 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop Graph Algorithm Execution with Small Language Models: Step Accuracy and Rollout Reliability
Jun 23, 2026Small language models offer an efficient alternative to large-scale systems, but their ability to execute structured algorithms over multiple dependent decisions remains poorly understood. We study graph algorithm execution as a closed-loop prediction problem in which a model repeatedly selects the next action from the current graph and algorithmic state. Our evaluation framework covers several classical graph procedures, multiple synthetic graph families, and disjoint training, validation, and test partitions. It assesses both local decision quality and global execution behaviour using step accuracy, exact rollout accuracy, constraint validity, partial solution quality, prefix survival, and intervention-based diagnostics. The results show that adaptation can produce reliable policies for structural procedures such as traversal and coloring, while weighted algorithms remain substantially more sensitive to error accumulation. More broadly, the findings demonstrate that strong next-step prediction does not necessarily translate into reliable autonomous execution and motivate evaluating algorithmic language models through complete closed-loop rollouts rather than isolated decisions.
Generalization Boundaries of Fine-Tuned Small Language Models for Graph Structural Inference
Apr 20, 2026Small language models fine-tuned for graph property estimation have demonstrated strong in-distribution performance, yet their generalization capabilities beyond training conditions remain poorly understood. In this work, we systematically investigate the boundaries of structural inference in fine-tuned small language models along two generalization axes - graph size and graph family distribution - and assess domain-learning capability on real-world graph benchmarks. Using a controlled experimental setup with three instruction-tuned models in the 3-4B parameter class and two graph serialization formats, we evaluate performance on graphs substantially larger than the training range and across held-out random graph families. Our results show that fine-tuned models maintain strong ordinal consistency across structurally distinct graph families and continue to rank graphs by structural properties on inputs substantially larger than those seen during training, with distinct architecture-specific degradation profiles. These findings delineate where fine-tuned small language models generalize reliably, providing empirical grounding for their use in graph-based reasoning tasks.
EdgeWisePersona: A Dataset for On-Device User Profiling from Natural Language Interactions
May 16, 2025This paper introduces a novel dataset and evaluation benchmark designed to assess and improve small language models deployable on edge devices, with a focus on user profiling from multi-session natural language interactions in smart home environments. At the core of the dataset are structured user profiles, each defined by a set of routines - context-triggered, repeatable patterns of behavior that govern how users interact with their home systems. Using these profiles as input, a large language model (LLM) generates corresponding interaction sessions that simulate realistic, diverse, and context-aware dialogues between users and their devices. The primary task supported by this dataset is profile reconstruction: inferring user routines and preferences solely from interactions history. To assess how well current models can perform this task under realistic conditions, we benchmarked several state-of-the-art compact language models and compared their performance against large foundation models. Our results show that while small models demonstrate some capability in reconstructing profiles, they still fall significantly short of large models in accurately capturing user behavior. This performance gap poses a major challenge - particularly because on-device processing offers critical advantages, such as preserving user privacy, minimizing latency, and enabling personalized experiences without reliance on the cloud. By providing a realistic, structured testbed for developing and evaluating behavioral modeling under these constraints, our dataset represents a key step toward enabling intelligent, privacy-respecting AI systems that learn and adapt directly on user-owned devices.
Face Consistency Benchmark for GenAI Video
May 16, 2025


Video generation driven by artificial intelligence has advanced significantly, enabling the creation of dynamic and realistic content. However, maintaining character consistency across video sequences remains a major challenge, with current models struggling to ensure coherence in appearance and attributes. This paper introduces the Face Consistency Benchmark (FCB), a framework for evaluating and comparing the consistency of characters in AI-generated videos. By providing standardized metrics, the benchmark highlights gaps in existing solutions and promotes the development of more reliable approaches. This work represents a crucial step toward improving character consistency in AI video generation technologies.
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Aug 21, 2023



We introduce Graph of Thoughts (GoT): a framework that advances prompting capabilities in large language models (LLMs) beyond those offered by paradigms such as Chain-of-Thought or Tree of Thoughts (ToT). The key idea and primary advantage of GoT is the ability to model the information generated by an LLM as an arbitrary graph, where units of information ("LLM thoughts") are vertices, and edges correspond to dependencies between these vertices. This approach enables combining arbitrary LLM thoughts into synergistic outcomes, distilling the essence of whole networks of thoughts, or enhancing thoughts using feedback loops. We illustrate that GoT offers advantages over state of the art on different tasks, for example increasing the quality of sorting by 62% over ToT, while simultaneously reducing costs by >31%. We ensure that GoT is extensible with new thought transformations and thus can be used to spearhead new prompting schemes. This work brings the LLM reasoning closer to human thinking or brain mechanisms such as recurrence, both of which form complex networks.
Neural Graph Databases
Sep 20, 2022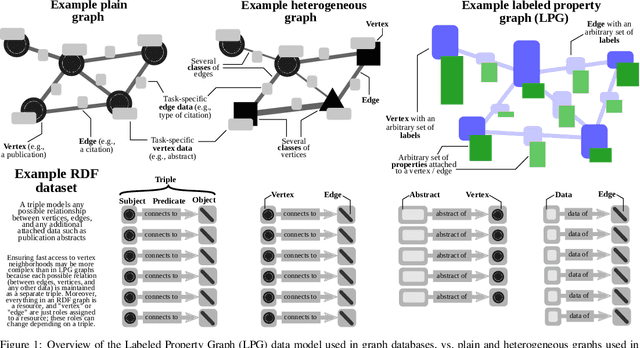

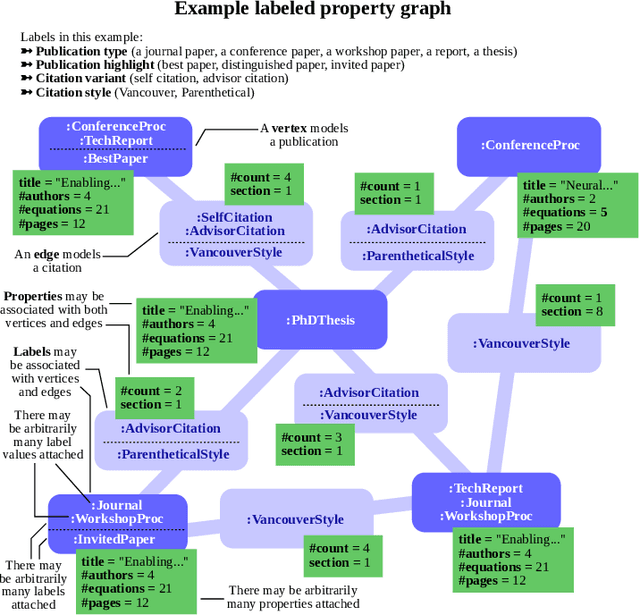
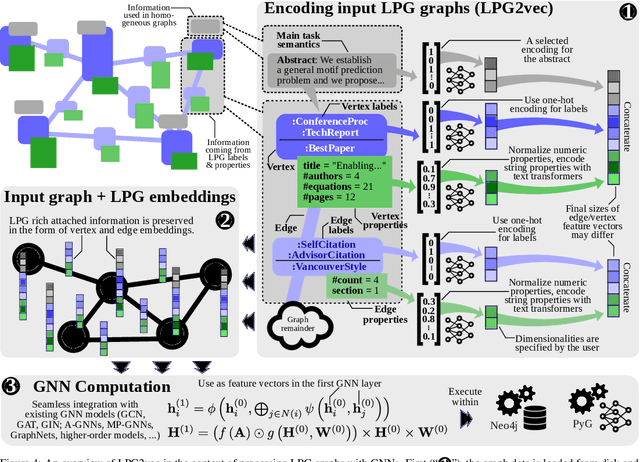
Graph databases (GDBs) enable processing and analysis of unstructured, complex, rich, and usually vast graph datasets. Despite the large significance of GDBs in both academia and industry, little effort has been made into integrating them with the predictive power of graph neural networks (GNNs). In this work, we show how to seamlessly combine nearly any GNN model with the computational capabilities of GDBs. For this, we observe that the majority of these systems are based on, or support, a graph data model called the Labeled Property Graph (LPG), where vertices and edges can have arbitrarily complex sets of labels and properties. We then develop LPG2vec, an encoder that transforms an arbitrary LPG dataset into a representation that can be directly used with a broad class of GNNs, including convolutional, attentional, message-passing, and even higher-order or spectral models. In our evaluation, we show that the rich information represented as LPG labels and properties is properly preserved by LPG2vec, and it increases the accuracy of predictions regardless of the targeted learning task or the used GNN model, by up to 34% compared to graphs with no LPG labels/properties. In general, LPG2vec enables combining predictive power of the most powerful GNNs with the full scope of information encoded in the LPG model, paving the way for neural graph databases, a class of systems where the vast complexity of maintained data will benefit from modern and future graph machine learning methods.