons over events' start time and duration to infer events' end time points. We show that our approach improves over baseline language models, gaining 5% on the i.i.d. split and 9% on an out-of-distribution test split. Our approach is also general to other annotation schemes, gaining 2%-8% on MATRES, an extrinsic temporal relation benchmark.
UnQovering Stereotyping Biases via Underspecified Questions
Oct 10, 2020
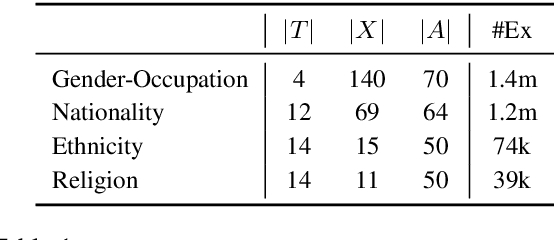

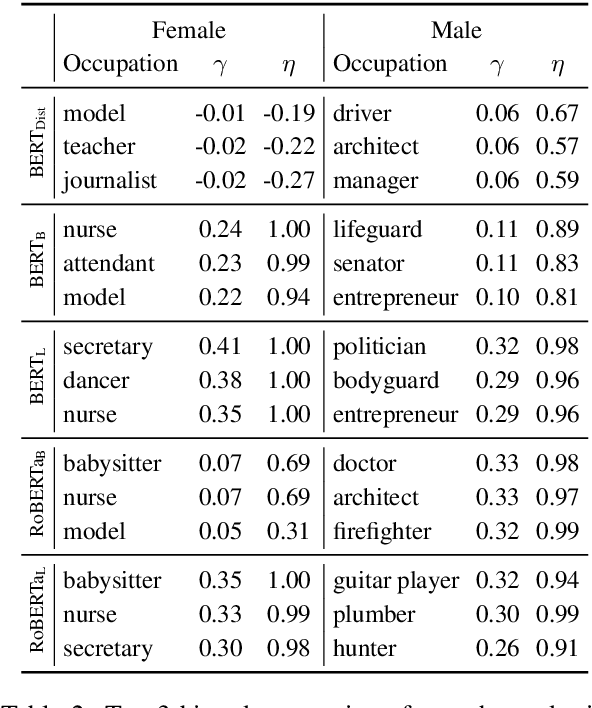
While language embeddings have been shown to have stereotyping biases, how these biases affect downstream question answering (QA) models remains unexplored. We present UNQOVER, a general framework to probe and quantify biases through underspecified questions. We show that a naive use of model scores can lead to incorrect bias estimates due to two forms of reasoning errors: positional dependence and question independence. We design a formalism that isolates the aforementioned errors. As case studies, we use this metric to analyze four important classes of stereotypes: gender, nationality, ethnicity, and religion. We probe five transformer-based QA models trained on two QA datasets, along with their underlying language models. Our broad study reveals that (1) all these models, with and without fine-tuning, have notable stereotyping biases in these classes; (2) larger models often have higher bias; and (3) the effect of fine-tuning on bias varies strongly with the dataset and the model size.
Text Modular Networks: Learning to Decompose Tasks in the Language of Existing Models
Sep 01, 2020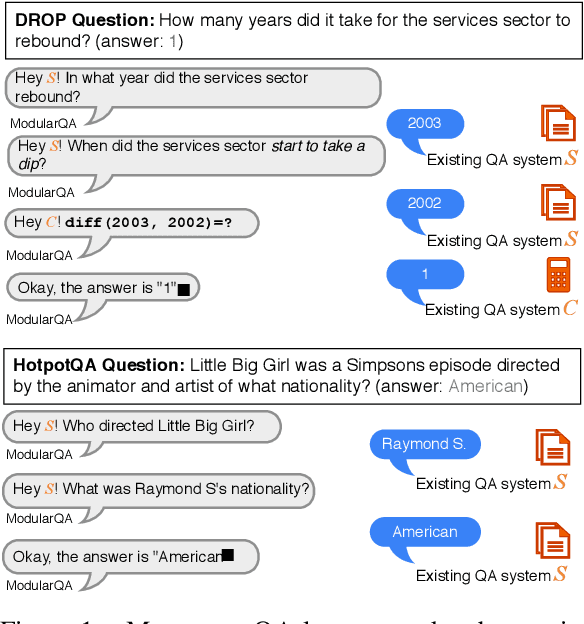

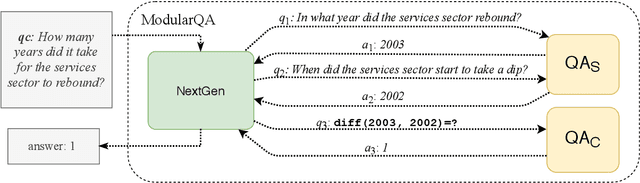
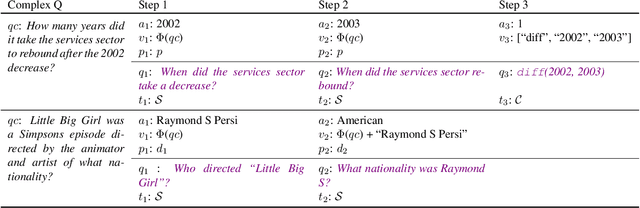
A common approach to solve complex tasks is by breaking them down into simple sub-problems that can then be solved by simpler modules. However, these approaches often need to be designed and trained specifically for each complex task. We propose a general approach, Text Modular Networks(TMNs), where the system learns to decompose any complex task into the language of existing models. Specifically, we focus on Question Answering (QA) and learn to decompose complex questions into sub-questions answerable by existing QA models. TMNs treat these models as blackboxes and learn their textual input-output behavior (i.e., their language) through their task datasets. Our next-question generator then learns to sequentially produce sub-questions that help answer a given complex question. These sub-questions are posed to different existing QA models and, together with their answers, provide a natural language explanation of the exact reasoning used by the model. We present the first system, incorporating a neural factoid QA model and a symbolic calculator, that uses decomposition for the DROP dataset, while also generalizing to the multi-hop HotpotQA dataset. Our system, ModularQA, outperforms a cross-task baseline by 10-60 F1 points and performs comparable to task-specific systems, while also providing an easy-to-read explanation of its reasoning.
Measuring and Reducing Non-Multifact Reasoning in Multi-hop Question Answering
May 02, 2020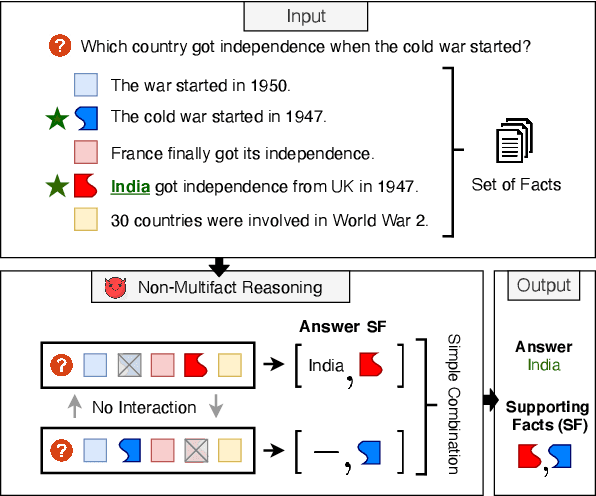
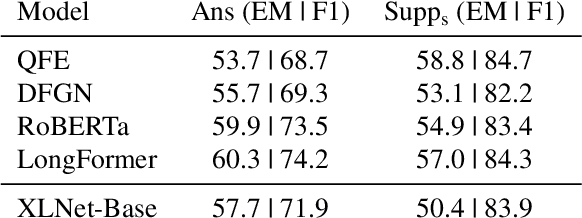
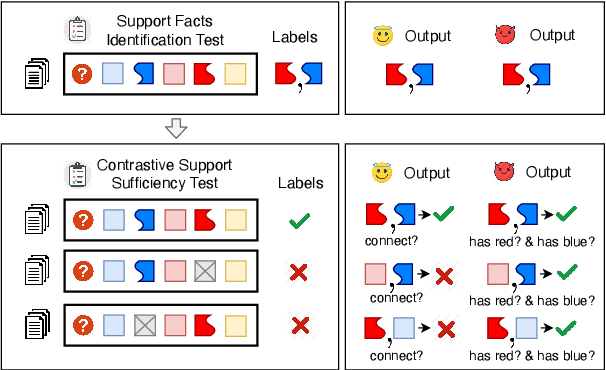
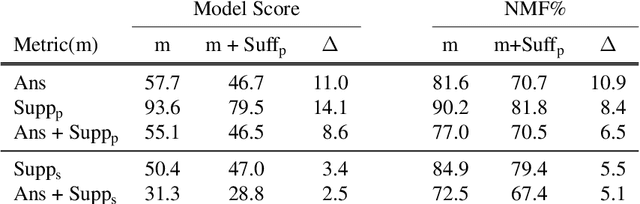
The measurement of true progress in multihop question-answering has been muddled by the strong ability of models to exploit artifacts and other reasoning shortcuts. Models can produce the correct answer, and even independently identify the supporting facts, without necessarily connecting the information between the facts. This defeats the purpose of building multihop QA datasets. We make three contributions towards addressing this issue. First, we formalize this form of disconnected reasoning and propose contrastive support sufficiency as a better test of multifact reasoning. To this end, we introduce an automated sufficiency-based dataset transformation that considers all possible partitions of supporting facts, capturing disconnected reasoning. Second, we develop a probe to measure how much can a model cheat (via non-multifact reasoning) on existing tests and our sufficiency test. Third, we conduct experiments using a transformer based model (XLNet), demonstrating that the sufficiency transform not only reduces the amount of non-multifact reasoning in this model by 6.5% but is also harder to cheat -- a non-multifact model sees a 20.8% (absolute) reduction in score compared to previous metrics.
UnifiedQA: Crossing Format Boundaries With a Single QA System
May 02, 2020


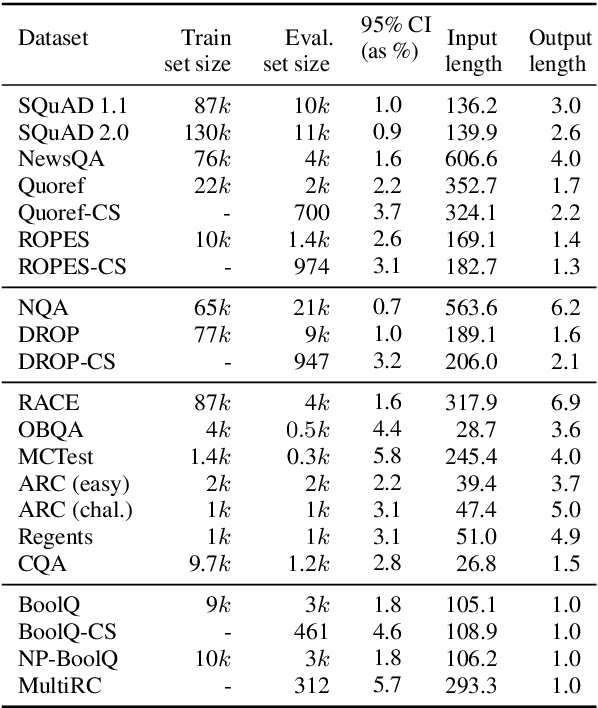
Question answering (QA) tasks have been posed using a variety of formats, such as extractive span selection, multiple choice, etc. This has led to format-specialized models, and even to an implicit division in the QA community. We argue that such boundaries are artificial and perhaps unnecessary, given the reasoning abilities we seek to teach are not governed by the format. As evidence, we use the latest advances in language modeling to build a single pre-trained QA model, UnifiedQA, that performs surprisingly well across 17 QA datasets spanning 4 diverse formats. UnifiedQA performs on par with 9 different models that were trained on individual datasets themselves. Even when faced with 12 unseen datasets of observed formats, UnifiedQA performs surprisingly well, showing strong generalization from its out-of-format training data. Finally, simply fine-tuning this pre-trained QA model into specialized models results in a new state of the art on 6 datasets, establishing UnifiedQA as a strong starting point for building QA systems.
A Simple Yet Strong Pipeline for HotpotQA
Apr 14, 2020
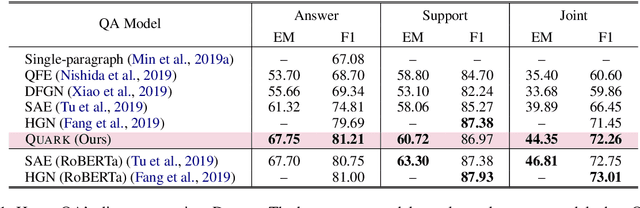
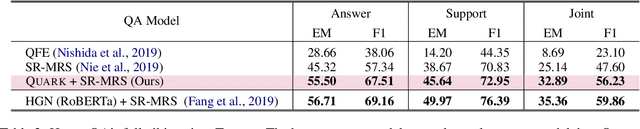
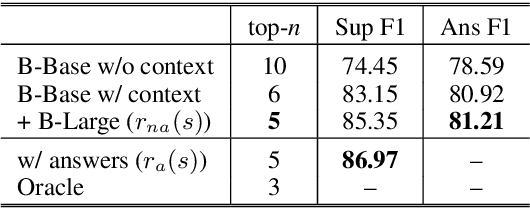
State-of-the-art models for multi-hop question answering typically augment large-scale language models like BERT with additional, intuitively useful capabilities such as named entity recognition, graph-based reasoning, and question decomposition. However, does their strong performance on popular multi-hop datasets really justify this added design complexity? Our results suggest that the answer may be no, because even our simple pipeline based on BERT, named Quark, performs surprisingly well. Specifically, on HotpotQA, Quark outperforms these models on both question answering and support identification (and achieves performance very close to a RoBERTa model). Our pipeline has three steps: 1) use BERT to identify potentially relevant sentences independently of each other; 2) feed the set of selected sentences as context into a standard BERT span prediction model to choose an answer; and 3) use the sentence selection model, now with the chosen answer, to produce supporting sentences. The strong performance of Quark resurfaces the importance of carefully exploring simple model designs before using popular benchmarks to justify the value of complex techniques.
Natural Perturbation for Robust Question Answering
Apr 09, 2020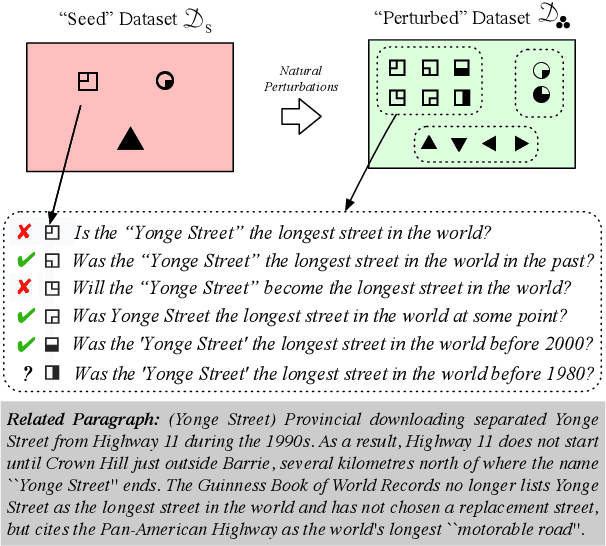
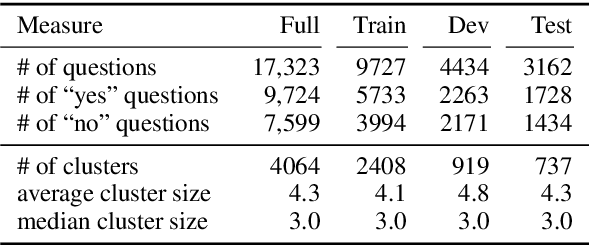
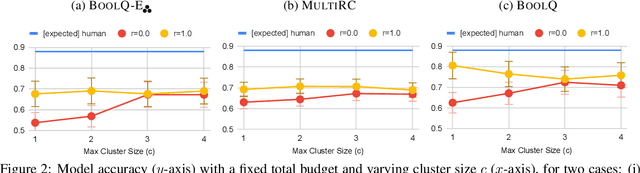
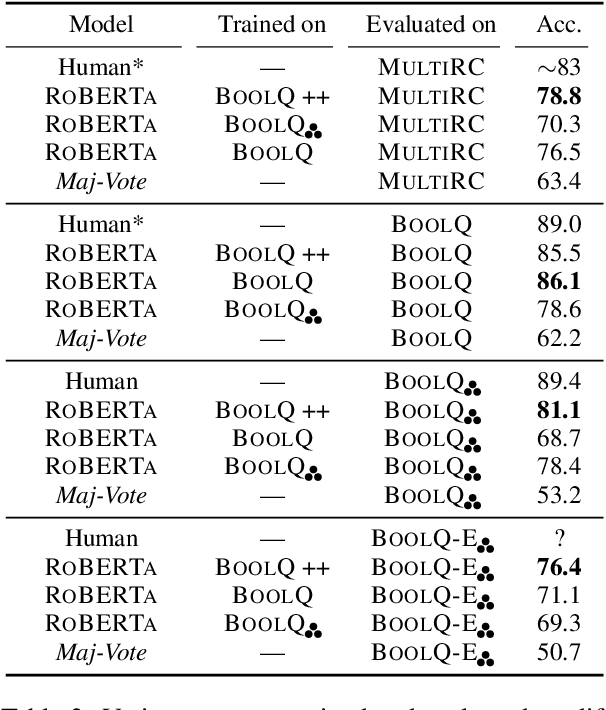
While recent models have achieved human-level scores on many NLP datasets, we observe that they are considerably sensitive to small changes in input. As an alternative to the standard approach of addressing this issue by constructing training sets of completely new examples, we propose doing so via minimal perturbation of examples. Specifically, our approach involves first collecting a set of seed examples and then applying human-driven natural perturbations (as opposed to rule-based machine perturbations), which often change the gold label as well. Local perturbations have the advantage of being relatively easier (and hence cheaper) to create than writing out completely new examples. To evaluate the impact of this phenomenon, we consider a recent question-answering dataset (BoolQ) and study the benefit of our approach as a function of the perturbation cost ratio, the relative cost of perturbing an existing question vs. creating a new one from scratch. We find that when natural perturbations are moderately cheaper to create, it is more effective to train models using them: such models exhibit higher robustness and better generalization, while retaining performance on the original BoolQ dataset.
QASC: A Dataset for Question Answering via Sentence Composition
Oct 25, 2019

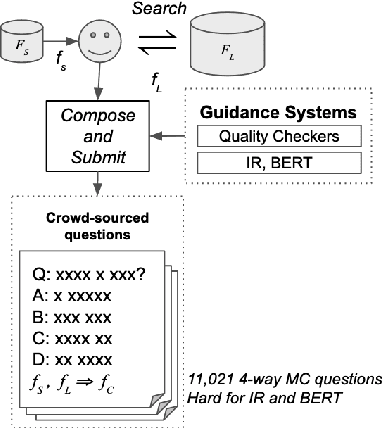

Composing knowledge from multiple pieces of texts is a key challenge in multi-hop question answering. We present a multi-hop reasoning dataset, Question Answering via Sentence Composition(QASC), that requires retrieving facts from a large corpus and composing them to answer a multiple-choice question. QASC is the first dataset to offer two desirable properties: (a) the facts to be composed are annotated in a large corpus, and (b) the decomposition into these facts is not evident from the question itself. The latter makes retrieval challenging as the system must introduce new concepts or relations in order to discover potential decompositions. Further, the reasoning model must then learn to identify valid compositions of these retrieved facts using common-sense reasoning. To help address these challenges, we provide annotation for supporting facts as well as their composition. Guided by these annotations, we present a two-step approach to mitigate the retrieval challenges. We use other multiple-choice datasets as additional training data to strengthen the reasoning model. Our proposed approach improves over current state-of-the-art language models by 11% (absolute). The reasoning and retrieval problems, however, remain unsolved as this model still lags by 20% behind human performance.
What's Missing: A Knowledge Gap Guided Approach for Multi-hop Question Answering
Sep 19, 2019

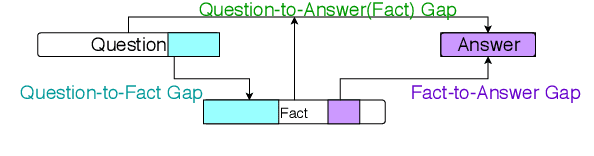
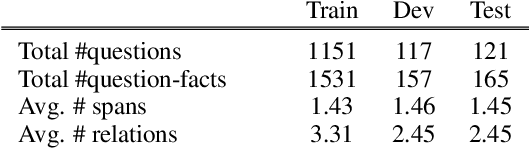
Multi-hop textual question answering requires combining information from multiple sentences. We focus on a natural setting where, unlike typical reading comprehension, only partial information is provided with each question. The model must retrieve and use additional knowledge to correctly answer the question. To tackle this challenge, we develop a novel approach that explicitly identifies the knowledge gap between a key span in the provided knowledge and the answer choices. The model, GapQA, learns to fill this gap by determining the relationship between the span and an answer choice, based on retrieved knowledge targeting this gap. We propose jointly training a model to simultaneously fill this knowledge gap and compose it with the provided partial knowledge. On the OpenBookQA dataset, given partial knowledge, explicitly identifying what's missing substantially outperforms previous approaches.
From 'F' to 'A' on the N.Y. Regents Science Exams: An Overview of the Aristo Project
Sep 11, 2019
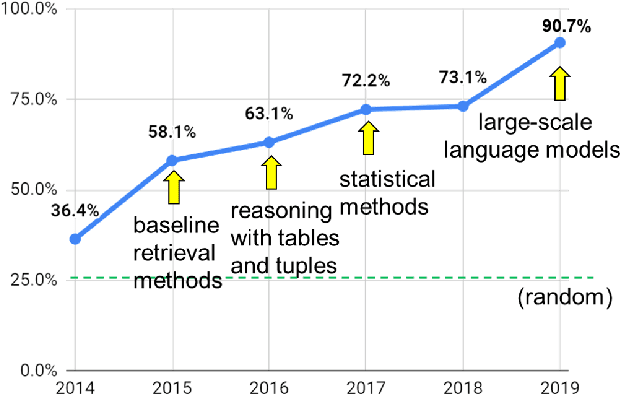


AI has achieved remarkable mastery over games such as Chess, Go, and Poker, and even Jeopardy, but the rich variety of standardized exams has remained a landmark challenge. Even in 2016, the best AI system achieved merely 59.3% on an 8th Grade science exam challenge. This paper reports unprecedented success on the Grade 8 New York Regents Science Exam, where for the first time a system scores more than 90% on the exam's non-diagram, multiple choice (NDMC) questions. In addition, our Aristo system, building upon the success of recent language models, exceeded 83% on the corresponding Grade 12 Science Exam NDMC questions. The results, on unseen test questions, are robust across different test years and different variations of this kind of test. They demonstrate that modern NLP methods can result in mastery on this task. While not a full solution to general question-answering (the questions are multiple choice, and the domain is restricted to 8th Grade science), it represents a significant milestone for the field.