 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Re-Simulation for Generating Bounces in Single Images
Aug 24, 2019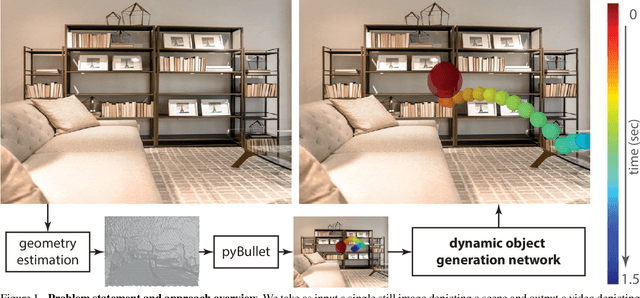
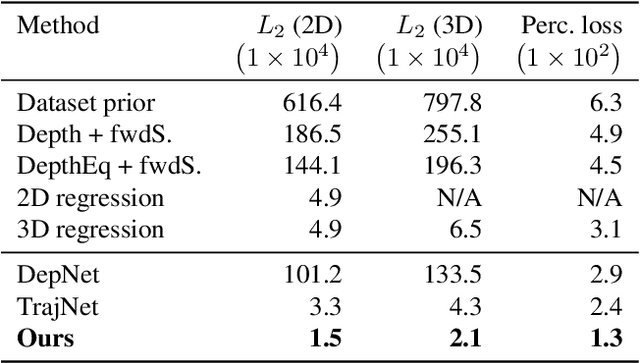

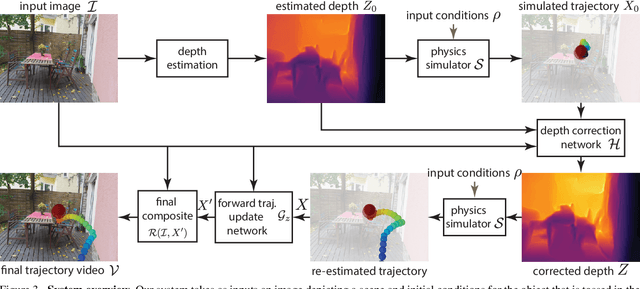
We introduce a method to generate videos of dynamic virtual objects plausibly interacting via collisions with a still image's environment. Given a starting trajectory, physically simulated with the estimated geometry of a single, static input image, we learn to 'correct' this trajectory to a visually plausible one via a neural network. The neural network can then be seen as learning to 'correct' traditional simulation output, generated with incomplete and imprecise world information, to obtain context-specific, visually plausible re-simulated output, a process we call neural re-simulation. We train our system on a set of 50k synthetic scenes where a virtual moving object (ball) has been physically simulated. We demonstrate our approach on both our synthetic dataset and a collection of real-life images depicting everyday scenes, obtaining consistent improvement over baseline alternatives throughout.
Learning on the Edge: Explicit Boundary Handling in CNNs
May 08, 2018
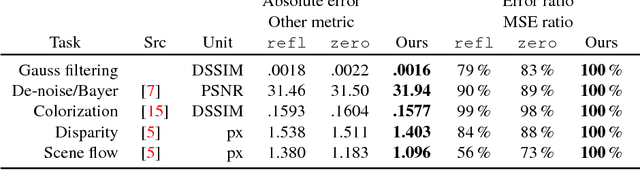
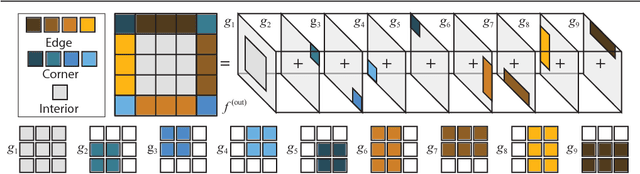
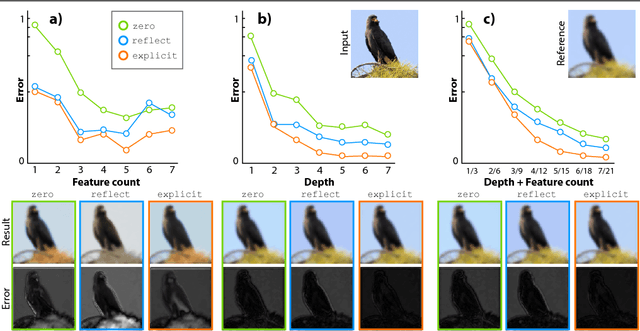
Convolutional neural networks (CNNs) handle the case where filters extend beyond the image boundary using several heuristics, such as zero, repeat or mean padding. These schemes are applied in an ad-hoc fashion and, being weakly related to the image content and oblivious of the target task, result in low output quality at the boundary. In this paper, we propose a simple and effective improvement that learns the boundary handling itself. At training-time, the network is provided with a separate set of explicit boundary filters. At testing-time, we use these filters which have learned to extrapolate features at the boundary in an optimal way for the specific task. Our extensive evaluation, over a wide range of architectural changes (variations of layers, feature channels, or both), shows how the explicit filters result in improved boundary handling. Consequently, we demonstrate an improvement of 5% to 20% across the board of typical CNN applications (colorization, de-Bayering, optical flow, and disparity estimation).