 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Document-level Information Extraction via Imitation Learning
Oct 12, 2022
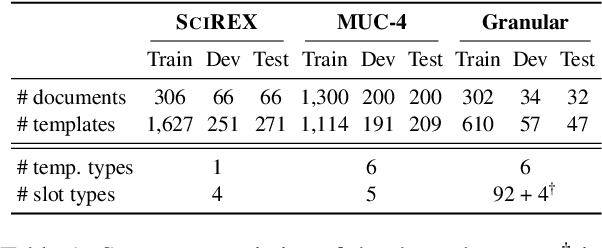

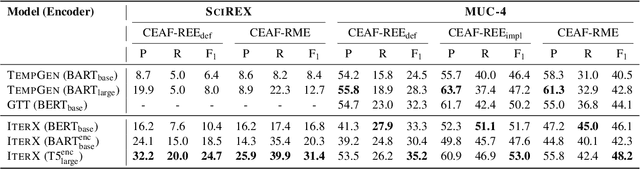
We present a novel iterative extraction (IterX) model for extracting complex relations, or templates, i.e., N-tuples representing a mapping from named slots to spans of text contained within a document. Documents may support zero or more instances of a template of any particular type, leading to the tasks of identifying the templates in a document, and extracting each template's slot values. Our imitation learning approach relieves the need to use predefined template orders to train an extractor and leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.
BenchCLAMP: A Benchmark for Evaluating Language Models on Semantic Parsing
Jun 21, 2022
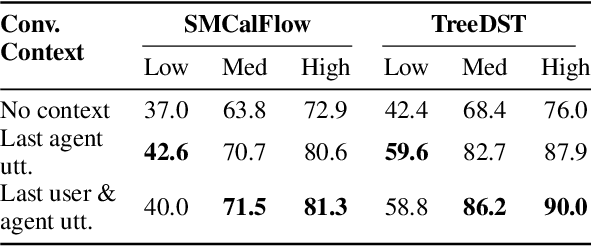
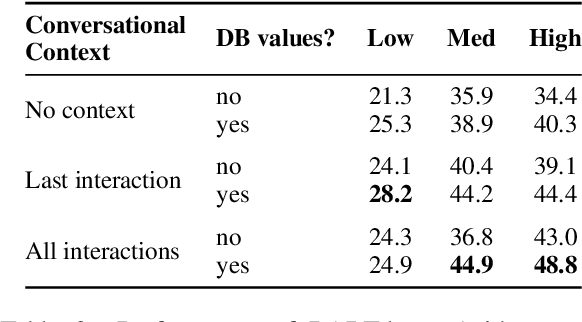

We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, which produces semantic outputs based on the analysis of input text through constrained decoding of a prompted or fine-tuned language model. Developers of pretrained language models currently benchmark on classification, span extraction and free-text generation tasks. Semantic parsing is neglected in language model evaluation because of the complexity of handling task-specific architectures and representations. Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. BenchCLAMP includes context-free grammars for six semantic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports both prompt-based learning as well as fine-tuning, and provides an easy-to-use toolkit for language model developers to evaluate on semantic parsing.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021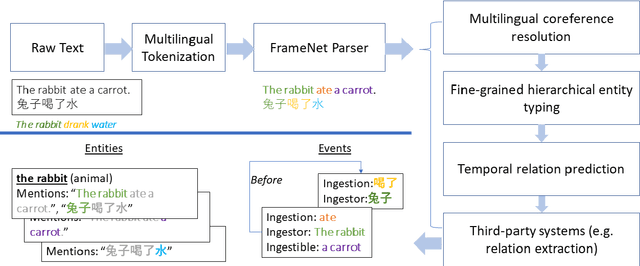
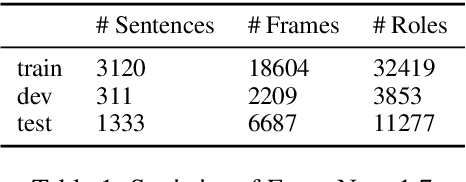
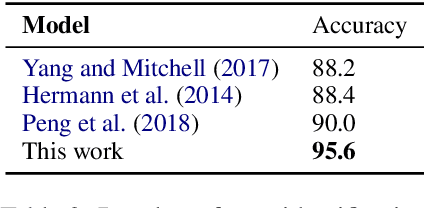
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
Hierarchical Entity Typing via Multi-level Learning to Rank
Apr 05, 2020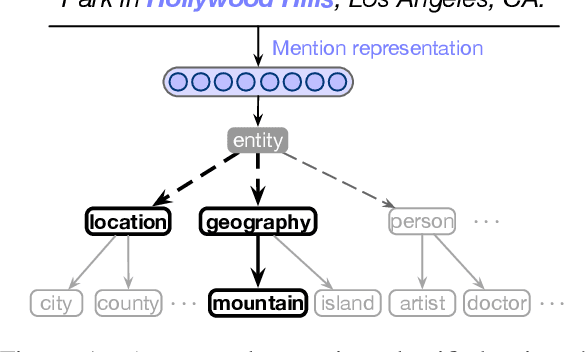

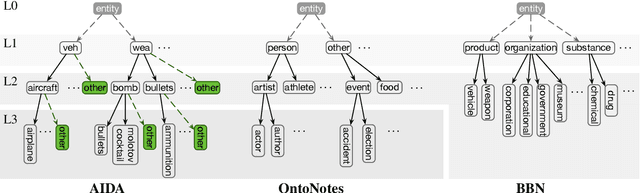
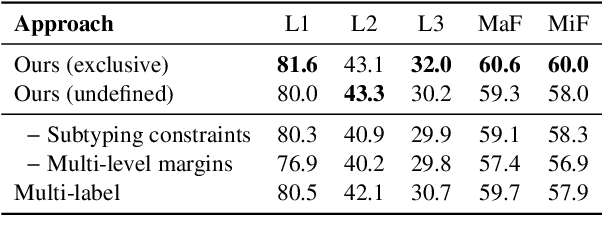
We propose a novel method for hierarchical entity classification that embraces ontological structure at both training and during prediction. At training, our novel multi-level learning-to-rank loss compares positive types against negative siblings according to the type tree. During prediction, we define a coarse-to-fine decoder that restricts viable candidates at each level of the ontology based on already predicted parent type(s). We achieve state-of-the-art across multiple datasets, particularly with respect to strict accuracy.
Reading the Manual: Event Extraction as Definition Comprehension
Dec 03, 2019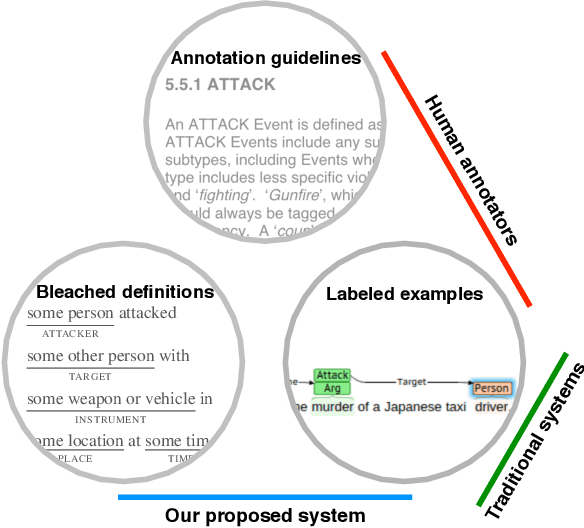
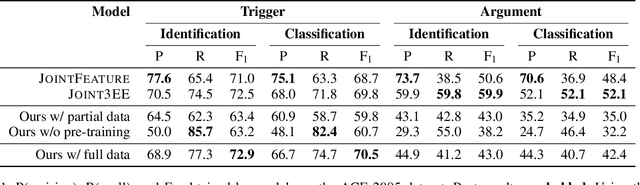
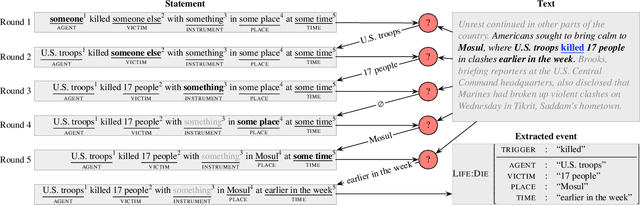
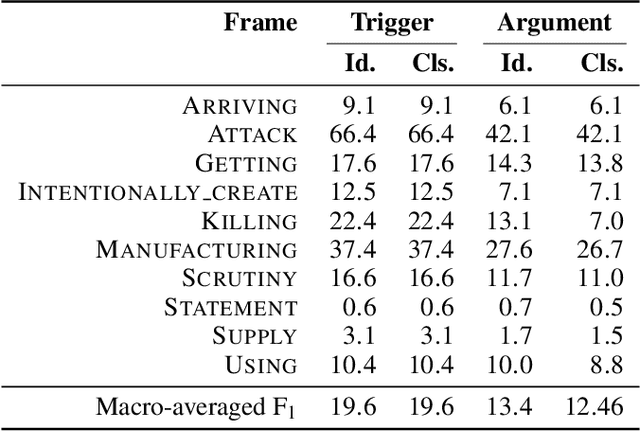
We propose a novel approach to event extraction that supplies models with \emph{bleached statements}: machine-readable natural language sentences that are based on annotation guidelines and that describe generic occurrences of events. We introduce a model that incrementally replaces the bleached arguments in a statement with responses obtained by querying text with the statement itself. Experimental results demonstrate that our model is able to extract events under closed ontologies and can generalize to unseen event types simply by reading new bleached statements.
Espresso: A Fast End-to-end Neural Speech Recognition Toolkit
Oct 15, 2019
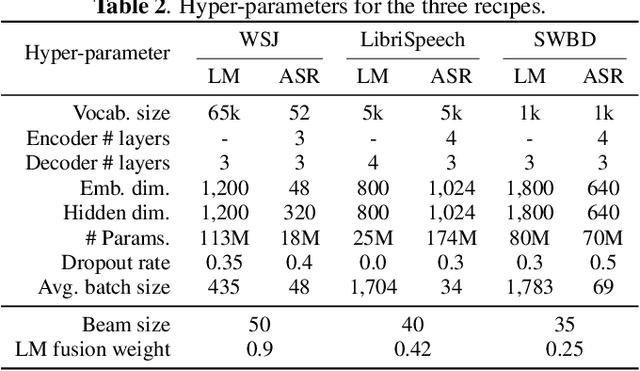
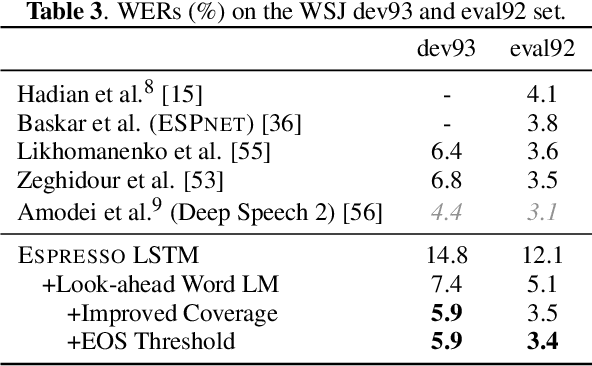
We present Espresso, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit fairseq. Espresso supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. Espresso achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4--11x faster for decoding than similar systems (e.g. ESPnet).
Uncertain Natural Language Inference
Sep 06, 2019


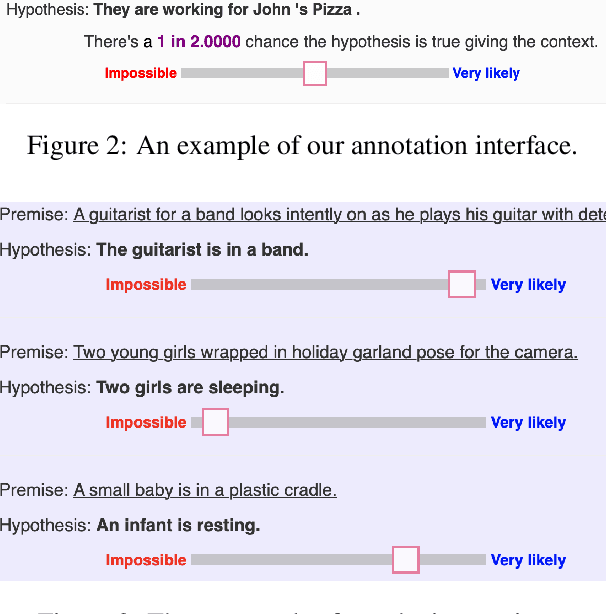
We propose a refinement of Natural Language Inference (NLI), called Uncertain Natural Language Inference (UNLI), that shifts away from categorical labels, targeting instead the direct prediction of subjective probability assessments. Chiefly, we demonstrate the feasibility of collecting annotations for UNLI by relabeling a portion of the SNLI dataset under a psychologically motivated probabilistic scale, where items even with the same categorical label, e.g., "contradictions" differ in how likely people judge them to be strictly impossible given a premise. We describe two modeling approaches, as direct scalar regression and as learning-to-rank, finding that existing categorically labeled NLI data can be used in pre-training. Our best models correlate well with humans, demonstrating models are capable of more subtle inferences than the ternary bin assignment employed in current NLI tasks.
Learning to Rank for Plausible Plausibility
Jun 05, 2019
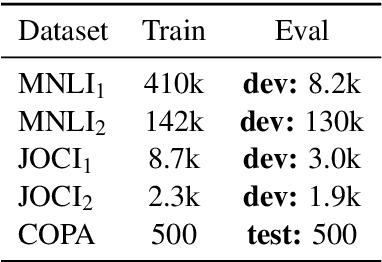
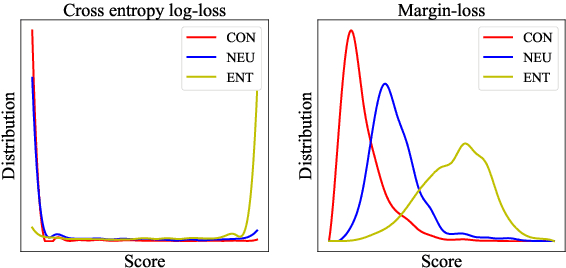
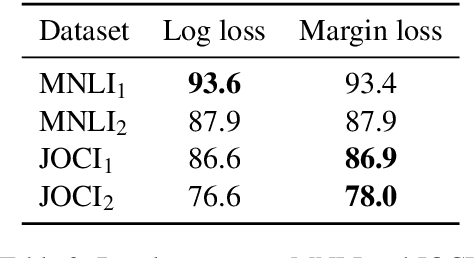
Researchers illustrate improvements in contextual encoding strategies via resultant performance on a battery of shared Natural Language Understanding (NLU) tasks. Many of these tasks are of a categorical prediction variety: given a conditioning context (e.g., an NLI premise), provide a label based on an associated prompt (e.g., an NLI hypothesis). The categorical nature of these tasks has led to common use of a cross entropy log-loss objective during training. We suggest this loss is intuitively wrong when applied to plausibility tasks, where the prompt by design is neither categorically entailed nor contradictory given the context. Log-loss naturally drives models to assign scores near 0.0 or 1.0, in contrast to our proposed use of a margin-based loss. Following a discussion of our intuition, we describe a confirmation study based on an extreme, synthetically curated task derived from MultiNLI. We find that a margin-based loss leads to a more plausible model of plausibility. Finally, we illustrate improvements on the Choice Of Plausible Alternative (COPA) task through this change in loss.
Improving Long Distance Slot Carryover in Spoken Dialogue Systems
Jun 04, 2019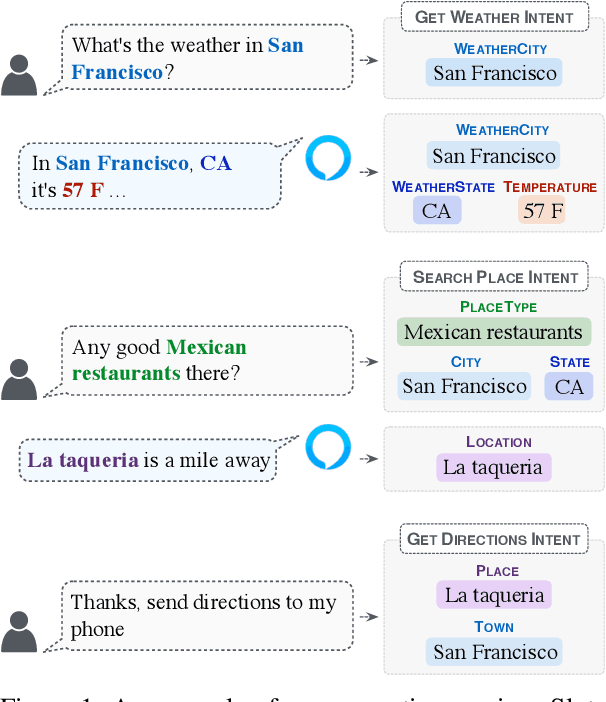
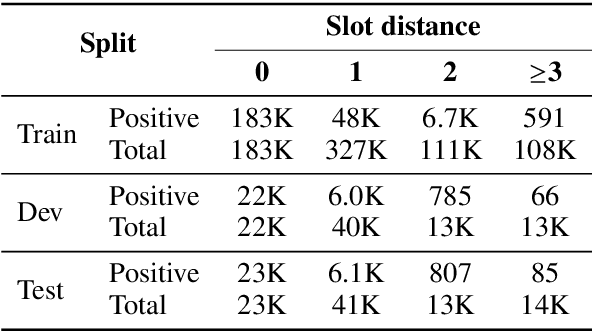
Tracking the state of the conversation is a central component in task-oriented spoken dialogue systems. One such approach for tracking the dialogue state is slot carryover, where a model makes a binary decision if a slot from the context is relevant to the current turn. Previous work on the slot carryover task used models that made independent decisions for each slot. A close analysis of the results show that this approach results in poor performance over longer context dialogues. In this paper, we propose to jointly model the slots. We propose two neural network architectures, one based on pointer networks that incorporate slot ordering information, and the other based on transformer networks that uses self attention mechanism to model the slot interdependencies. Our experiments on an internal dialogue benchmark dataset and on the public DSTC2 dataset demonstrate that our proposed models are able to resolve longer distance slot references and are able to achieve competitive performance.
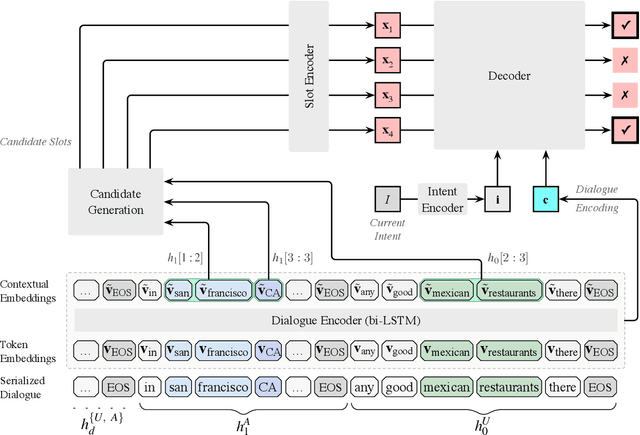
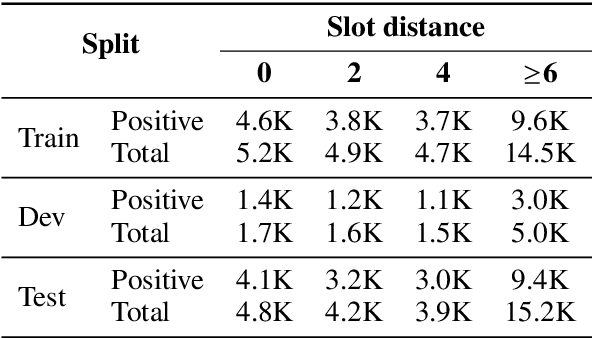
Scaling Multi-Domain Dialogue State Tracking via Query Reformulation
Mar 29, 2019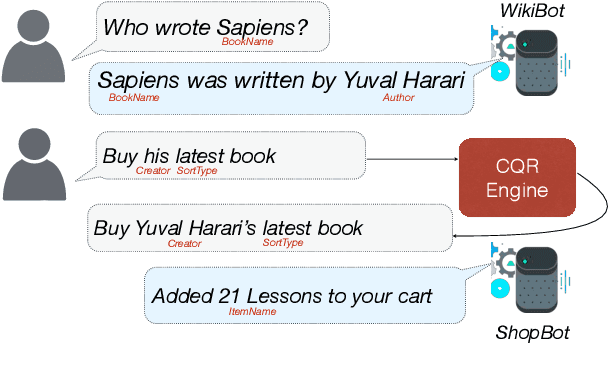
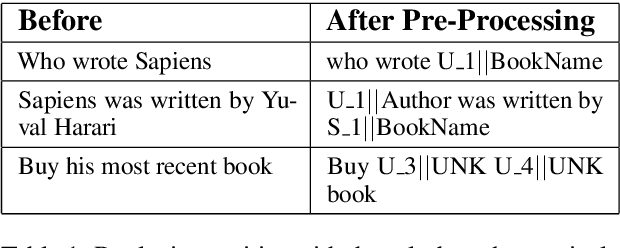

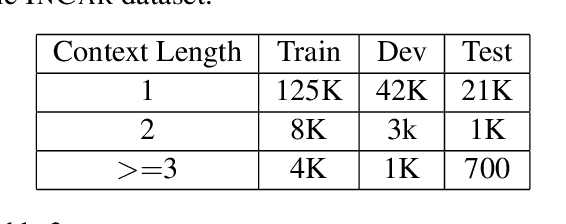
We present a novel approach to dialogue state tracking and referring expression resolution tasks. Successful contextual understanding of multi-turn spoken dialogues requires resolving referring expressions across turns and tracking the entities relevant to the conversation across turns. Tracking conversational state is particularly challenging in a multi-domain scenario when there exist multiple spoken language understanding (SLU) sub-systems, and each SLU sub-system operates on its domain-specific meaning representation. While previous approaches have addressed the disparate schema issue by learning candidate transformations of the meaning representation, in this paper, we instead model the reference resolution as a dialogue context-aware user query reformulation task -- the dialog state is serialized to a sequence of natural language tokens representing the conversation. We develop our model for query reformulation using a pointer-generator network and a novel multi-task learning setup. In our experiments, we show a significant improvement in absolute F1 on an internal as well as a, soon to be released, public benchmark respectively.