Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Document-level Information Extraction via Imitation Learning
Paper and Code

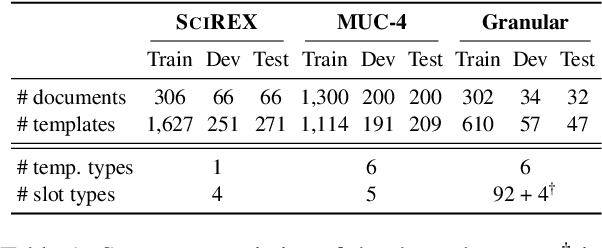

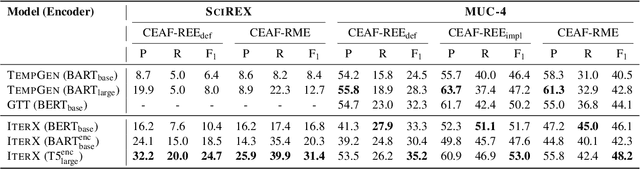
We present a novel iterative extraction (IterX) model for extracting complex relations, or templates, i.e., N-tuples representing a mapping from named slots to spans of text contained within a document. Documents may support zero or more instances of a template of any particular type, leading to the tasks of identifying the templates in a document, and extracting each template's slot values. Our imitation learning approach relieves the need to use predefined template orders to train an extractor and leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.
View paper on