 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Feb 12, 2026Time Series Foundation Models (TSFMs) achieve strong zero-shot forecasting through large-scale pre-training, but adapting them to downstream domains under distribution shift remains challenging. Existing solutions face a trade-off: Parametric Adaptation can cause catastrophic forgetting and requires costly multi-domain maintenance, while Non-Parametric Retrieval improves forecasts but incurs high inference latency due to datastore search. We propose Parametric Memory Distillation and implement it as TS-Memory, a lightweight memory adapter that augments frozen TSFMs. TS-Memory is trained in two stages. First, we construct an offline, leakage-safe kNN teacher that synthesizes confidence-aware quantile targets from retrieved futures. Second, we distill this retrieval-induced distributional correction into a lightweight memory adapter via confidence-gated supervision. During inference, TS-Memory fuses memory and backbone predictions with constant-time overhead, enabling retrieval-free deployment. Experiments across diverse TSFMs and benchmarks demonstrate consistent improvements in both point and probabilistic forecasting over representative adaptation methods, with efficiency comparable to the frozen backbone.
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
Jul 30, 2018
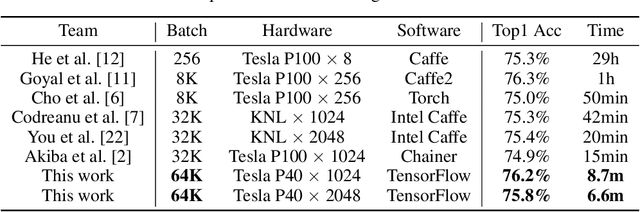

Synchronized stochastic gradient descent (SGD) optimizers with data parallelism are widely used in training large-scale deep neural networks. Although using larger mini-batch sizes can improve the system scalability by reducing the communication-to-computation ratio, it may hurt the generalization ability of the models. To this end, we build a highly scalable deep learning training system for dense GPU clusters with three main contributions: (1) We propose a mixed-precision training method that significantly improves the training throughput of a single GPU without losing accuracy. (2) We propose an optimization approach for extremely large mini-batch size (up to 64k) that can train CNN models on the ImageNet dataset without losing accuracy. (3) We propose highly optimized all-reduce algorithms that achieve up to 3x and 11x speedup on AlexNet and ResNet-50 respectively than NCCL-based training on a cluster with 1024 Tesla P40 GPUs. On training ResNet-50 with 90 epochs, the state-of-the-art GPU-based system with 1024 Tesla P100 GPUs spent 15 minutes and achieved 74.9\% top-1 test accuracy, and another KNL-based system with 2048 Intel KNLs spent 20 minutes and achieved 75.4\% accuracy. Our training system can achieve 75.8\% top-1 test accuracy in only 6.6 minutes using 2048 Tesla P40 GPUs. When training AlexNet with 95 epochs, our system can achieve 58.7\% top-1 test accuracy within 4 minutes, which also outperforms all other existing systems.