 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Neural Graph Databases
Sep 20, 2022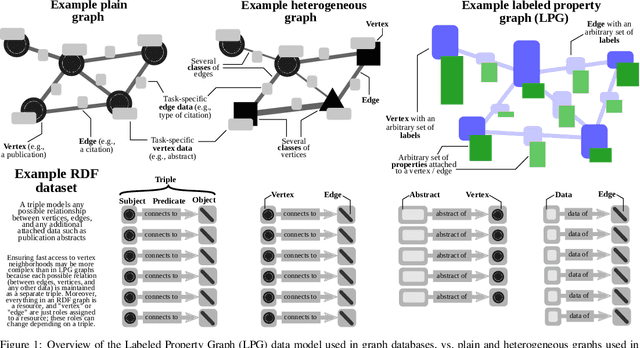

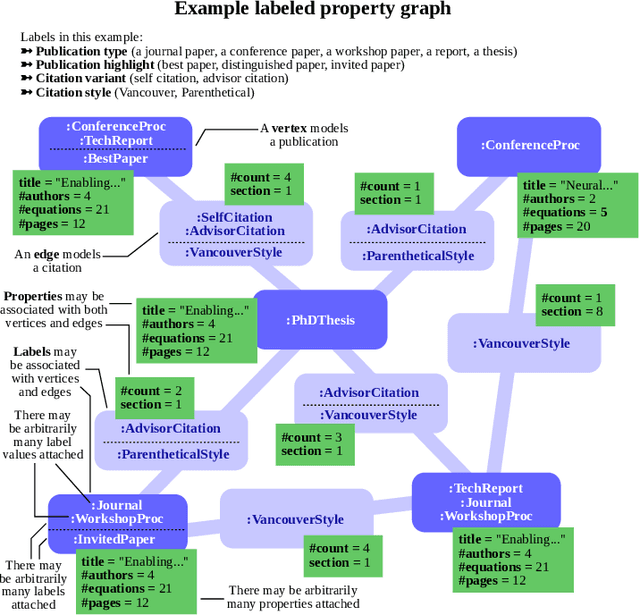
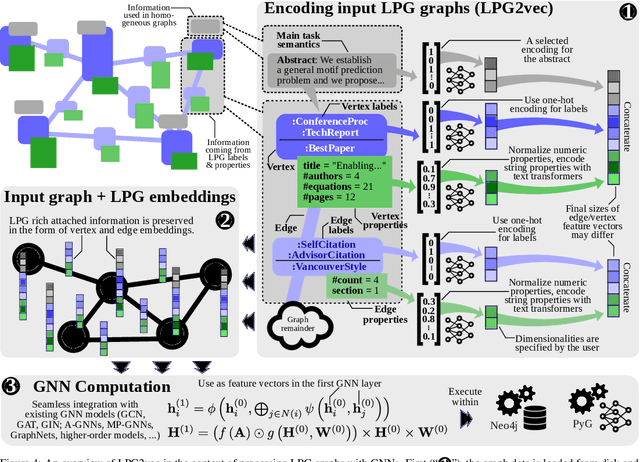
Graph databases (GDBs) enable processing and analysis of unstructured, complex, rich, and usually vast graph datasets. Despite the large significance of GDBs in both academia and industry, little effort has been made into integrating them with the predictive power of graph neural networks (GNNs). In this work, we show how to seamlessly combine nearly any GNN model with the computational capabilities of GDBs. For this, we observe that the majority of these systems are based on, or support, a graph data model called the Labeled Property Graph (LPG), where vertices and edges can have arbitrarily complex sets of labels and properties. We then develop LPG2vec, an encoder that transforms an arbitrary LPG dataset into a representation that can be directly used with a broad class of GNNs, including convolutional, attentional, message-passing, and even higher-order or spectral models. In our evaluation, we show that the rich information represented as LPG labels and properties is properly preserved by LPG2vec, and it increases the accuracy of predictions regardless of the targeted learning task or the used GNN model, by up to 34% compared to graphs with no LPG labels/properties. In general, LPG2vec enables combining predictive power of the most powerful GNNs with the full scope of information encoded in the LPG model, paving the way for neural graph databases, a class of systems where the vast complexity of maintained data will benefit from modern and future graph machine learning methods.