 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Noise Scheduling for Diffusion Models
Jan 27, 2023



We empirically study the effect of noise scheduling strategies for denoising diffusion generative models. There are three findings: (1) the noise scheduling is crucial for the performance, and the optimal one depends on the task (e.g., image sizes), (2) when increasing the image size, the optimal noise scheduling shifts towards a noisier one (due to increased redundancy in pixels), and (3) simply scaling the input data by a factor of $b$ while keeping the noise schedule function fixed (equivalent to shifting the logSNR by $\log b$) is a good strategy across image sizes. This simple recipe, when combined with recently proposed Recurrent Interface Network (RIN), yields state-of-the-art pixel-based diffusion models for high-resolution images on ImageNet, enabling single-stage, end-to-end generation of diverse and high-fidelity images at 1024$\times$1024 resolution (without upsampling/cascades).
Scalable Adaptive Computation for Iterative Generation
Dec 22, 2022



We present the Recurrent Interface Network (RIN), a neural net architecture that allocates computation adaptively to the input according to the distribution of information, allowing it to scale to iterative generation of high-dimensional data. Hidden units of RINs are partitioned into the interface, which is locally connected to inputs, and latents, which are decoupled from inputs and can exchange information globally. The RIN block selectively reads from the interface into latents for high-capacity processing, with incremental updates written back to the interface. Stacking multiple blocks enables effective routing across local and global levels. While routing adds overhead, the cost can be amortized in recurrent computation settings where inputs change gradually while more global context persists, such as iterative generation using diffusion models. To this end, we propose a latent self-conditioning technique that "warm-starts" the latents at each iteration of the generation process. When applied to diffusion models operating directly on pixels, RINs yield state-of-the-art image and video generation without cascades or guidance, while being domain-agnostic and up to 10$\times$ more efficient compared to specialized 2D and 3D U-Nets.
An automated approach to extracting positive and negative clinical research results
Dec 07, 2022



Failure is common in clinical trials since the successful failures presented in negative results always indicate the ways that should not be taken. In this paper, we proposed an automated approach to extracting positive and negative clinical research results by introducing a PICOE (Population, Intervention, Comparation, Outcome, and Effect) framework to represent randomized controlled trials (RCT) reports, where E indicates the effect between a specific I and O. We developed a pipeline to extract and assign the corresponding statistical effect to a specific I-O pair from natural language RCT reports. The extraction models achieved a high degree of accuracy for ICO and E descriptive words extraction through two rounds of training. By defining a threshold of p-value, we find in all Covid-19 related intervention-outcomes pairs with statistical tests, negative results account for nearly 40%. We believe that this observation is noteworthy since they are extracted from the published literature, in which there is an inherent risk of reporting bias, preferring to report positive results rather than negative results. We provided a tool to systematically understand the current level of clinical evidence by distinguishing negative results from the positive results.
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
Nov 21, 2022Visual anomaly detection, an important problem in computer vision, is usually formulated as a one-class classification and segmentation task. The student-teacher (S-T) framework has proved to be effective in solving this challenge. However, previous works based on S-T only empirically applied constraints on normal data and fused multi-level information. In this study, we propose an improved model called DeSTSeg, which integrates a pre-trained teacher network, a denoising student encoder-decoder, and a segmentation network into one framework. First, to strengthen the constraints on anomalous data, we introduce a denoising procedure that allows the student network to learn more robust representations. From synthetically corrupted normal images, we train the student network to match the teacher network feature of the same images without corruption. Second, to fuse the multi-level S-T features adaptively, we train a segmentation network with rich supervision from synthetic anomaly masks, achieving a substantial performance improvement. Experiments on the industrial inspection benchmark dataset demonstrate that our method achieves state-of-the-art performance, 98.6% on image-level ROC, 75.8% on pixel-level average precision, and 76.4% on instance-level average precision.
A Generalist Framework for Panoptic Segmentation of Images and Videos
Oct 12, 2022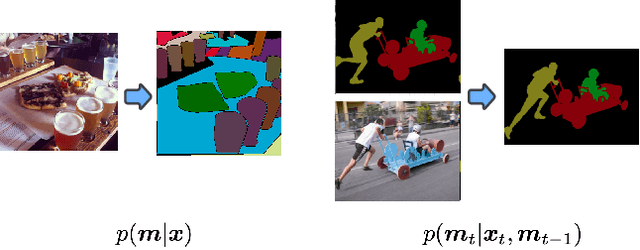
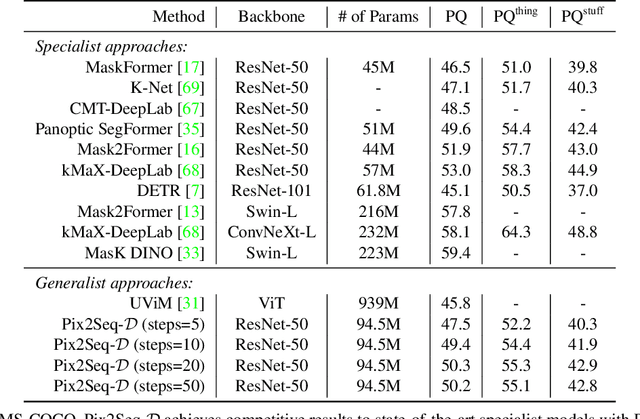
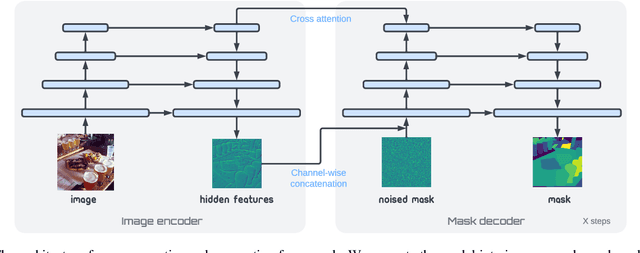
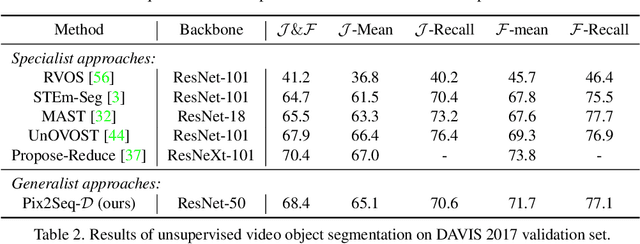
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
Aug 08, 2022
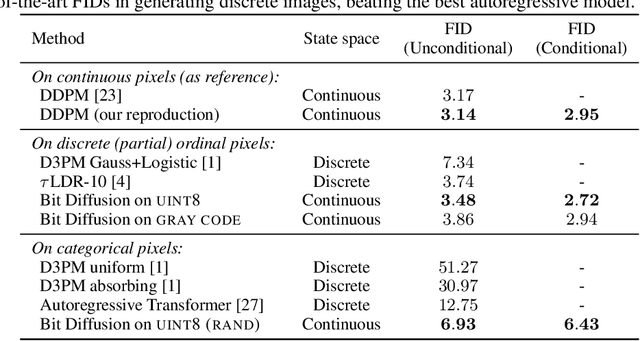


We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and ImageNet-64x64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
Robust Learning of Deep Time Series Anomaly Detection Models with Contaminated Training Data
Aug 03, 2022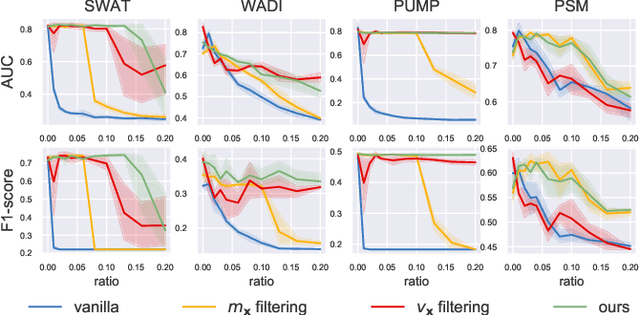
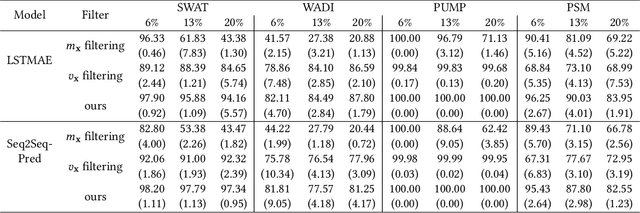
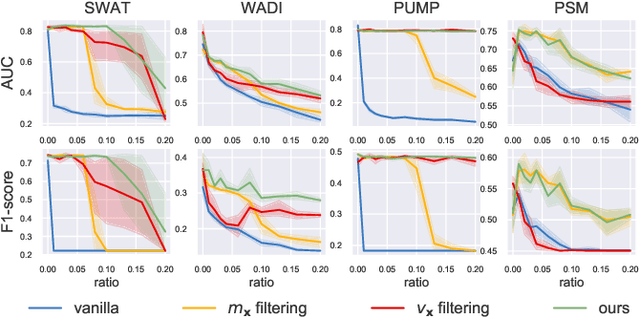
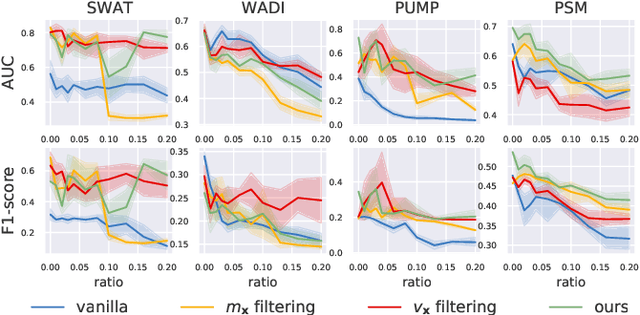
Time series anomaly detection (TSAD) is an important data mining task with numerous applications in the IoT era. In recent years, a large number of deep neural network-based methods have been proposed, demonstrating significantly better performance than conventional methods on addressing challenging TSAD problems in a variety of areas. Nevertheless, these deep TSAD methods typically rely on a clean training dataset that is not polluted by anomalies to learn the "normal profile" of the underlying dynamics. This requirement is nontrivial since a clean dataset can hardly be provided in practice. Moreover, without the awareness of their robustness, blindly applying deep TSAD methods with potentially contaminated training data can possibly incur significant performance degradation in the detection phase. In this work, to tackle this important challenge, we firstly investigate the robustness of commonly used deep TSAD methods with contaminated training data which provides a guideline for applying these methods when the provided training data are not guaranteed to be anomaly-free. Furthermore, we propose a model-agnostic method which can effectively improve the robustness of learning mainstream deep TSAD models with potentially contaminated data. Experiment results show that our method can consistently prevent or mitigate performance degradation of mainstream deep TSAD models on widely used benchmark datasets.
DGPO: Discovering Multiple Strategies with Diversity-Guided Policy Optimization
Jul 12, 2022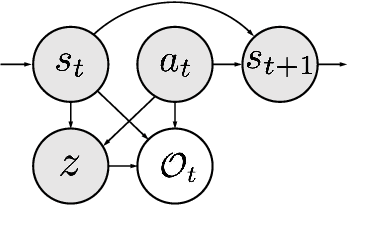

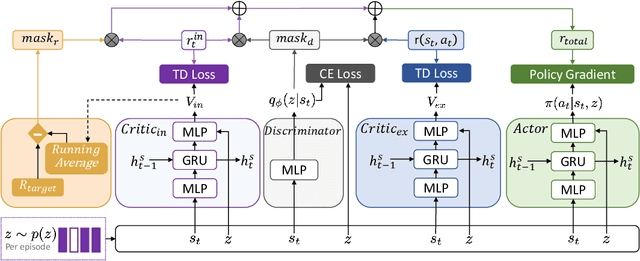
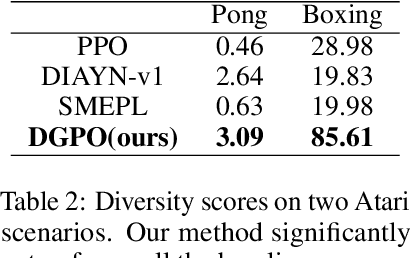
Recent algorithms designed for reinforcement learning tasks focus on finding a single optimal solution. However, in many practical applications, it is important to develop reasonable agents with diverse strategies. In this paper, we propose Diversity-Guided Policy Optimization (DGPO), an on-policy framework for discovering multiple strategies for the same task. Our algorithm uses diversity objectives to guide a latent code conditioned policy to learn a set of diverse strategies in a single training procedure. Specifically, we formalize our algorithm as the combination of a diversity-constrained optimization problem and an extrinsic-reward constrained optimization problem. And we solve the constrained optimization as a probabilistic inference task and use policy iteration to maximize the derived lower bound. Experimental results show that our method efficiently finds diverse strategies in a wide variety of reinforcement learning tasks. We further show that DGPO achieves a higher diversity score and has similar sample complexity and performance compared to other baselines.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022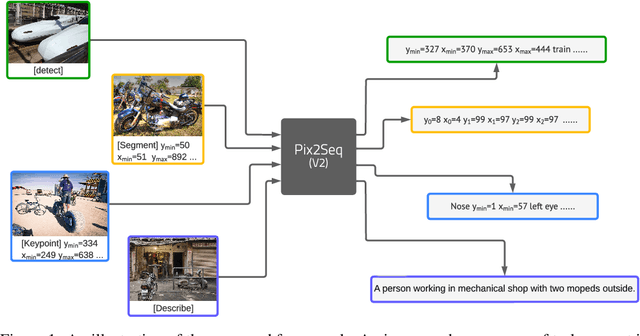
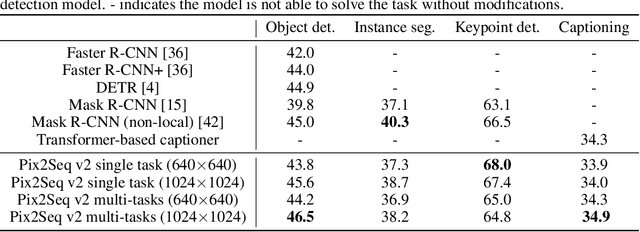
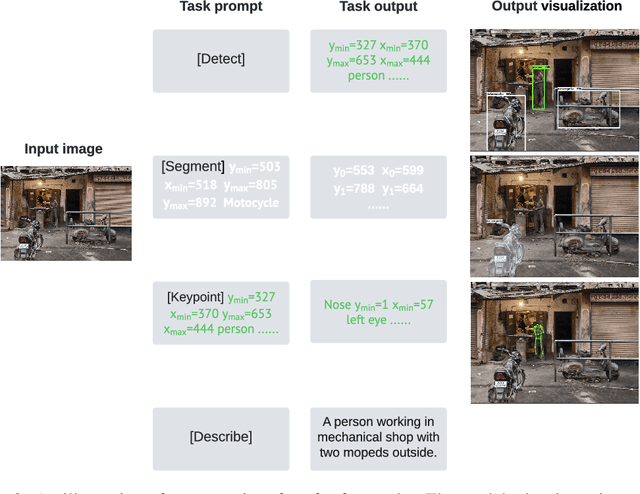

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
Scalable Online Disease Diagnosis via Multi-Model-Fused Actor-Critic Reinforcement Learning
Jun 08, 2022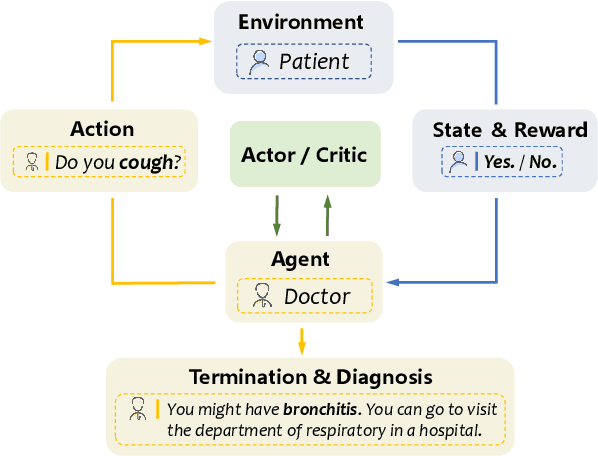

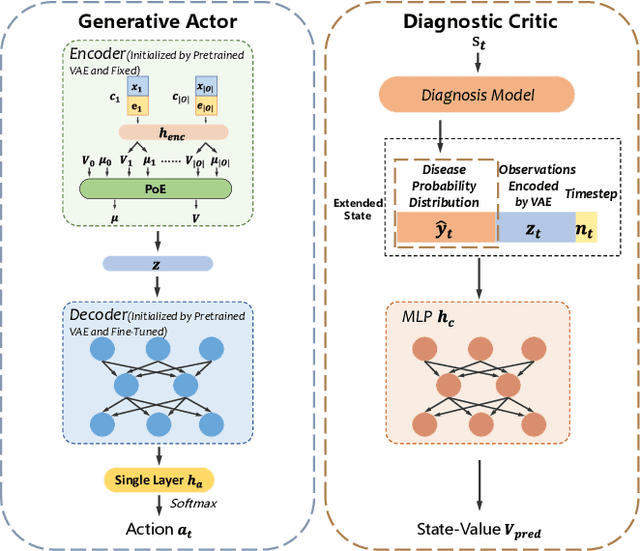
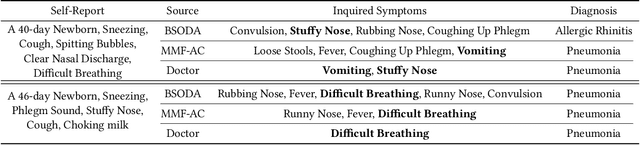
For those seeking healthcare advice online, AI based dialogue agents capable of interacting with patients to perform automatic disease diagnosis are a viable option. This application necessitates efficient inquiry of relevant disease symptoms in order to make accurate diagnosis recommendations. This can be formulated as a problem of sequential feature (symptom) selection and classification for which reinforcement learning (RL) approaches have been proposed as a natural solution. They perform well when the feature space is small, that is, the number of symptoms and diagnosable disease categories is limited, but they frequently fail in assignments with a large number of features. To address this challenge, we propose a Multi-Model-Fused Actor-Critic (MMF-AC) RL framework that consists of a generative actor network and a diagnostic critic network. The actor incorporates a Variational AutoEncoder (VAE) to model the uncertainty induced by partial observations of features, thereby facilitating in making appropriate inquiries. In the critic network, a supervised diagnosis model for disease predictions is involved to precisely estimate the state-value function. Furthermore, inspired by the medical concept of differential diagnosis, we combine the generative and diagnosis models to create a novel reward shaping mechanism to address the sparse reward problem in large search spaces. We conduct extensive experiments on both synthetic and real-world datasets for empirical evaluations. The results demonstrate that our approach outperforms state-of-the-art methods in terms of diagnostic accuracy and interaction efficiency while also being more effectively scalable to large search spaces. Besides, our method is adaptable to both categorical and continuous features, making it ideal for online applications.