 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbounded Human Learning: Optimal Scheduling for Spaced Repetition
Jun 08, 2016

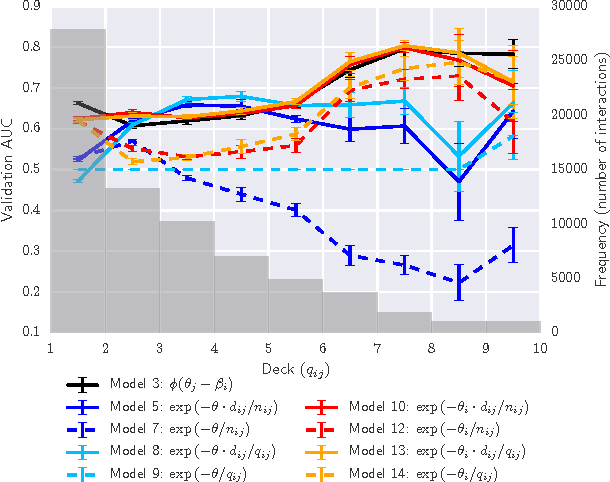
In the study of human learning, there is broad evidence that our ability to retain information improves with repeated exposure and decays with delay since last exposure. This plays a crucial role in the design of educational software, leading to a trade-off between teaching new material and reviewing what has already been taught. A common way to balance this trade-off is spaced repetition, which uses periodic review of content to improve long-term retention. Though spaced repetition is widely used in practice, e.g., in electronic flashcard software, there is little formal understanding of the design of these systems. Our paper addresses this gap in three ways. First, we mine log data from spaced repetition software to establish the functional dependence of retention on reinforcement and delay. Second, we use this memory model to develop a stochastic model for spaced repetition systems. We propose a queueing network model of the Leitner system for reviewing flashcards, along with a heuristic approximation that admits a tractable optimization problem for review scheduling. Finally, we empirically evaluate our queueing model through a Mechanical Turk experiment, verifying a key qualitative prediction of our model: the existence of a sharp phase transition in learning outcomes upon increasing the rate of new item introductions.
Recommendations as Treatments: Debiasing Learning and Evaluation
May 27, 2016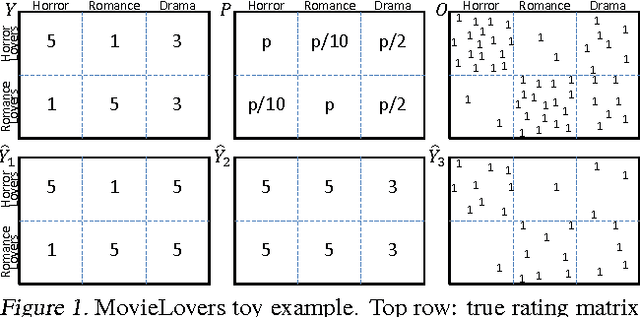
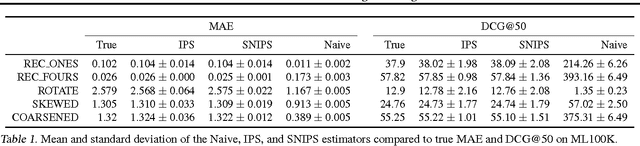
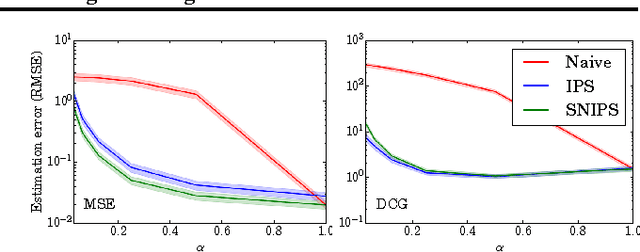
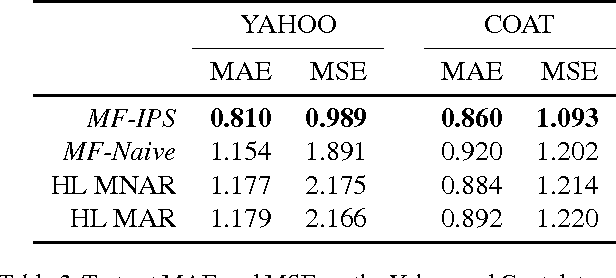
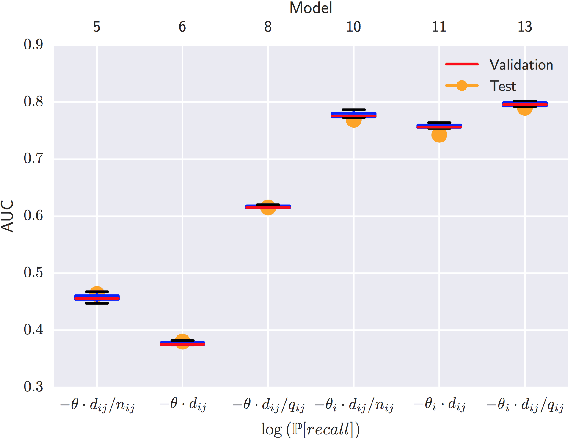
Most data for evaluating and training recommender systems is subject to selection biases, either through self-selection by the users or through the actions of the recommendation system itself. In this paper, we provide a principled approach to handling selection biases, adapting models and estimation techniques from causal inference. The approach leads to unbiased performance estimators despite biased data, and to a matrix factorization method that provides substantially improved prediction performance on real-world data. We theoretically and empirically characterize the robustness of the approach, finding that it is highly practical and scalable.
Unbiased Comparative Evaluation of Ranking Functions
Apr 25, 2016
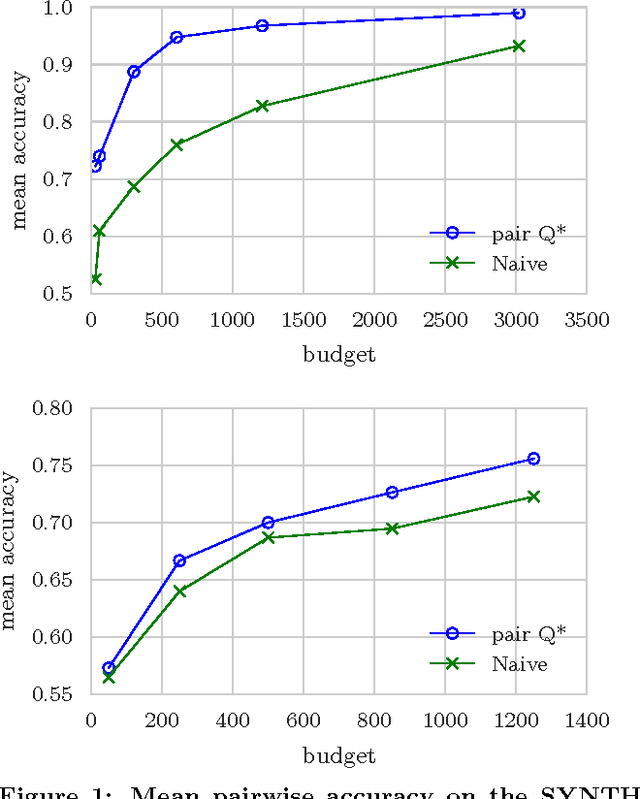
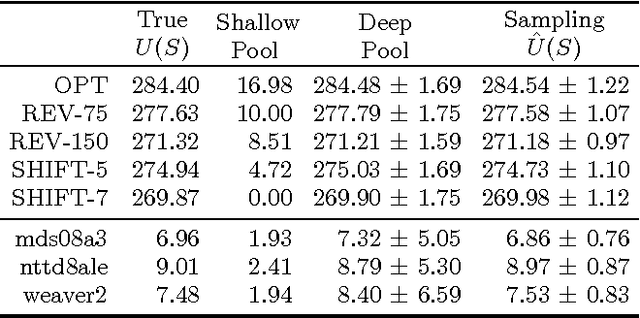
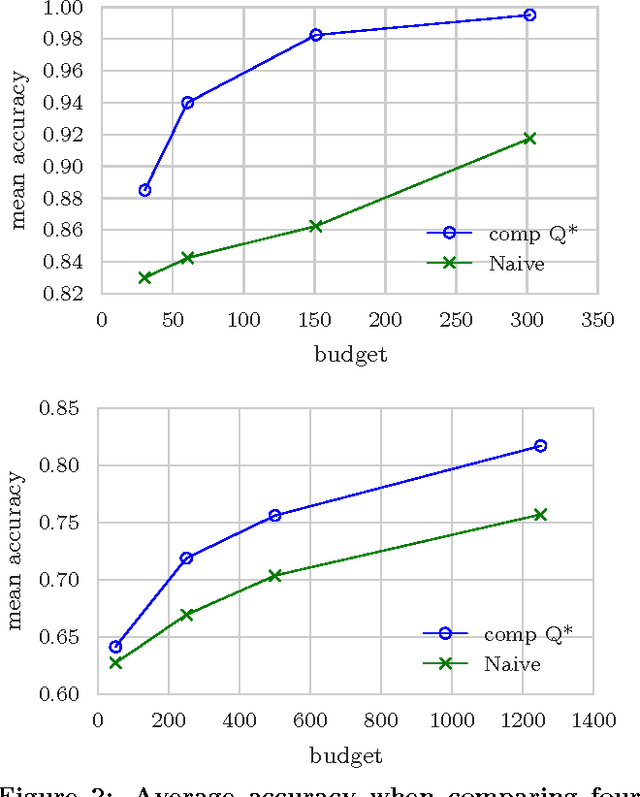
Eliciting relevance judgments for ranking evaluation is labor-intensive and costly, motivating careful selection of which documents to judge. Unlike traditional approaches that make this selection deterministically, probabilistic sampling has shown intriguing promise since it enables the design of estimators that are provably unbiased even when reusing data with missing judgments. In this paper, we first unify and extend these sampling approaches by viewing the evaluation problem as a Monte Carlo estimation task that applies to a large number of common IR metrics. Drawing on the theoretical clarity that this view offers, we tackle three practical evaluation scenarios: comparing two systems, comparing $k$ systems against a baseline, and ranking $k$ systems. For each scenario, we derive an estimator and a variance-optimizing sampling distribution while retaining the strengths of sampling-based evaluation, including unbiasedness, reusability despite missing data, and ease of use in practice. In addition to the theoretical contribution, we empirically evaluate our methods against previously used sampling heuristics and find that they generally cut the number of required relevance judgments at least in half.
Latent Skill Embedding for Personalized Lesson Sequence Recommendation
Feb 23, 2016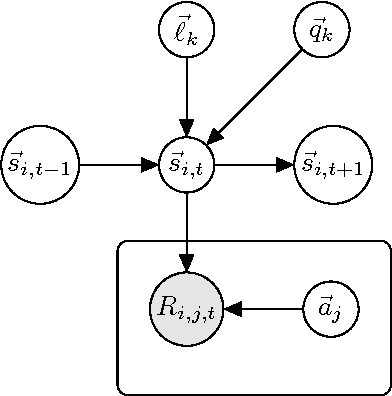
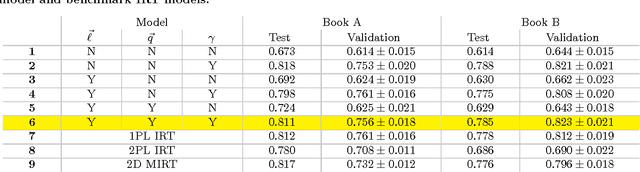
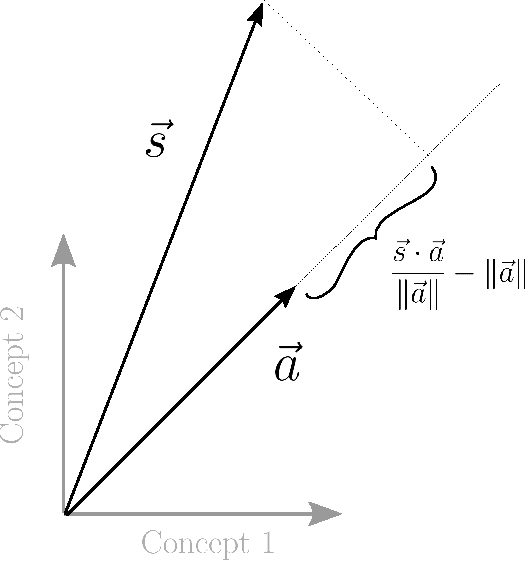
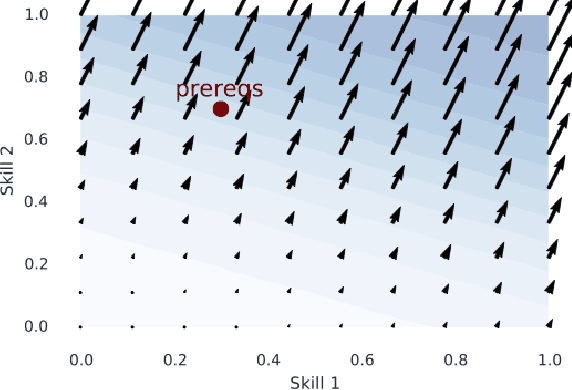
Students in online courses generate large amounts of data that can be used to personalize the learning process and improve quality of education. In this paper, we present the Latent Skill Embedding (LSE), a probabilistic model of students and educational content that can be used to recommend personalized sequences of lessons with the goal of helping students prepare for specific assessments. Akin to collaborative filtering for recommender systems, the algorithm does not require students or content to be described by features, but it learns a representation using access traces. We formulate this problem as a regularized maximum-likelihood embedding of students, lessons, and assessments from historical student-content interactions. An empirical evaluation on large-scale data from Knewton, an adaptive learning technology company, shows that this approach predicts assessment results competitively with benchmark models and is able to discriminate between lesson sequences that lead to mastery and failure.
Using Shortlists to Support Decision Making and Improve Recommender System Performance
Feb 08, 2016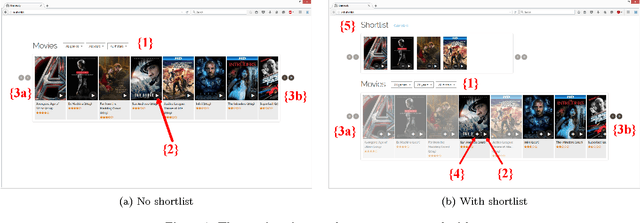

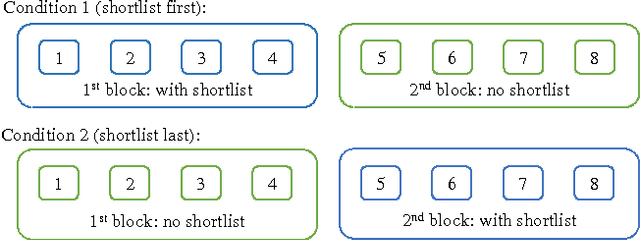
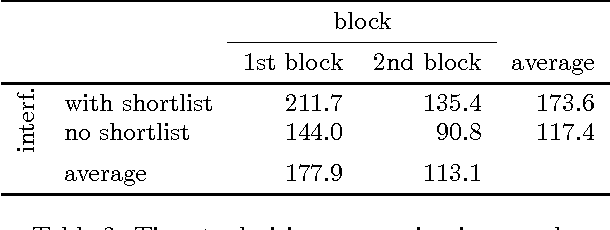
In this paper, we study shortlists as an interface component for recommender systems with the dual goal of supporting the user's decision process, as well as improving implicit feedback elicitation for increased recommendation quality. A shortlist is a temporary list of candidates that the user is currently considering, e.g., a list of a few movies the user is currently considering for viewing. From a cognitive perspective, shortlists serve as digital short-term memory where users can off-load the items under consideration -- thereby decreasing their cognitive load. From a machine learning perspective, adding items to the shortlist generates a new implicit feedback signal as a by-product of exploration and decision making which can improve recommendation quality. Shortlisting therefore provides additional data for training recommendation systems without the increases in cognitive load that requesting explicit feedback would incur. We perform an user study with a movie recommendation setup to compare interfaces that offer shortlist support with those that do not. From the user studies we conclude: (i) users make better decisions with a shortlist; (ii) users prefer an interface with shortlist support; and (iii) the additional implicit feedback from sessions with a shortlist improves the quality of recommendations by nearly a factor of two.
Learning Preferences for Manipulation Tasks from Online Coactive Feedback
Jan 05, 2016
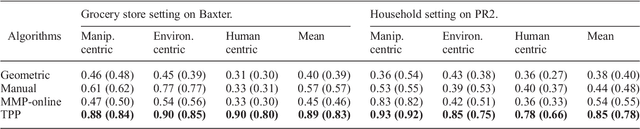

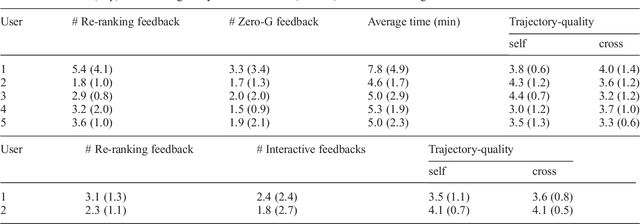
We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than simple geometric constraints on trajectories; they are rather governed by the surrounding context of various objects and human interactions in the environment. We propose a coactive online learning framework for teaching preferences in contextually rich environments. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this coactive preference feedback can be more easily elicited than demonstrations of optimal trajectories. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We implement our algorithm on two high degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings -- household chores and grocery store checkout -- and show that users are able to train the robot with just a few feedbacks (taking only a few minutes).\footnote{Parts of this work has been published at NIPS and ISRR conferences~\citep{Jain13,Jain13b}. This journal submission presents a consistent full paper, and also includes the proof of regret bounds, more details of the robotic system, and a thorough related work.}
Counterfactual Risk Minimization: Learning from Logged Bandit Feedback
May 20, 2015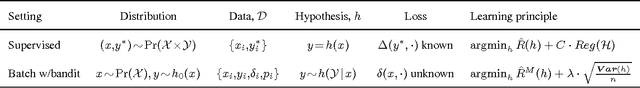
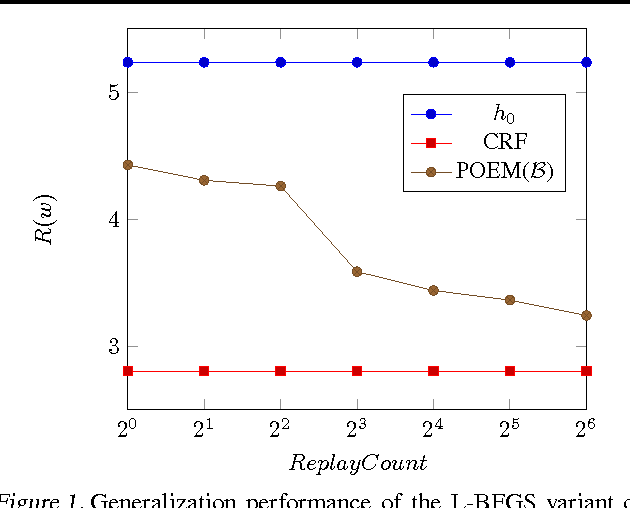
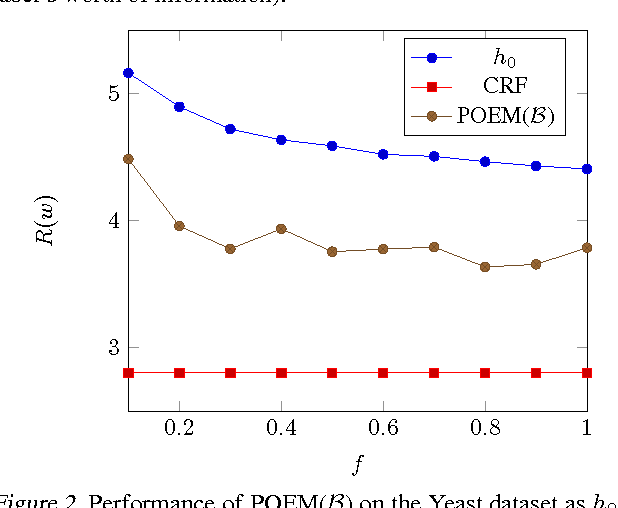
We develop a learning principle and an efficient algorithm for batch learning from logged bandit feedback. This learning setting is ubiquitous in online systems (e.g., ad placement, web search, recommendation), where an algorithm makes a prediction (e.g., ad ranking) for a given input (e.g., query) and observes bandit feedback (e.g., user clicks on presented ads). We first address the counterfactual nature of the learning problem through propensity scoring. Next, we prove generalization error bounds that account for the variance of the propensity-weighted empirical risk estimator. These constructive bounds give rise to the Counterfactual Risk Minimization (CRM) principle. We show how CRM can be used to derive a new learning method -- called Policy Optimizer for Exponential Models (POEM) -- for learning stochastic linear rules for structured output prediction. We present a decomposition of the POEM objective that enables efficient stochastic gradient optimization. POEM is evaluated on several multi-label classification problems showing substantially improved robustness and generalization performance compared to the state-of-the-art.
Reducing Dueling Bandits to Cardinal Bandits
May 14, 2014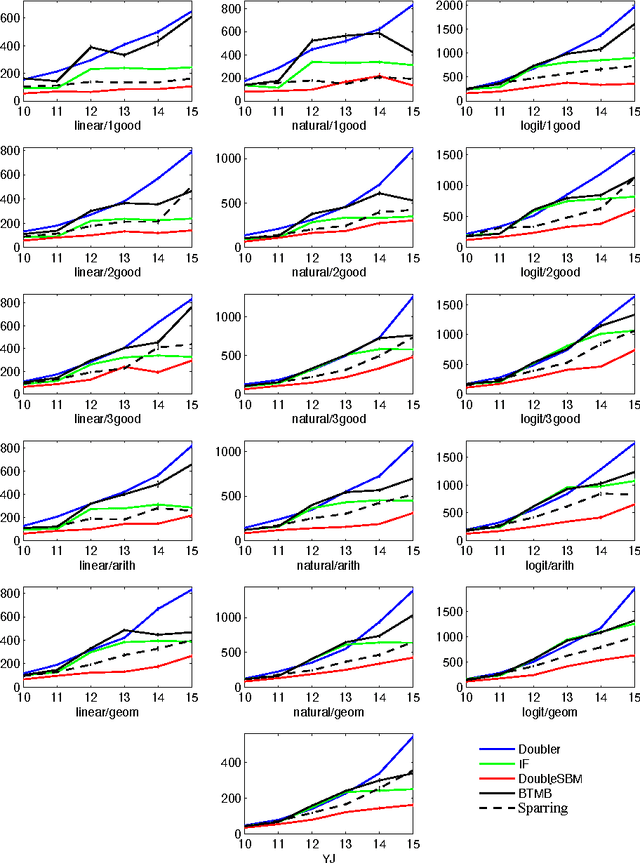
We present algorithms for reducing the Dueling Bandits problem to the conventional (stochastic) Multi-Armed Bandits problem. The Dueling Bandits problem is an online model of learning with ordinal feedback of the form "A is preferred to B" (as opposed to cardinal feedback like "A has value 2.5"), giving it wide applicability in learning from implicit user feedback and revealed and stated preferences. In contrast to existing algorithms for the Dueling Bandits problem, our reductions -- named $\Doubler$, $\MultiSbm$ and $\DoubleSbm$ -- provide a generic schema for translating the extensive body of known results about conventional Multi-Armed Bandit algorithms to the Dueling Bandits setting. For $\Doubler$ and $\MultiSbm$ we prove regret upper bounds in both finite and infinite settings, and conjecture about the performance of $\DoubleSbm$ which empirically outperforms the other two as well as previous algorithms in our experiments. In addition, we provide the first almost optimal regret bound in terms of second order terms, such as the differences between the values of the arms.
Methods for Ordinal Peer Grading
Apr 14, 2014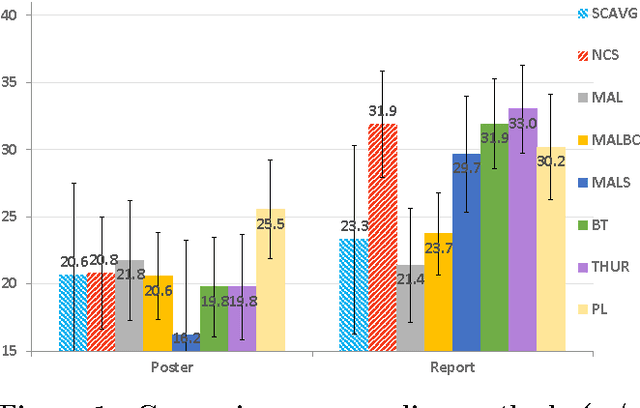
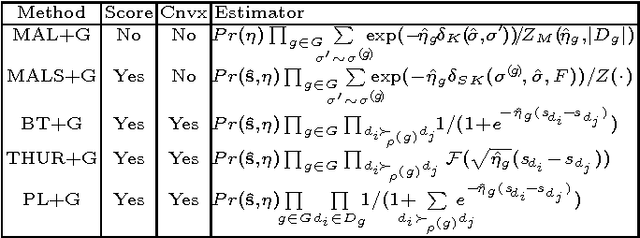
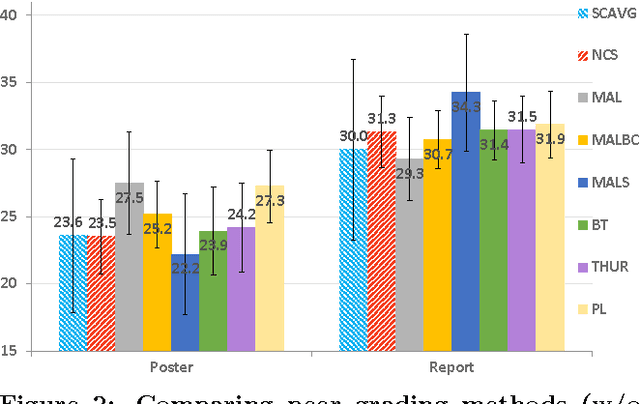
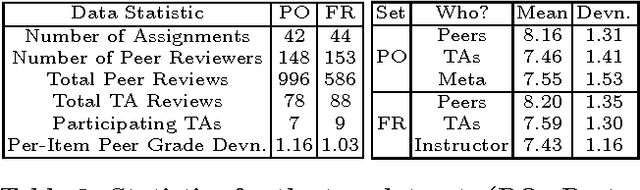
MOOCs have the potential to revolutionize higher education with their wide outreach and accessibility, but they require instructors to come up with scalable alternates to traditional student evaluation. Peer grading -- having students assess each other -- is a promising approach to tackling the problem of evaluation at scale, since the number of "graders" naturally scales with the number of students. However, students are not trained in grading, which means that one cannot expect the same level of grading skills as in traditional settings. Drawing on broad evidence that ordinal feedback is easier to provide and more reliable than cardinal feedback, it is therefore desirable to allow peer graders to make ordinal statements (e.g. "project X is better than project Y") and not require them to make cardinal statements (e.g. "project X is a B-"). Thus, in this paper we study the problem of automatically inferring student grades from ordinal peer feedback, as opposed to existing methods that require cardinal peer feedback. We formulate the ordinal peer grading problem as a type of rank aggregation problem, and explore several probabilistic models under which to estimate student grades and grader reliability. We study the applicability of these methods using peer grading data collected from a real class -- with instructor and TA grades as a baseline -- and demonstrate the efficacy of ordinal feedback techniques in comparison to existing cardinal peer grading methods. Finally, we compare these peer-grading techniques to traditional evaluation techniques.
Learning Trajectory Preferences for Manipulators via Iterative Improvement
Nov 05, 2013
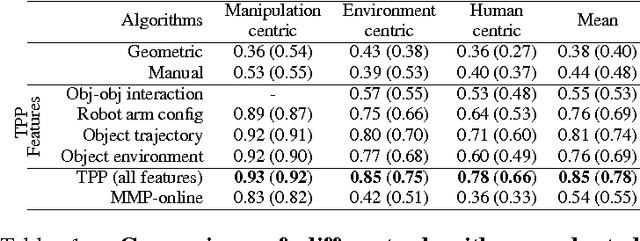
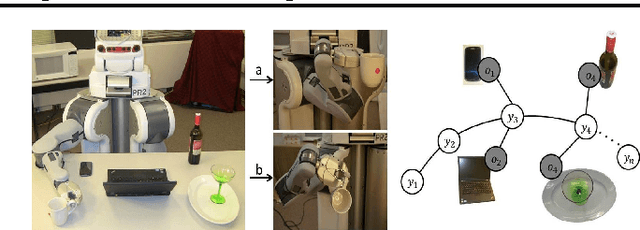
We consider the problem of learning good trajectories for manipulation tasks. This is challenging because the criterion defining a good trajectory varies with users, tasks and environments. In this paper, we propose a co-active online learning framework for teaching robots the preferences of its users for object manipulation tasks. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this co-active preference feedback can be more easily elicited from the user than demonstrations of optimal trajectories, which are often challenging and non-intuitive to provide on high degrees of freedom manipulators. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We demonstrate the generalizability of our algorithm on a variety of grocery checkout tasks, for whom, the preferences were not only influenced by the object being manipulated but also by the surrounding environment.\footnote{For more details and a demonstration video, visit: \url{http://pr.cs.cornell.edu/coactive}}