 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Your Center: 3D Object Detection Using a Learned Loss
Apr 06, 2020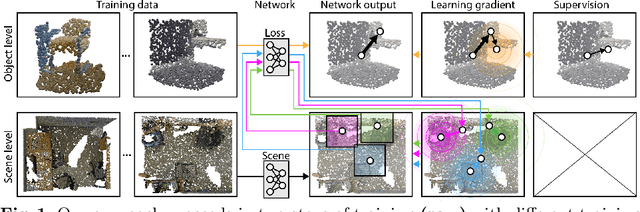
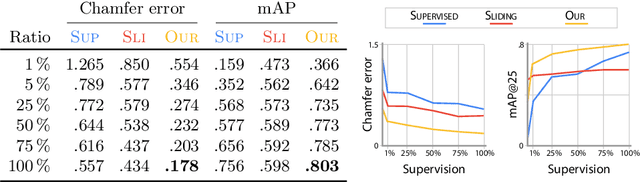

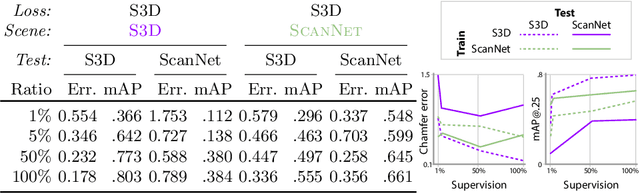
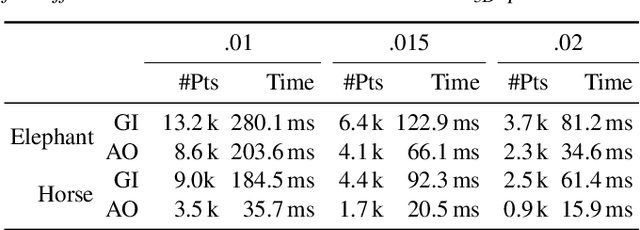
Massive semantic labeling is readily available for 2D images, but much harder to achieve for 3D scenes. Objects in 3D repositories like ShapeNet are labeled, but regrettably only in isolation, so without context. 3D scenes can be acquired by range scanners on city-level scale, but much fewer with semantic labels. Addressing this disparity, we introduce a new optimization procedure, which allows training for 3D detection with raw 3D scans while using as little as 5% of the object labels and still achieve comparable performance. Our optimization uses two networks. A scene network maps an entire 3D scene to a set of 3D object centers. As we assume the scene not to be labeled by centers, no classic loss, such as chamfer can be used to train it. Instead, we use another network to emulate the loss. This loss network is trained on a small labeled subset and maps a non-centered 3D object in the presence of distractions to its own center. This function is very similar - and hence can be used instead of - the gradient the supervised loss would have. Our evaluation documents competitive fidelity at a much lower level of supervision, respectively higher quality at comparable supervision. Supplementary material can be found at: https://dgriffiths3.github.io.
Learning a Neural 3D Texture Space from 2D Exemplars
Dec 09, 2019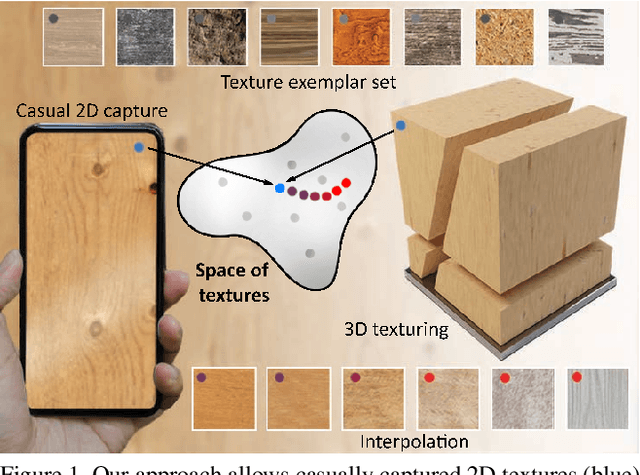

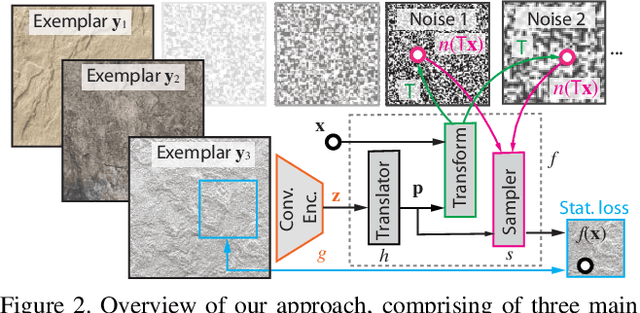
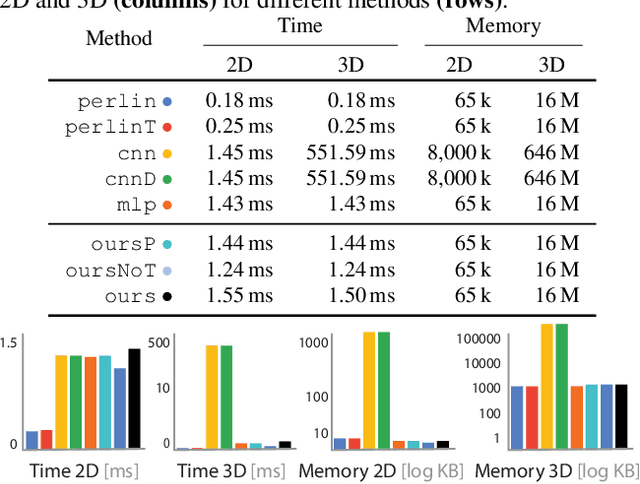
We propose a generative model of 2D and 3D natural textures with diversity, visual fidelity and at high computational efficiency. This is enabled by a family of methods that extend ideas from classic stochastic procedural texturing (Perlin noise) to learned, deep, non-linearities. The key idea is a hard-coded, tunable and differentiable step that feeds multiple transformed random 2D or 3D fields into an MLP that can be sampled over infinite domains. Our model encodes all exemplars from a diverse set of textures without a need to be re-trained for each exemplar. Applications include texture interpolation, and learning 3D textures from 2D exemplars.
Neural View-Interpolation for Sparse Light Field Video
Nov 06, 2019
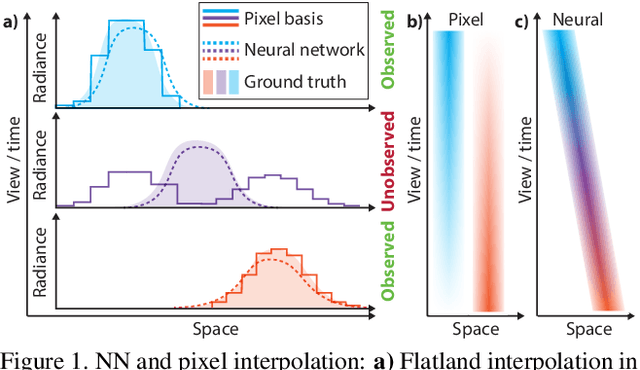

We suggest representing light field (LF) videos as "one-off" neural networks (NN), i.e., a learned mapping from view-plus-time coordinates to high-resolution color values, trained on sparse views. Initially, this sounds like a bad idea for three main reasons: First, a NN LF will likely have less quality than a same-sized pixel basis representation. Second, only few training data, e.g., 9 exemplars per frame are available for sparse LF videos. Third, there is no generalization across LFs, but across view and time instead. Consequently, a network needs to be trained for each LF video. Surprisingly, these problems can turn into substantial advantages: Other than the linear pixel basis, a NN has to come up with a compact, non-linear i.e., more intelligent, explanation of color, conditioned on the sparse view and time coordinates. As observed for many NN however, this representation now is interpolatable: if the image output for sparse view coordinates is plausible, it is for all intermediate, continuous coordinates as well. Our specific network architecture involves a differentiable occlusion-aware warping step, which leads to a compact set of trainable parameters and consequently fast learning and fast execution.
Total Denoising: Unsupervised Learning of 3D Point Cloud Cleaning
Apr 16, 2019

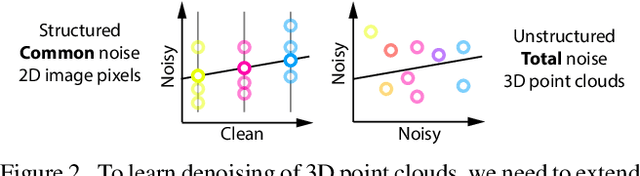

We show that denoising of 3D point clouds can be learned unsupervised, directly from noisy 3D point cloud data only. This is achieved by extending recent ideas from learning of unsupervised image denoisers to unstructured 3D point clouds. Unsupervised image denoisers operate under the assumption that a noisy pixel observation is a random realization of a distribution around a clean pixel value, which allows appropriate learning on this distribution to eventually converge to the correct value. Regrettably, this assumption is not valid for unstructured points: 3D point clouds are subject to total noise, i. e., deviations in all coordinates, with no reliable pixel grid. Thus, an observation can be the realization of an entire manifold of clean 3D points, which makes a na\"ive extension of unsupervised image denoisers to 3D point clouds impractical. Overcoming this, we introduce a spatial prior term, that steers converges to the unique closest out of the many possible modes on a manifold. Our results demonstrate unsupervised denoising performance similar to that of supervised learning with clean data when given enough training examples - whereby we do not need any pairs of noisy and clean training data.
Escaping Plato's Cave using Adversarial Training: 3D Shape From Unstructured 2D Image Collections
Nov 28, 2018
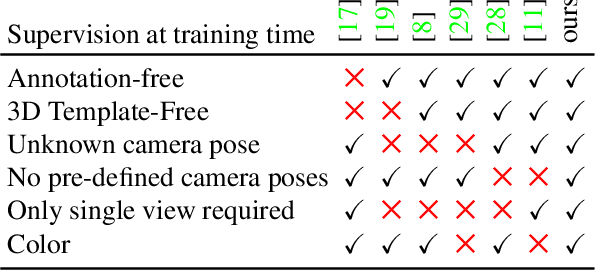

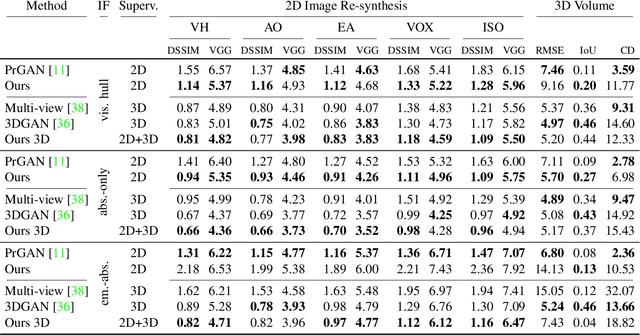
We develop PlatonicGAN to discover 3D structure of an object class from an unstructured collection of 2D images. The key idea is to learn a deep neural network that generates 3D shapes that are never objectionable to a discriminator looking only at its 2D projections, i.e. renderings of the generated volumes. Using such a 2D instead of a 3D discriminator allows tapping into massive 2D image collections instead of relying on much smaller 3D data sets. To establish constraints between 2D image observation and their 3D interpretation we suggest a family of rendering layers that are effectively back-propagatable. This family includes visual hull, absorption-only (akin to x-ray), and emission-absorption (that can resolve occlusion if multiple 3D points project to the same 2D pixel). These layers are studied both on synthetic and real data in an application to reconstruct of 3D shape from 2D images.
Deep-learning the Latent Space of Light Transport
Nov 12, 2018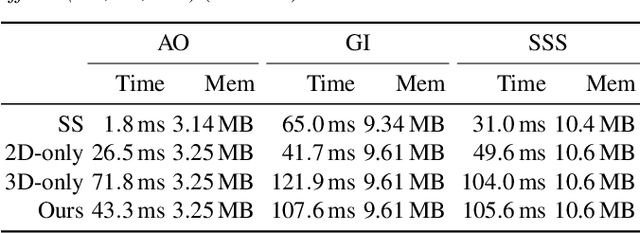

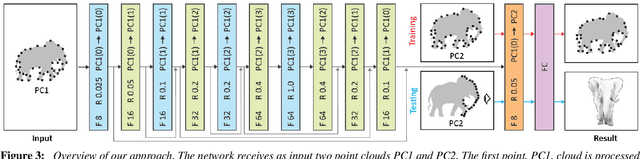
We suggest a method to directly deep-learn light transport, i. e., the mapping from a 3D geometry-illumination-material configuration to a shaded 2D image. While many previous learning methods have employed 2D convolutional neural networks applied to images, we show for the first time that light transport can be learned directly in 3D. The benefit of 3D over 2D is, that the former can also correctly capture illumination effects related to occluded and/or semi-transparent geometry. To learn 3D light transport, we represent the 3D scene as an unstructured 3D point cloud, which is later, during rendering, projected to the 2D output image. Thus, we suggest a two-stage operator comprising of a 3D network that first transforms the point cloud into a latent representation, which is later on projected to the 2D output image using a dedicated 3D-2D network in a second step. We will show that our approach results in improved quality in terms of temporal coherence while retaining most of the computational efficiency of common 2D methods. As a consequence, the proposed two stage-operator serves as a valuable extension to modern deferred shading approaches.
Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds
Sep 25, 2018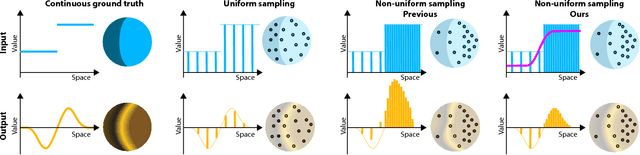

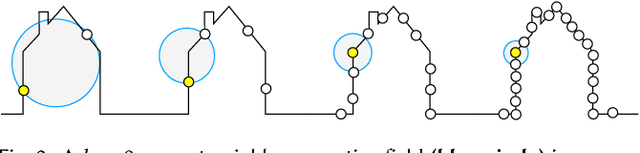
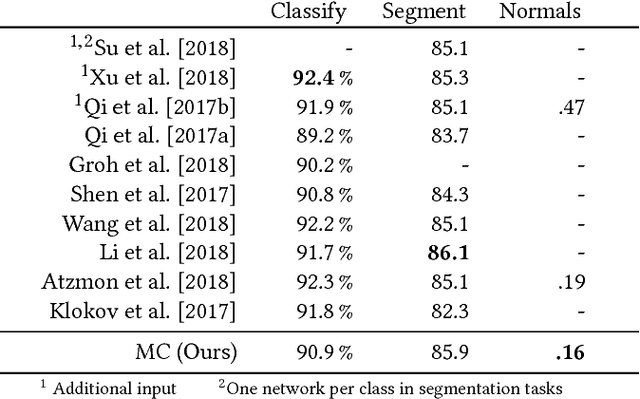
Deep learning systems extensively use convolution operations to process input data. Though convolution is clearly defined for structured data such as 2D images or 3D volumes, this is not true for other data types such as sparse point clouds. Previous techniques have developed approximations to convolutions for restricted conditions. Unfortunately, their applicability is limited and cannot be used for general point clouds. We propose an efficient and effective method to learn convolutions for non-uniformly sampled point clouds, as they are obtained with modern acquisition techniques. Learning is enabled by four key novelties: first, representing the convolution kernel itself as a multilayer perceptron; second, phrasing convolution as a Monte Carlo integration problem, third, using this notion to combine information from multiple samplings at different levels; and fourth using Poisson disk sampling as a scalable means of hierarchical point cloud learning. The key idea across all these contributions is to guarantee adequate consideration of the underlying non-uniform sample distribution function from a Monte Carlo perspective. To make the proposed concepts applicable to real-world tasks, we furthermore propose an efficient implementation which significantly reduces the GPU memory required during the training process. By employing our method in hierarchical network architectures we can outperform most of the state-of-the-art networks on established point cloud segmentation, classification and normal estimation benchmarks. Furthermore, in contrast to most existing approaches, we also demonstrate the robustness of our method with respect to sampling variations, even when training with uniformly sampled data only. To support the direct application of these concepts, we provide a ready-to-use TensorFlow implementation of these layers at https://github.com/viscom-ulm/MCCNN
Learning on the Edge: Explicit Boundary Handling in CNNs
May 08, 2018
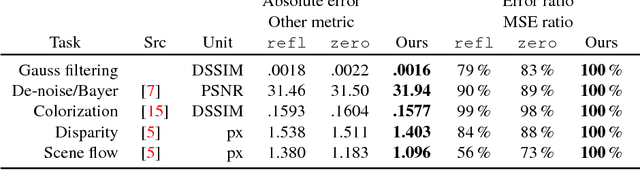
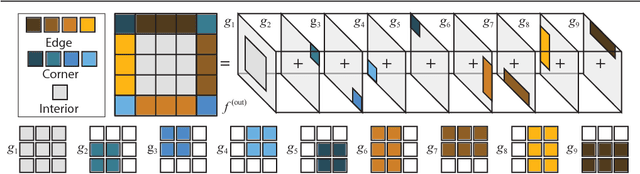
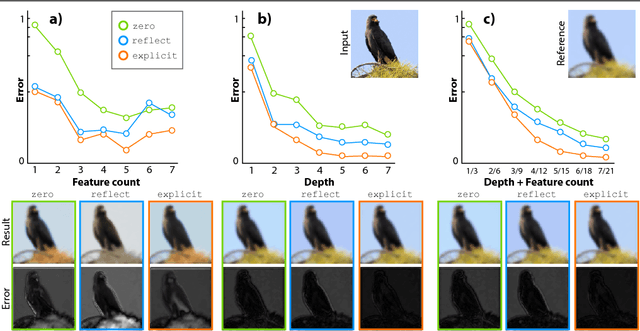
Convolutional neural networks (CNNs) handle the case where filters extend beyond the image boundary using several heuristics, such as zero, repeat or mean padding. These schemes are applied in an ad-hoc fashion and, being weakly related to the image content and oblivious of the target task, result in low output quality at the boundary. In this paper, we propose a simple and effective improvement that learns the boundary handling itself. At training-time, the network is provided with a separate set of explicit boundary filters. At testing-time, we use these filters which have learned to extrapolate features at the boundary in an optimal way for the specific task. Our extensive evaluation, over a wide range of architectural changes (variations of layers, feature channels, or both), shows how the explicit filters result in improved boundary handling. Consequently, we demonstrate an improvement of 5% to 20% across the board of typical CNN applications (colorization, de-Bayering, optical flow, and disparity estimation).
Deep Appearance Maps
Apr 03, 2018
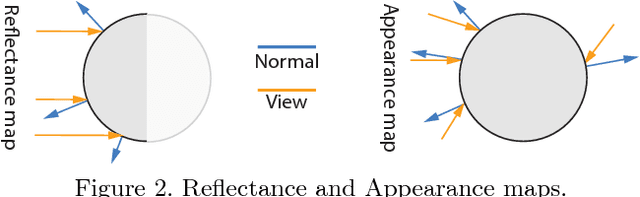

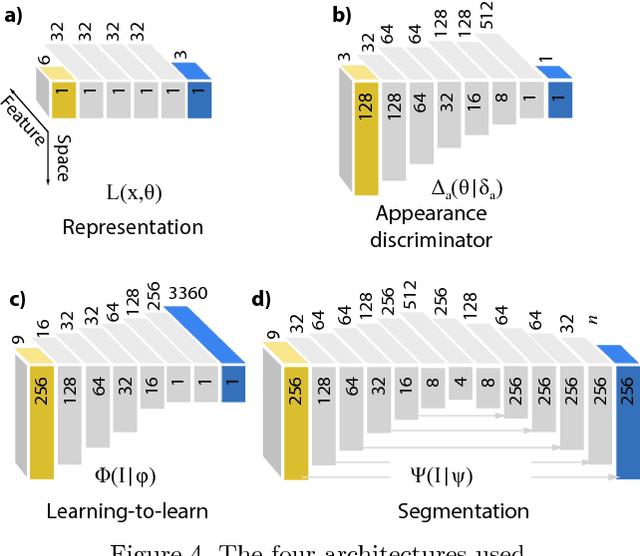
We propose a deep representation of appearance, i. e. the relation of color, surface orientation, viewer position, material and illumination. Previous approaches have used deep learning to extract classic appearance representations relating to reflectance model parameters (e. g. Phong) or illumination (e. g. HDR environment maps). We suggest to directly represent appearance itself as a network we call a deep appearance map (DAM). This is a 4D generalization over 2D reflectance maps, which held the view direction fixed. First, we show how a DAM can be learned from images or video frames and later be used to synthesize appearance, given new surface orientations and viewer positions. Second, we demonstrate how another network can be used to map from an image or video frames to a DAM network to reproduce this appearance, without using a lengthy optimization such as stochastic gradient descent (learning-to-learn). Finally, we generalize this to an appearance estimation-and-segmentation task, where we map from an image showing multiple materials to multiple networks reproducing their appearance, as well as per-pixel segmentation.
What Is Around The Camera?
Aug 01, 2017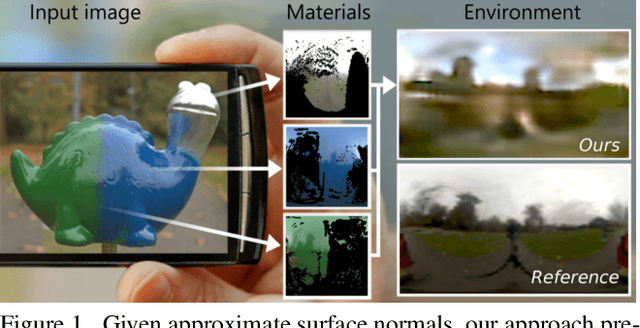
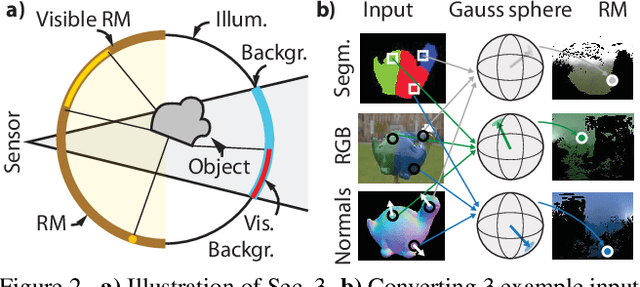

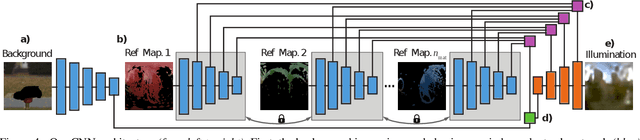
How much does a single image reveal about the environment it was taken in? In this paper, we investigate how much of that information can be retrieved from a foreground object, combined with the background (i.e. the visible part of the environment). Assuming it is not perfectly diffuse, the foreground object acts as a complexly shaped and far-from-perfect mirror. An additional challenge is that its appearance confounds the light coming from the environment with the unknown materials it is made of. We propose a learning-based approach to predict the environment from multiple reflectance maps that are computed from approximate surface normals. The proposed method allows us to jointly model the statistics of environments and material properties. We train our system from synthesized training data, but demonstrate its applicability to real-world data. Interestingly, our analysis shows that the information obtained from objects made out of multiple materials often is complementary and leads to better performance.