 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Value Inconsistency as a Signal for Epistemic Uncertainty
Dec 08, 2021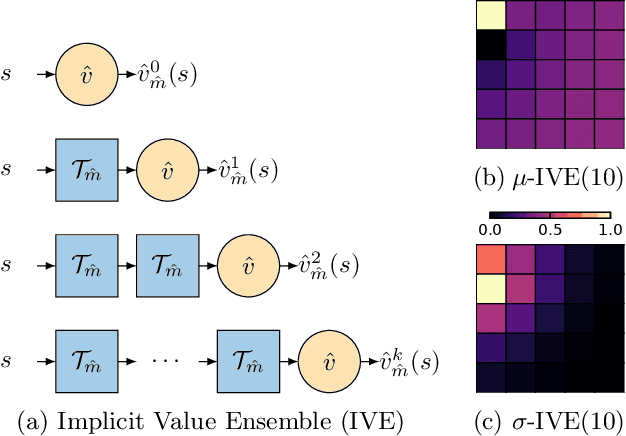

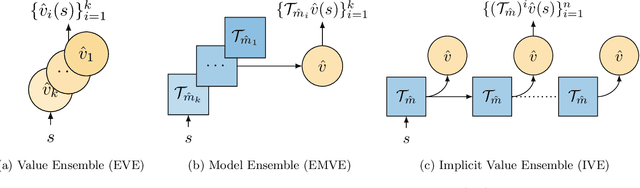
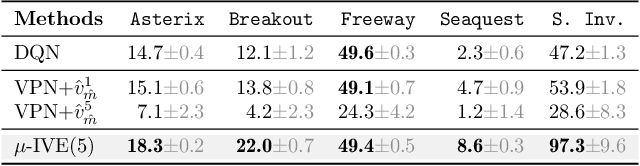
Using a model of the environment and a value function, an agent can construct many estimates of a state's value, by unrolling the model for different lengths and bootstrapping with its value function. Our key insight is that one can treat this set of value estimates as a type of ensemble, which we call an \emph{implicit value ensemble} (IVE). Consequently, the discrepancy between these estimates can be used as a proxy for the agent's epistemic uncertainty; we term this signal \emph{model-value inconsistency} or \emph{self-inconsistency} for short. Unlike prior work which estimates uncertainty by training an ensemble of many models and/or value functions, this approach requires only the single model and value function which are already being learned in most model-based reinforcement learning algorithms. We provide empirical evidence in both tabular and function approximation settings from pixels that self-inconsistency is useful (i) as a signal for exploration, (ii) for acting safely under distribution shifts, and (iii) for robustifying value-based planning with a model.
When should agents explore?
Aug 26, 2021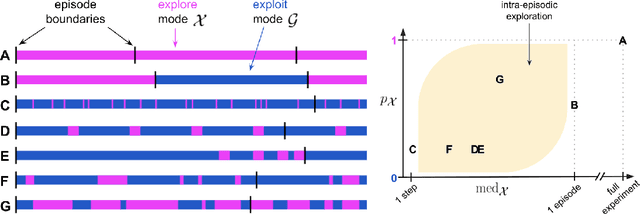
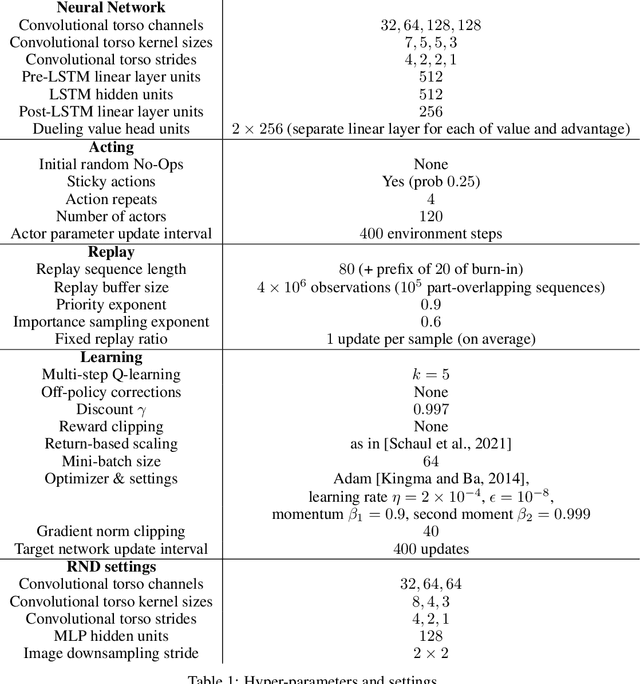
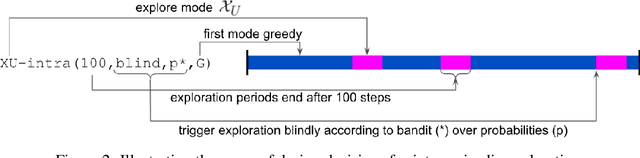
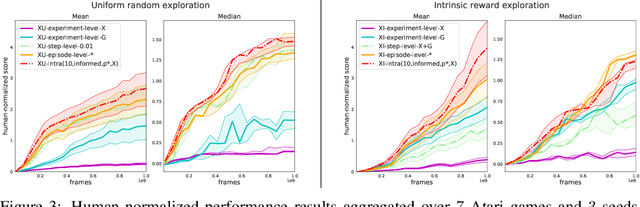
Exploration remains a central challenge for reinforcement learning (RL). Virtually all existing methods share the feature of a monolithic behaviour policy that changes only gradually (at best). In contrast, the exploratory behaviours of animals and humans exhibit a rich diversity, namely including forms of switching between modes. This paper presents an initial study of mode-switching, non-monolithic exploration for RL. We investigate different modes to switch between, at what timescales it makes sense to switch, and what signals make for good switching triggers. We also propose practical algorithmic components that make the switching mechanism adaptive and robust, which enables flexibility without an accompanying hyper-parameter-tuning burden. Finally, we report a promising and detailed analysis on Atari, using two-mode exploration and switching at sub-episodic time-scales.
Return-based Scaling: Yet Another Normalisation Trick for Deep RL
May 11, 2021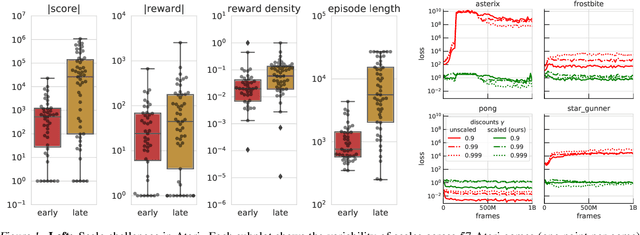
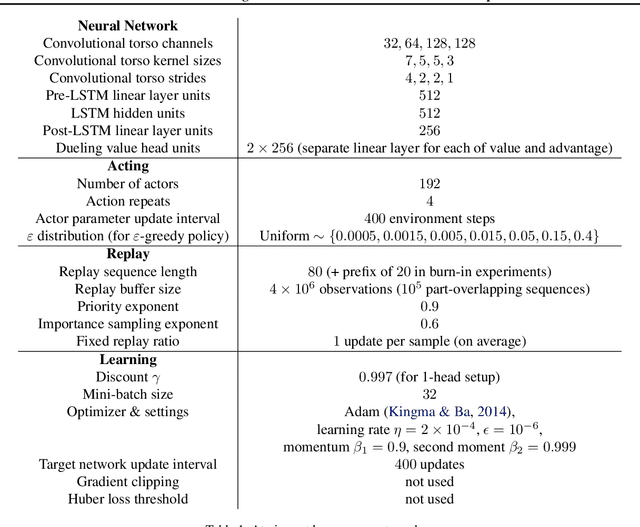
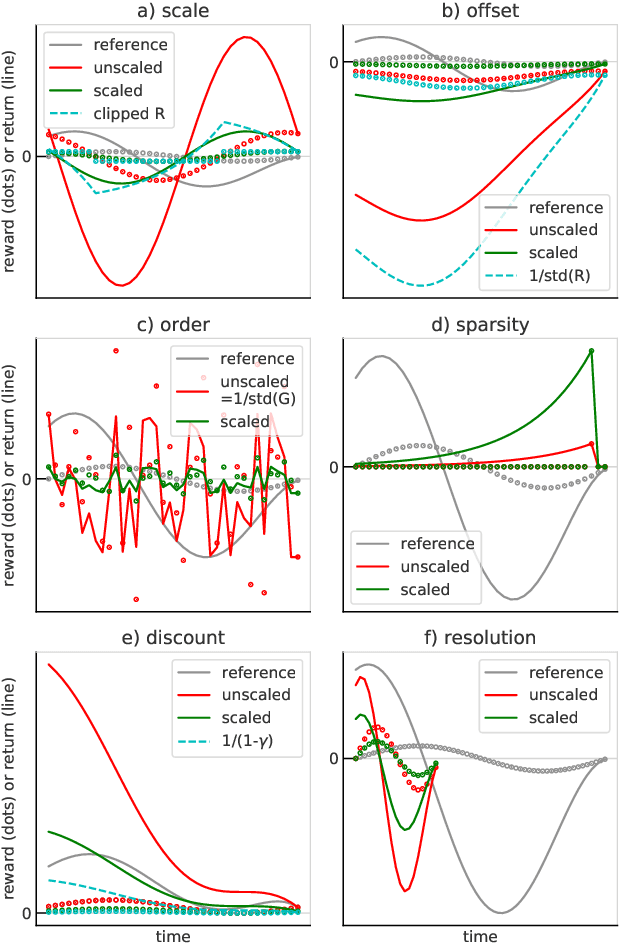
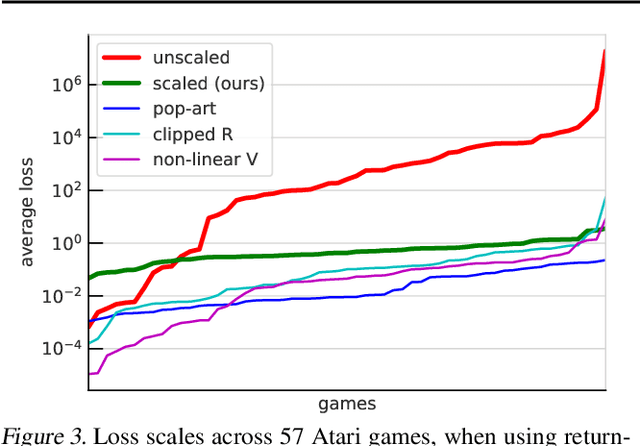
Scaling issues are mundane yet irritating for practitioners of reinforcement learning. Error scales vary across domains, tasks, and stages of learning; sometimes by many orders of magnitude. This can be detrimental to learning speed and stability, create interference between learning tasks, and necessitate substantial tuning. We revisit this topic for agents based on temporal-difference learning, sketch out some desiderata and investigate scenarios where simple fixes fall short. The mechanism we propose requires neither tuning, clipping, nor adaptation. We validate its effectiveness and robustness on the suite of Atari games. Our scaling method turns out to be particularly helpful at mitigating interference, when training a shared neural network on multiple targets that differ in reward scale or discounting.
Policy Evaluation Networks
Feb 26, 2020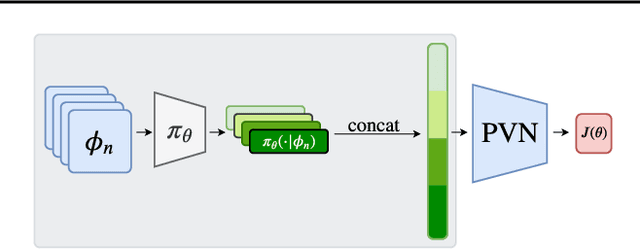
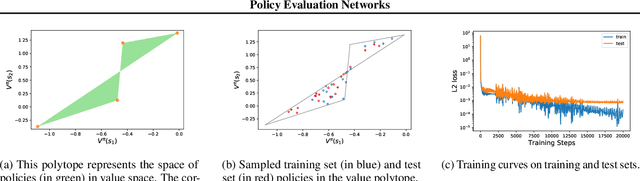
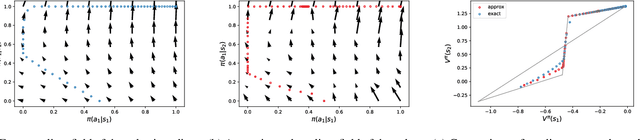
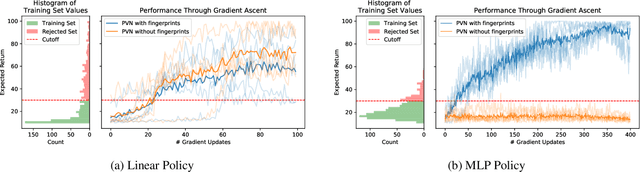
Many reinforcement learning algorithms use value functions to guide the search for better policies. These methods estimate the value of a single policy while generalizing across many states. The core idea of this paper is to flip this convention and estimate the value of many policies, for a single set of states. This approach opens up the possibility of performing direct gradient ascent in policy space without seeing any new data. The main challenge for this approach is finding a way to represent complex policies that facilitates learning and generalization. To address this problem, we introduce a scalable, differentiable fingerprinting mechanism that retains essential policy information in a concise embedding. Our empirical results demonstrate that combining these three elements (learned Policy Evaluation Network, policy fingerprints, gradient ascent) can produce policies that outperform those that generated the training data, in zero-shot manner.
Adapting Behaviour for Learning Progress
Dec 14, 2019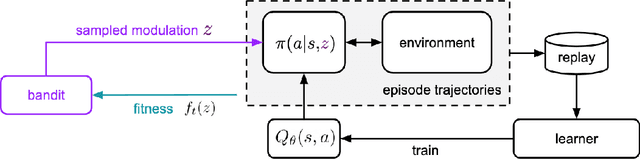

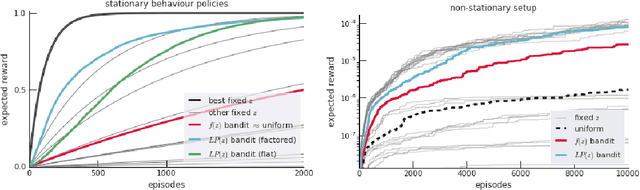
Determining what experience to generate to best facilitate learning (i.e. exploration) is one of the distinguishing features and open challenges in reinforcement learning. The advent of distributed agents that interact with parallel instances of the environment has enabled larger scales and greater flexibility, but has not removed the need to tune exploration to the task, because the ideal data for the learning algorithm necessarily depends on its process of learning. We propose to dynamically adapt the data generation by using a non-stationary multi-armed bandit to optimize a proxy of the learning progress. The data distribution is controlled by modulating multiple parameters of the policy (such as stochasticity, consistency or optimism) without significant overhead. The adaptation speed of the bandit can be increased by exploiting the factored modulation structure. We demonstrate on a suite of Atari 2600 games how this unified approach produces results comparable to per-task tuning at a fraction of the cost.
Conditional Importance Sampling for Off-Policy Learning
Oct 16, 2019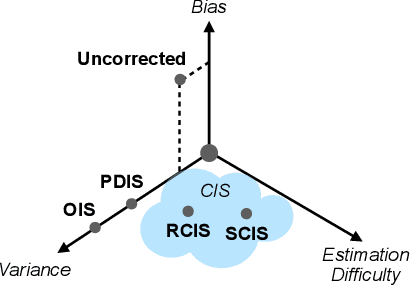

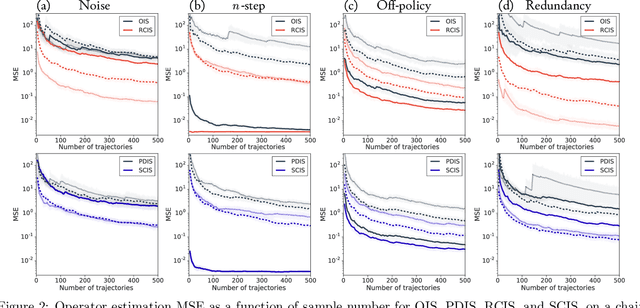
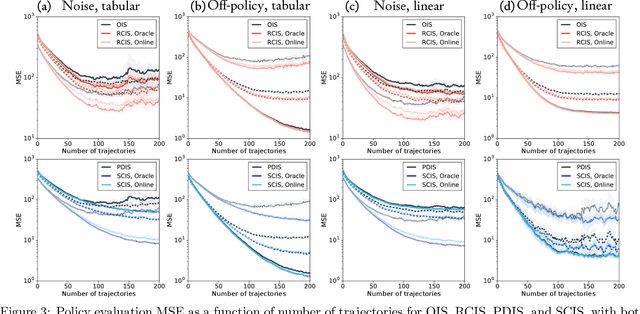
The principal contribution of this paper is a conceptual framework for off-policy reinforcement learning, based on conditional expectations of importance sampling ratios. This framework yields new perspectives and understanding of existing off-policy algorithms, and reveals a broad space of unexplored algorithms. We theoretically analyse this space, and concretely investigate several algorithms that arise from this framework.
Non-Differentiable Supervised Learning with Evolution Strategies and Hybrid Methods
Jun 07, 2019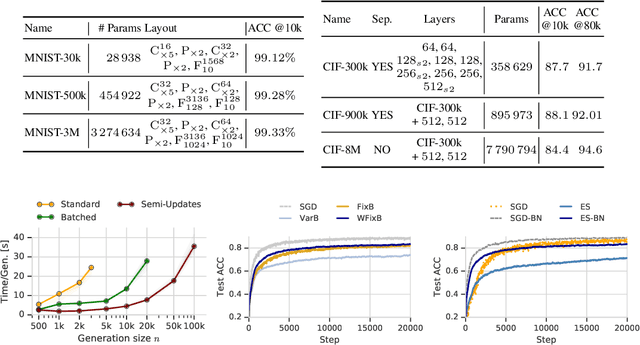

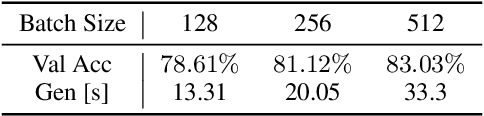

In this work we show that Evolution Strategies (ES) are a viable method for learning non-differentiable parameters of large supervised models. ES are black-box optimization algorithms that estimate distributions of model parameters; however they have only been used for relatively small problems so far. We show that it is possible to scale ES to more complex tasks and models with millions of parameters. While using ES for differentiable parameters is computationally impractical (although possible), we show that a hybrid approach is practically feasible in the case where the model has both differentiable and non-differentiable parameters. In this approach we use standard gradient-based methods for learning differentiable weights, while using ES for learning non-differentiable parameters - in our case sparsity masks of the weights. This proposed method is surprisingly competitive, and when parallelized over multiple devices has only negligible training time overhead compared to training with gradient descent. Additionally, this method allows to train sparse models from the first training step, so they can be much larger than when using methods that require training dense models first. We present results and analysis of supervised feed-forward models (such as MNIST and CIFAR-10 classification), as well as recurrent models, such as SparseWaveRNN for text-to-speech.
Ray Interference: a Source of Plateaus in Deep Reinforcement Learning
Apr 25, 2019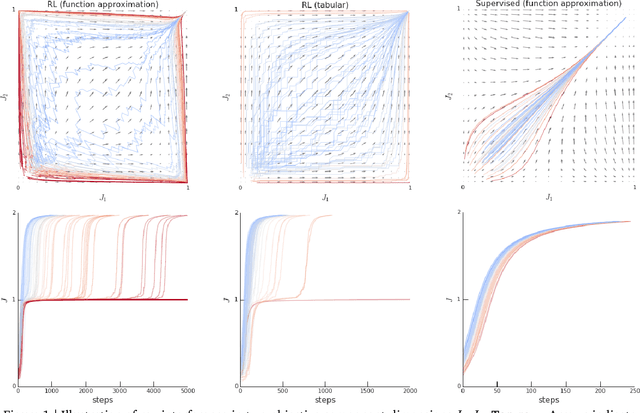
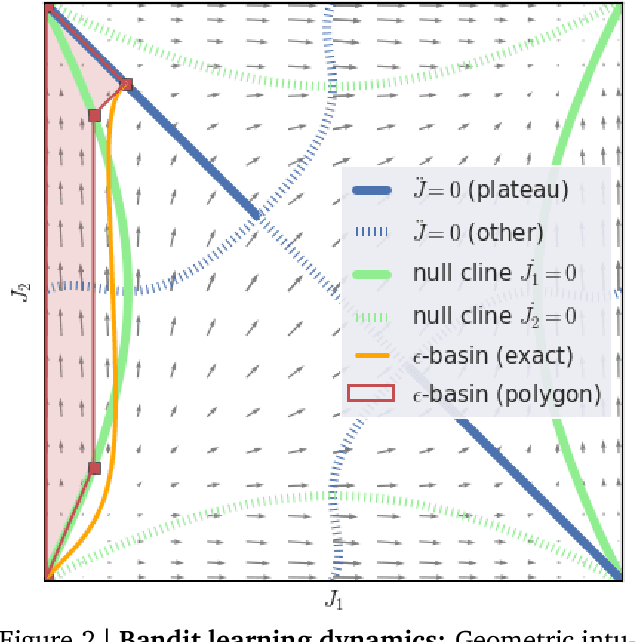
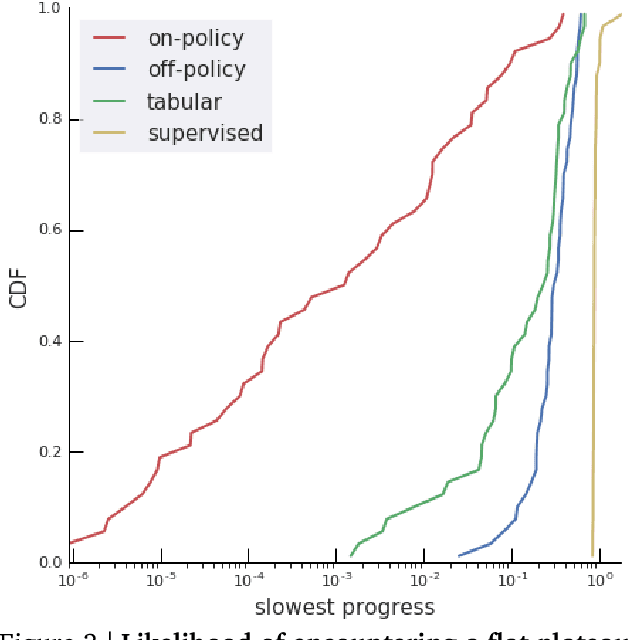
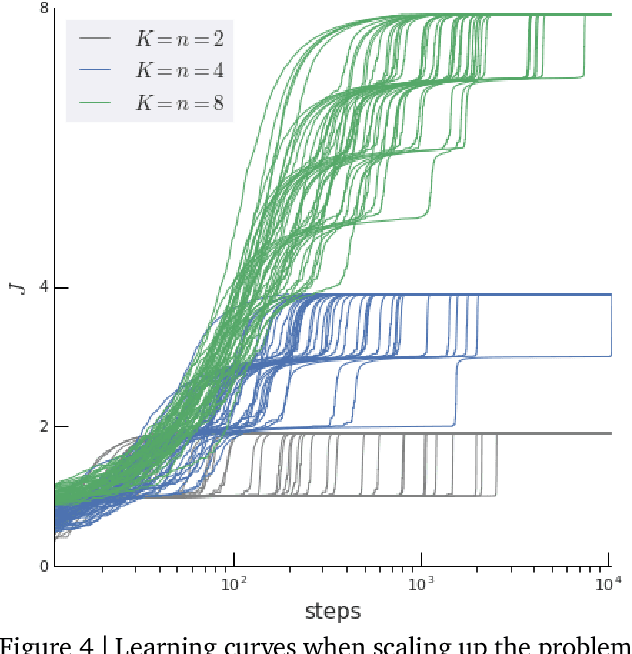
Rather than proposing a new method, this paper investigates an issue present in existing learning algorithms. We study the learning dynamics of reinforcement learning (RL), specifically a characteristic coupling between learning and data generation that arises because RL agents control their future data distribution. In the presence of function approximation, this coupling can lead to a problematic type of 'ray interference', characterized by learning dynamics that sequentially traverse a number of performance plateaus, effectively constraining the agent to learn one thing at a time even when learning in parallel is better. We establish the conditions under which ray interference occurs, show its relation to saddle points and obtain the exact learning dynamics in a restricted setting. We characterize a number of its properties and discuss possible remedies.
Transfer in Deep Reinforcement Learning Using Successor Features and Generalised Policy Improvement
Jan 30, 2019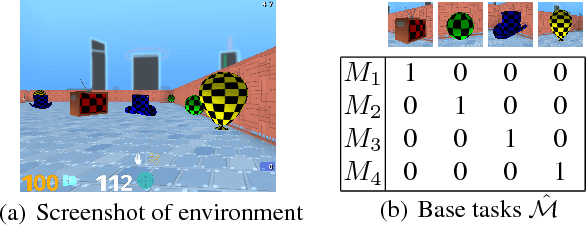
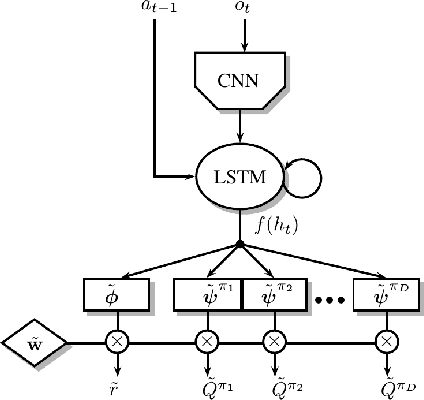
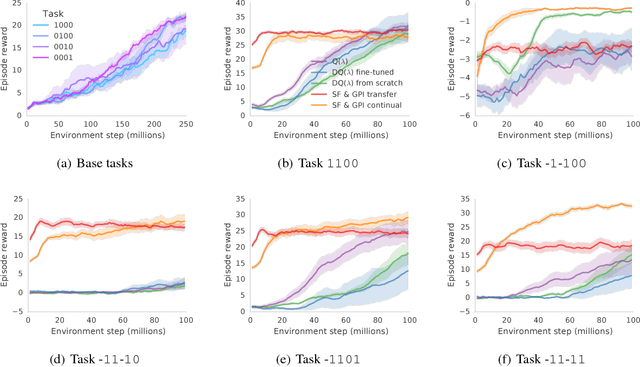
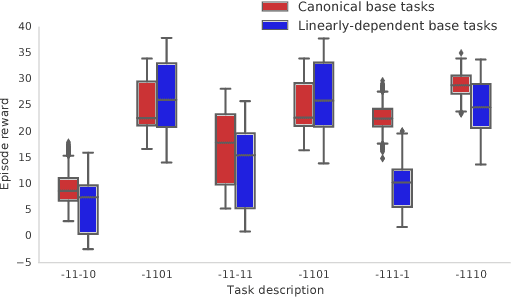
The ability to transfer skills across tasks has the potential to scale up reinforcement learning (RL) agents to environments currently out of reach. Recently, a framework based on two ideas, successor features (SFs) and generalised policy improvement (GPI), has been introduced as a principled way of transferring skills. In this paper we extend the SFs & GPI framework in two ways. One of the basic assumptions underlying the original formulation of SFs & GPI is that rewards for all tasks of interest can be computed as linear combinations of a fixed set of features. We relax this constraint and show that the theoretical guarantees supporting the framework can be extended to any set of tasks that only differ in the reward function. Our second contribution is to show that one can use the reward functions themselves as features for future tasks, without any loss of expressiveness, thus removing the need to specify a set of features beforehand. This makes it possible to combine SFs & GPI with deep learning in a more stable way. We empirically verify this claim on a complex 3D environment where observations are images from a first-person perspective. We show that the transfer promoted by SFs & GPI leads to very good policies on unseen tasks almost instantaneously. We also describe how to learn policies specialised to the new tasks in a way that allows them to be added to the agent's set of skills, and thus be reused in the future.
Universal Successor Features Approximators
Dec 18, 2018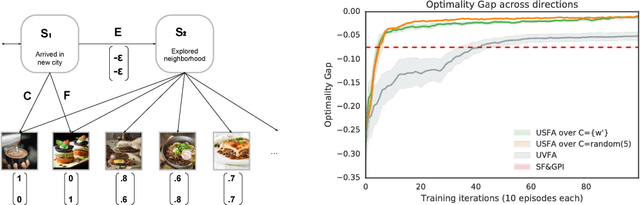

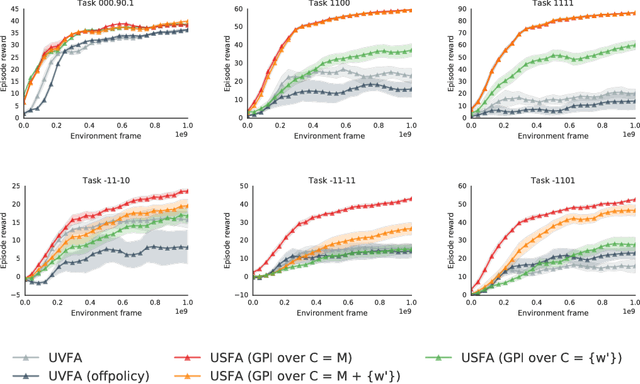

The ability of a reinforcement learning (RL) agent to learn about many reward functions at the same time has many potential benefits, such as the decomposition of complex tasks into simpler ones, the exchange of information between tasks, and the reuse of skills. We focus on one aspect in particular, namely the ability to generalise to unseen tasks. Parametric generalisation relies on the interpolation power of a function approximator that is given the task description as input; one of its most common form are universal value function approximators (UVFAs). Another way to generalise to new tasks is to exploit structure in the RL problem itself. Generalised policy improvement (GPI) combines solutions of previous tasks into a policy for the unseen task; this relies on instantaneous policy evaluation of old policies under the new reward function, which is made possible through successor features (SFs). Our proposed universal successor features approximators (USFAs) combine the advantages of all of these, namely the scalability of UVFAs, the instant inference of SFs, and the strong generalisation of GPI. We discuss the challenges involved in training a USFA, its generalisation properties and demonstrate its practical benefits and transfer abilities on a large-scale domain in which the agent has to navigate in a first-person perspective three-dimensional environment.