 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVizCV: AI-assisted visualization of researchers' publications tracks
May 13, 2025



Analyzing how the publication records of scientists and research groups have evolved over the years is crucial for assessing their expertise since it can support the management of academic environments by assisting with career planning and evaluation. We introduce VizCV, a novel web-based end-to-end visual analytics framework that enables the interactive exploration of researchers' scientific trajectories. It incorporates AI-assisted analysis and supports automated reporting of career evolution. Our system aims to model career progression through three key dimensions: a) research topic evolution to detect and visualize shifts in scholarly focus over time, b) publication record and the corresponding impact, c) collaboration dynamics depicting the growth and transformation of a researcher's co-authorship network. AI-driven insights provide automated explanations of career transitions, detecting significant shifts in research direction, impact surges, or collaboration expansions. The system also supports comparative analysis between researchers, allowing users to compare topic trajectories and impact growth. Our interactive, multi-tab and multiview system allows for the exploratory analysis of career milestones under different perspectives, such as the most impactful articles, emerging research themes, or obtaining a detailed analysis of the contribution of the researcher in a subfield. The key contributions include AI/ML techniques for: a) topic analysis, b) dimensionality reduction for visualizing patterns and trends, c) the interactive creation of textual descriptions of facets of data through configurable prompt generation and large language models, that include key indicators, to help understanding the career development of individuals or groups.
AI-in-the-loop: The future of biomedical visual analytics applications in the era of AI
Dec 20, 2024


AI is the workhorse of modern data analytics and omnipresent across many sectors. Large Language Models and multi-modal foundation models are today capable of generating code, charts, visualizations, etc. How will these massive developments of AI in data analytics shape future data visualizations and visual analytics workflows? What is the potential of AI to reshape methodology and design of future visual analytics applications? What will be our role as visualization researchers in the future? What are opportunities, open challenges and threats in the context of an increasingly powerful AI? This Visualization Viewpoint discusses these questions in the special context of biomedical data analytics as an example of a domain in which critical decisions are taken based on complex and sensitive data, with high requirements on transparency, efficiency, and reliability. We map recent trends and developments in AI on the elements of interactive visualization and visual analytics workflows and highlight the potential of AI to transform biomedical visualization as a research field. Given that agency and responsibility have to remain with human experts, we argue that it is helpful to keep the focus on human-centered workflows, and to use visual analytics as a tool for integrating ``AI-in-the-loop''. This is in contrast to the more traditional term ``human-in-the-loop'', which focuses on incorporating human expertise into AI-based systems.
Multilingual, Multi-scale and Multi-layer Visualization of Intermediate Representations
Jul 01, 2019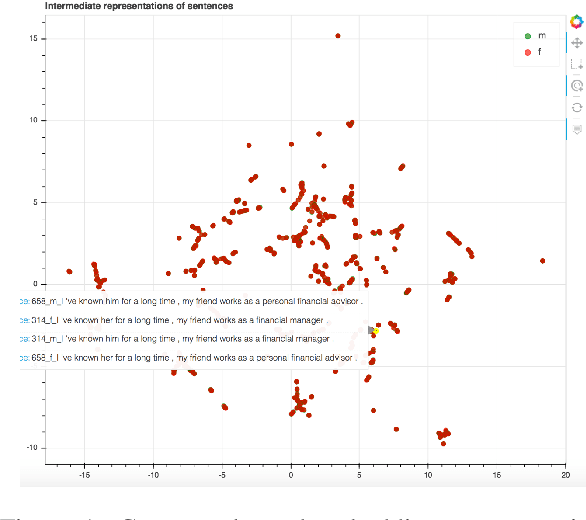
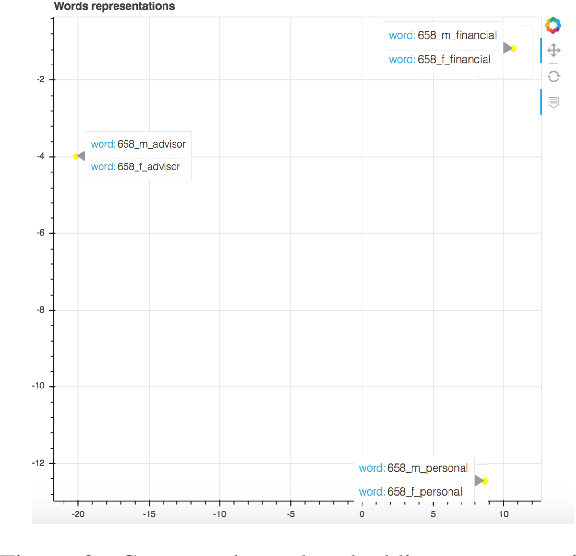
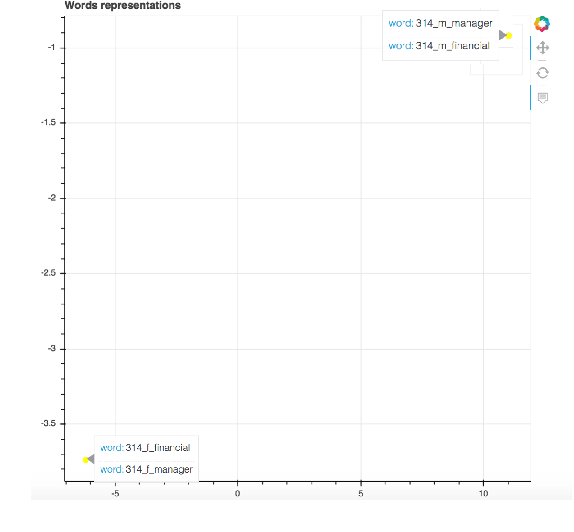
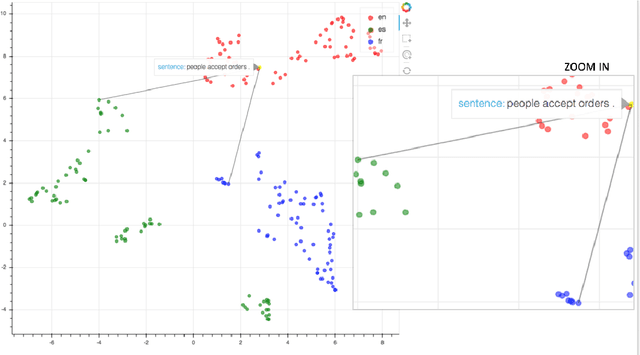
The main alternatives nowadays to deal with sequences are Recurrent Neural Networks (RNN), Convolutional Neural Networks (CNN) architectures and the Transformer. In this context, RNN's, CNN's and Transformer have most commonly been used as an encoder-decoder architecture with multiple layers in each module. Far beyond this, these architectures are the basis for the contextual word embeddings which are revolutionizing most natural language downstream applications. However, intermediate layer representations in sequence-based architectures can be difficult to interpret. To make each layer representation within these architectures more accessible and meaningful, we introduce a web-based tool that visualizes them both at the sentence and token level. We present three use cases. The first analyses gender issues in contextual word embeddings. The second and third are showing multilingual intermediate representations for sentences and tokens and the evolution of these intermediate representations along the multiple layers of the decoder and in the context of multilingual machine translation.
Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds
Sep 25, 2018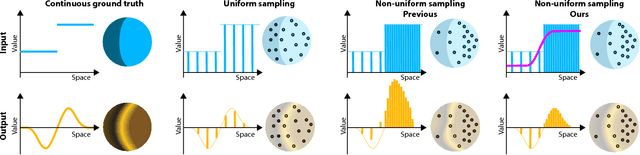

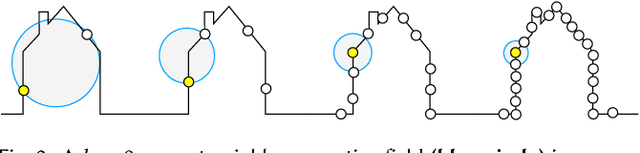
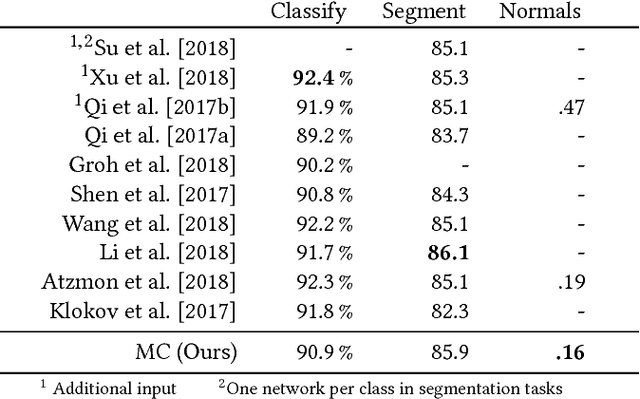
Deep learning systems extensively use convolution operations to process input data. Though convolution is clearly defined for structured data such as 2D images or 3D volumes, this is not true for other data types such as sparse point clouds. Previous techniques have developed approximations to convolutions for restricted conditions. Unfortunately, their applicability is limited and cannot be used for general point clouds. We propose an efficient and effective method to learn convolutions for non-uniformly sampled point clouds, as they are obtained with modern acquisition techniques. Learning is enabled by four key novelties: first, representing the convolution kernel itself as a multilayer perceptron; second, phrasing convolution as a Monte Carlo integration problem, third, using this notion to combine information from multiple samplings at different levels; and fourth using Poisson disk sampling as a scalable means of hierarchical point cloud learning. The key idea across all these contributions is to guarantee adequate consideration of the underlying non-uniform sample distribution function from a Monte Carlo perspective. To make the proposed concepts applicable to real-world tasks, we furthermore propose an efficient implementation which significantly reduces the GPU memory required during the training process. By employing our method in hierarchical network architectures we can outperform most of the state-of-the-art networks on established point cloud segmentation, classification and normal estimation benchmarks. Furthermore, in contrast to most existing approaches, we also demonstrate the robustness of our method with respect to sampling variations, even when training with uniformly sampled data only. To support the direct application of these concepts, we provide a ready-to-use TensorFlow implementation of these layers at https://github.com/viscom-ulm/MCCNN