 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Regularisation for Recurrent Image Annotation
Nov 16, 2016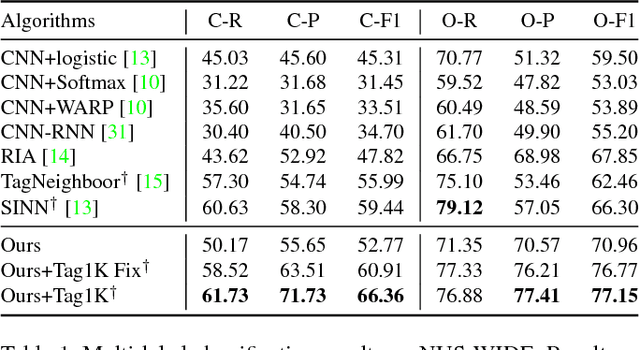

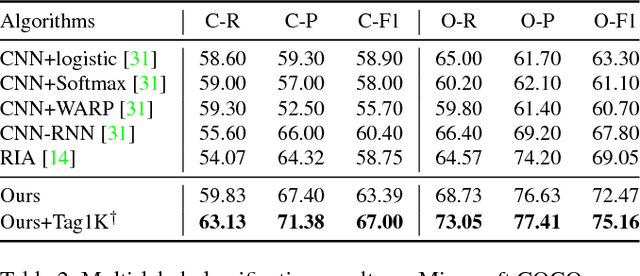

The "CNN-RNN" design pattern is increasingly widely applied in a variety of image annotation tasks including multi-label classification and captioning. Existing models use the weakly semantic CNN hidden layer or its transform as the image embedding that provides the interface between the CNN and RNN. This leaves the RNN overstretched with two jobs: predicting the visual concepts and modelling their correlations for generating structured annotation output. Importantly this makes the end-to-end training of the CNN and RNN slow and ineffective due to the difficulty of back propagating gradients through the RNN to train the CNN. We propose a simple modification to the design pattern that makes learning more effective and efficient. Specifically, we propose to use a semantically regularised embedding layer as the interface between the CNN and RNN. Regularising the interface can partially or completely decouple the learning problems, allowing each to be more effectively trained and jointly training much more efficient. Extensive experiments show that state-of-the art performance is achieved on multi-label classification as well as image captioning.
Robust Subjective Visual Property Prediction from Crowdsourced Pairwise Labels
Jul 27, 2015
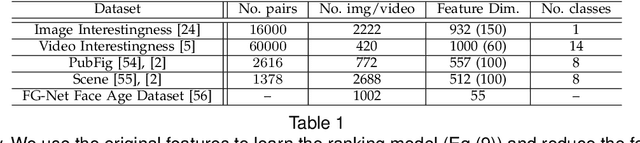
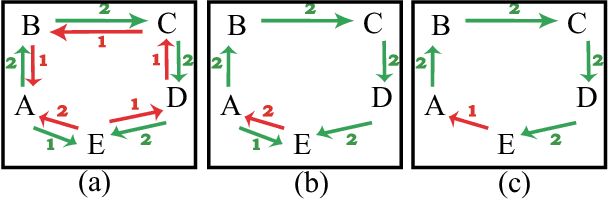
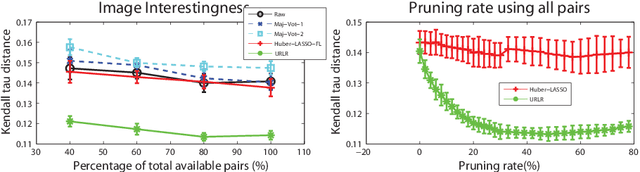
The problem of estimating subjective visual properties from image and video has attracted increasing interest. A subjective visual property is useful either on its own (e.g. image and video interestingness) or as an intermediate representation for visual recognition (e.g. a relative attribute). Due to its ambiguous nature, annotating the value of a subjective visual property for learning a prediction model is challenging. To make the annotation more reliable, recent studies employ crowdsourcing tools to collect pairwise comparison labels because human annotators are much better at ranking two images/videos (e.g. which one is more interesting) than giving an absolute value to each of them separately. However, using crowdsourced data also introduces outliers. Existing methods rely on majority voting to prune the annotation outliers/errors. They thus require large amount of pairwise labels to be collected. More importantly as a local outlier detection method, majority voting is ineffective in identifying outliers that can cause global ranking inconsistencies. In this paper, we propose a more principled way to identify annotation outliers by formulating the subjective visual property prediction task as a unified robust learning to rank problem, tackling both the outlier detection and learning to rank jointly. Differing from existing methods, the proposed method integrates local pairwise comparison labels together to minimise a cost that corresponds to global inconsistency of ranking order. This not only leads to better detection of annotation outliers but also enables learning with extremely sparse annotations. Extensive experiments on various benchmark datasets demonstrate that our new approach significantly outperforms state-of-the-arts alternatives.
Weakly Supervised Learning of Objects, Attributes and their Associations
Mar 31, 2015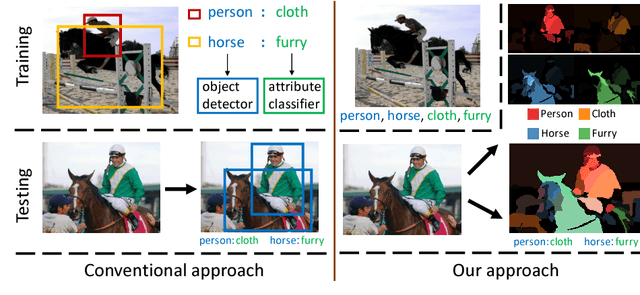
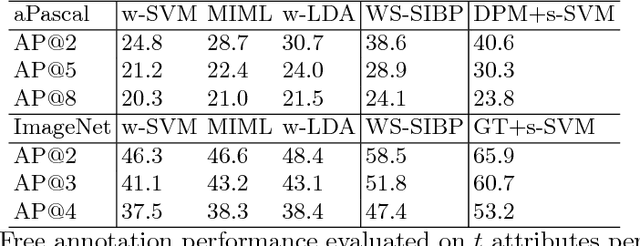
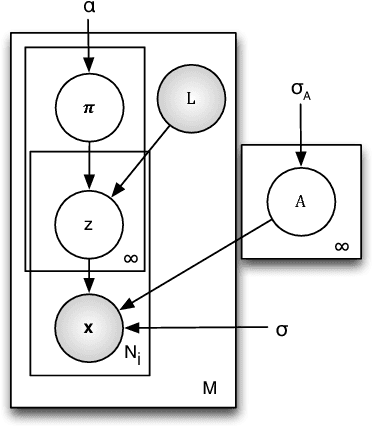
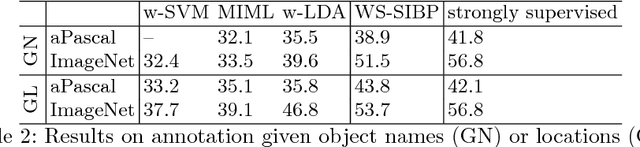
When humans describe images they tend to use combinations of nouns and adjectives, corresponding to objects and their associated attributes respectively. To generate such a description automatically, one needs to model objects, attributes and their associations. Conventional methods require strong annotation of object and attribute locations, making them less scalable. In this paper, we model object-attribute associations from weakly labelled images, such as those widely available on media sharing sites (e.g. Flickr), where only image-level labels (either object or attributes) are given, without their locations and associations. This is achieved by introducing a novel weakly supervised non-parametric Bayesian model. Once learned, given a new image, our model can describe the image, including objects, attributes and their associations, as well as their locations and segmentation. Extensive experiments on benchmark datasets demonstrate that our weakly supervised model performs at par with strongly supervised models on tasks such as image description and retrieval based on object-attribute associations.
Transductive Multi-class and Multi-label Zero-shot Learning
Mar 26, 2015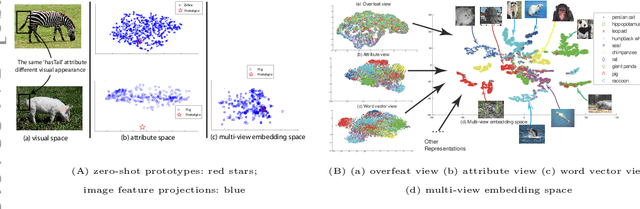

Recently, zero-shot learning (ZSL) has received increasing interest. The key idea underpinning existing ZSL approaches is to exploit knowledge transfer via an intermediate-level semantic representation which is assumed to be shared between the auxiliary and target datasets, and is used to bridge between these domains for knowledge transfer. The semantic representation used in existing approaches varies from visual attributes to semantic word vectors and semantic relatedness. However, the overall pipeline is similar: a projection mapping low-level features to the semantic representation is learned from the auxiliary dataset by either classification or regression models and applied directly to map each instance into the same semantic representation space where a zero-shot classifier is used to recognise the unseen target class instances with a single known 'prototype' of each target class. In this paper we discuss two related lines of work improving the conventional approach: exploiting transductive learning ZSL, and generalising ZSL to the multi-label case.
A Unified Perspective on Multi-Domain and Multi-Task Learning
Mar 26, 2015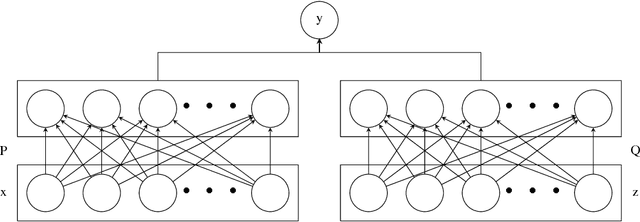
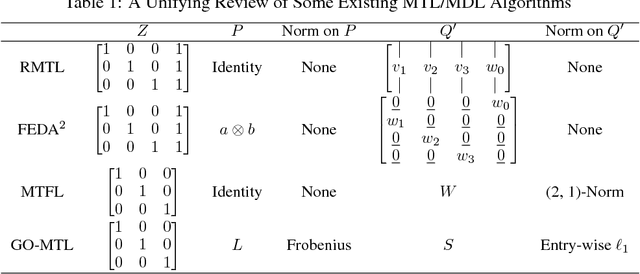


In this paper, we provide a new neural-network based perspective on multi-task learning (MTL) and multi-domain learning (MDL). By introducing the concept of a semantic descriptor, this framework unifies MDL and MTL as well as encompassing various classic and recent MTL/MDL algorithms by interpreting them as different ways of constructing semantic descriptors. Our interpretation provides an alternative pipeline for zero-shot learning (ZSL), where a model for a novel class can be constructed without training data. Moreover, it leads to a new and practically relevant problem setting of zero-shot domain adaptation (ZSDA), which is the analogous to ZSL but for novel domains: A model for an unseen domain can be generated by its semantic descriptor. Experiments across this range of problems demonstrate that our framework outperforms a variety of alternatives.
Transductive Multi-view Zero-Shot Learning
Mar 03, 2015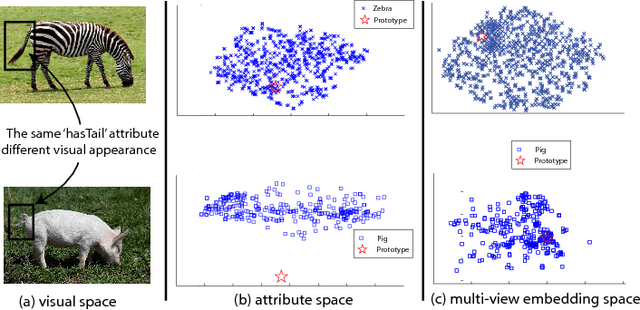
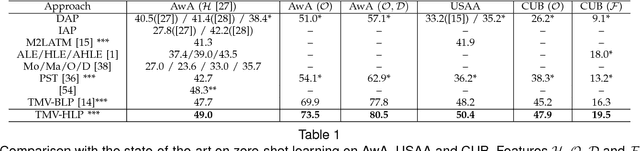
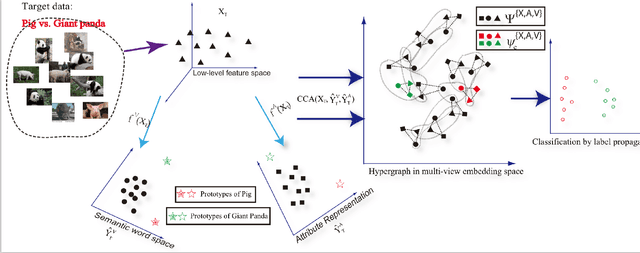
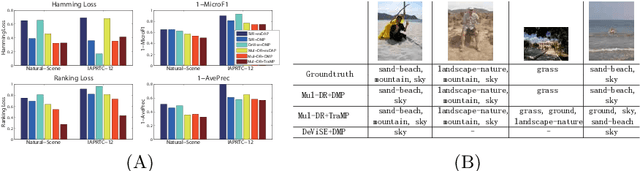
Most existing zero-shot learning approaches exploit transfer learning via an intermediate-level semantic representation shared between an annotated auxiliary dataset and a target dataset with different classes and no annotation. A projection from a low-level feature space to the semantic representation space is learned from the auxiliary dataset and is applied without adaptation to the target dataset. In this paper we identify two inherent limitations with these approaches. First, due to having disjoint and potentially unrelated classes, the projection functions learned from the auxiliary dataset/domain are biased when applied directly to the target dataset/domain. We call this problem the projection domain shift problem and propose a novel framework, transductive multi-view embedding, to solve it. The second limitation is the prototype sparsity problem which refers to the fact that for each target class, only a single prototype is available for zero-shot learning given a semantic representation. To overcome this problem, a novel heterogeneous multi-view hypergraph label propagation method is formulated for zero-shot learning in the transductive embedding space. It effectively exploits the complementary information offered by different semantic representations and takes advantage of the manifold structures of multiple representation spaces in a coherent manner. We demonstrate through extensive experiments that the proposed approach (1) rectifies the projection shift between the auxiliary and target domains, (2) exploits the complementarity of multiple semantic representations, (3) significantly outperforms existing methods for both zero-shot and N-shot recognition on three image and video benchmark datasets, and (4) enables novel cross-view annotation tasks.