 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Fairness and Bias in Dynamic Learning-to-Rank
May 29, 2020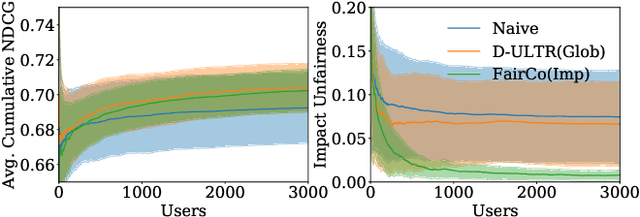
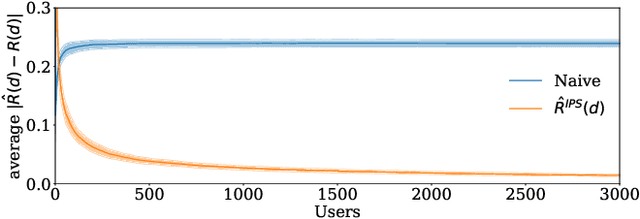
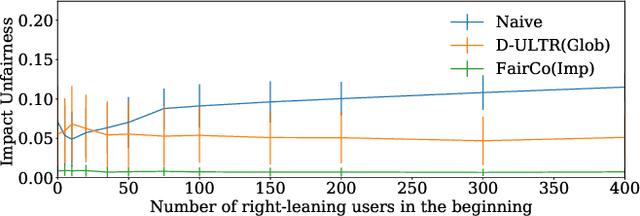
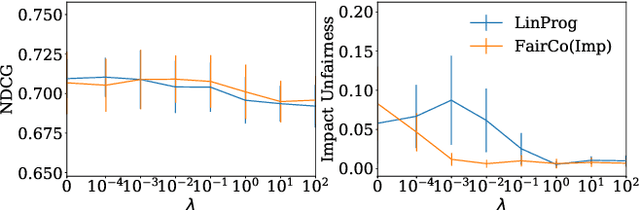
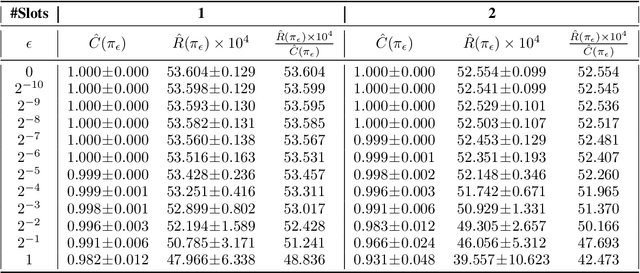
Rankings are the primary interface through which many online platforms match users to items (e.g. news, products, music, video). In these two-sided markets, not only the users draw utility from the rankings, but the rankings also determine the utility (e.g. exposure, revenue) for the item providers (e.g. publishers, sellers, artists, studios). It has already been noted that myopically optimizing utility to the users, as done by virtually all learning-to-rank algorithms, can be unfair to the item providers. We, therefore, present a learning-to-rank approach for explicitly enforcing merit-based fairness guarantees to groups of items (e.g. articles by the same publisher, tracks by the same artist). In particular, we propose a learning algorithm that ensures notions of amortized group fairness, while simultaneously learning the ranking function from implicit feedback data. The algorithm takes the form of a controller that integrates unbiased estimators for both fairness and utility, dynamically adapting both as more data becomes available. In addition to its rigorous theoretical foundation and convergence guarantees, we find empirically that the algorithm is highly practical and robust.
MOReL : Model-Based Offline Reinforcement Learning
May 12, 2020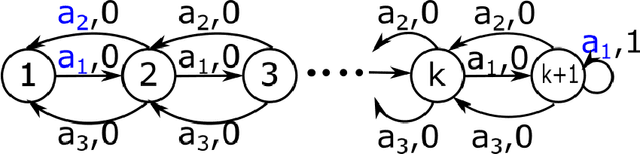
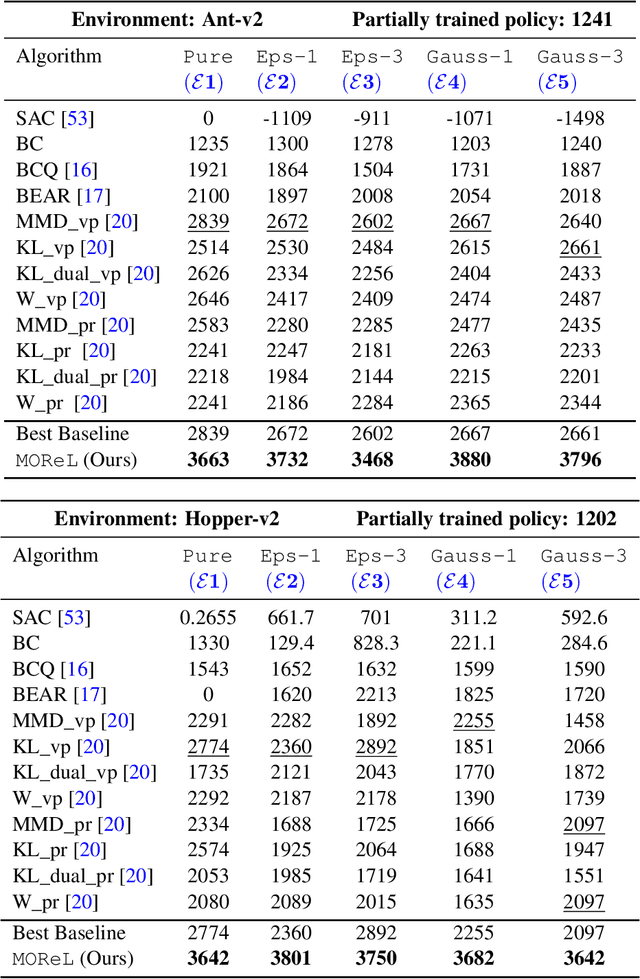
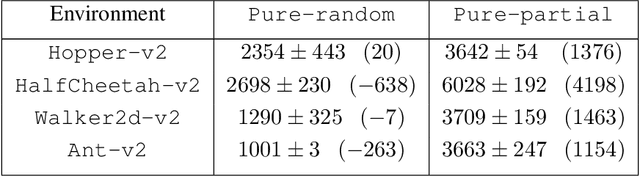
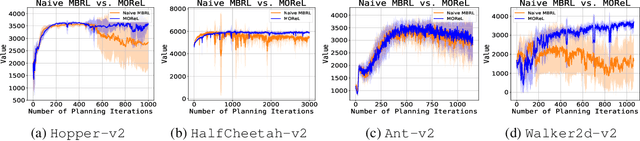
In offline reinforcement learning (RL), the goal is to learn a successful policy using only a dataset of historical interactions with the environment, without any additional online interactions. This serves as an extreme test for an agent's ability to effectively use historical data, which is critical for efficient RL. Prior work in offline RL has been confined almost exclusively to model-free RL approaches. In this work, we present MOReL, an algorithmic framework for model-based RL in the offline setting. This framework consists of two steps: (a) learning a pessimistic MDP model using the offline dataset; (b) learning a near-optimal policy in the learned pessimistic MDP. The construction of the pessimistic MDP is such that for any policy, the performance in the real environment is lower bounded by the performance in the pessimistic MDP. This enables the pessimistic MDP to serve as a good surrogate for the purposes of policy evaluation and learning. Overall, MOReL is amenable to detailed theoretical analysis, enables easy and transparent design of practical algorithms, and leads to state-of-the-art results on widely studied offline RL benchmark tasks.
Fair Learning-to-Rank from Implicit Feedback
Nov 19, 2019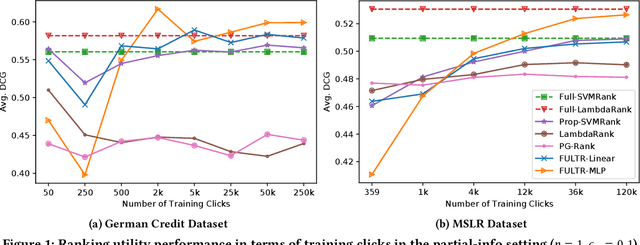
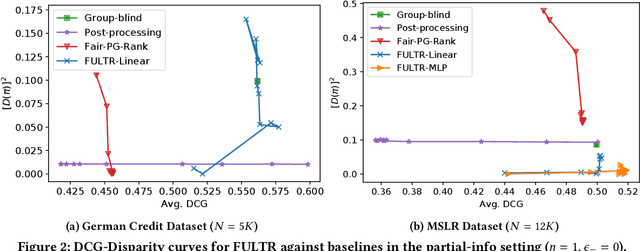
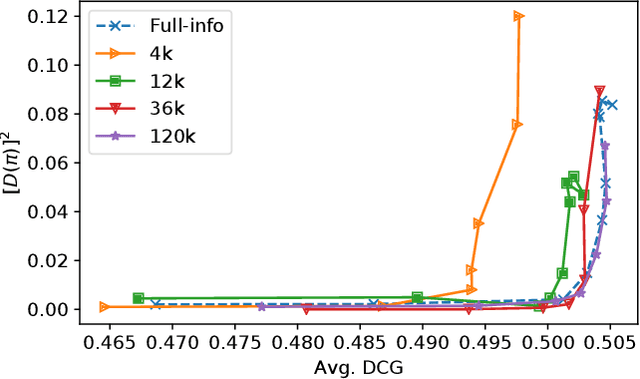
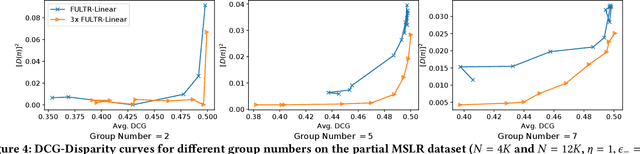
Addressing unfairness in rankings has become an increasingly important problem due to the growing influence of rankings in critical decision making, yet existing learning-to-rank algorithms suffer from multiple drawbacks when learning fair ranking policies from implicit feedback. Some algorithms suffer from extrinsic reasons of unfairness due to inherent selection biases in implicit feedback leading to rich-get-richer dynamics. While those that address the biased nature of implicit feedback suffer from intrinsic reasons of unfairness due to the lack of explicit control over the allocation of exposure based on merit (i.e, relevance). In both cases, the learned ranking policy can be unfair and lead to suboptimal results. To this end, we propose a novel learning-to-rank framework, FULTR, that is the first to address both intrinsic and extrinsic reasons of unfairness when learning ranking policies from logged implicit feedback. Considering the needs of various applications, we define a class of amortized fairness of exposure constraints with respect to items based on their merit, and propose corresponding counterfactual estimators of disparity (aka unfairness) and utility that are also robust to click noise. Furthermore, we provide an efficient algorithm that optimizes both utility and fairness via a policy-gradient approach. To show that our proposed algorithm learns accurate and fair ranking policies from biased and noisy feedback, we provide empirical results beyond the theoretical justification of the framework.
Policy Learning for Fairness in Ranking
Feb 11, 2019
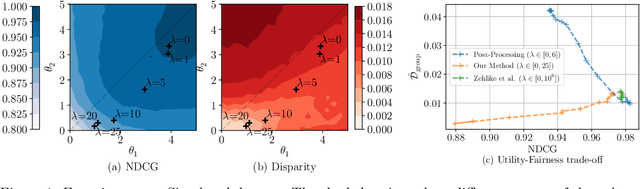
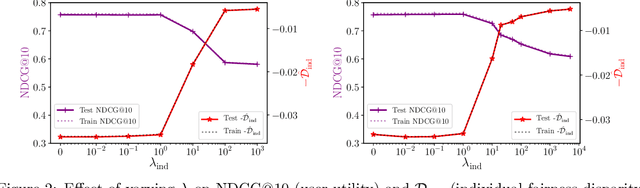

Conventional Learning-to-Rank (LTR) methods optimize the utility of the rankings to the users, but they are oblivious to their impact on the ranked items. However, there has been a growing understanding that the latter is important to consider for a wide range of ranking applications (e.g. online marketplaces, job placement, admissions). To address this need, we propose a general LTR framework that can optimize a wide range of utility metrics (e.g. NDCG) while satisfying fairness of exposure constraints with respect to the items. This framework expands the class of learnable ranking functions to stochastic ranking policies, which provides a language for rigorously expressing fairness specifications. Furthermore, we provide a new LTR algorithm called Fair-PG-Rank for directly searching the space of fair ranking policies via a policy-gradient approach. Beyond the theoretical evidence in deriving the framework and the algorithm, we provide empirical results on simulated and real-world datasets verifying the effectiveness of the approach in individual and group-fairness settings.
CAB: Continuous Adaptive Blending Estimator for Policy Evaluation and Learning
Nov 19, 2018


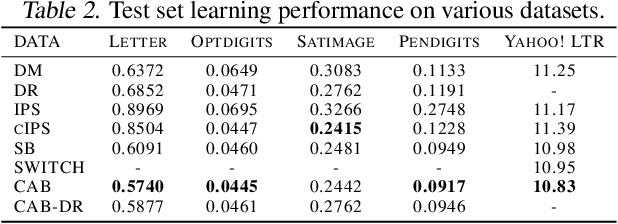
The ability to perform offline A/B-testing and off-policy learning using logged contextual bandit feedback is highly desirable in a broad range of applications, including recommender systems, search engines, ad placement, and personalized health care. Both offline A/B-testing and off-policy learning require a counterfactual estimator that evaluates how some new policy would have performed, if it had been used instead of the logging policy. This paper proposes a new counterfactual estimator - called Continuous Adaptive Blending (CAB) - for this policy evaluation problem that combines regression and weighting approaches for an effective bias/variance trade-off. It can be substantially less biased than clipped Inverse Propensity Score weighting and the Direct Method, and it can have less variance compared with Doubly Robust and IPS estimators. Experimental results show that CAB provides excellent and reliable estimation accuracy compared to other blended estimators, and - unlike the SWITCH estimator - is sub-differentiable such that it can be used for learning.
Counterfactual Learning-to-Rank for Additive Metrics and Deep Models
Jun 22, 2018
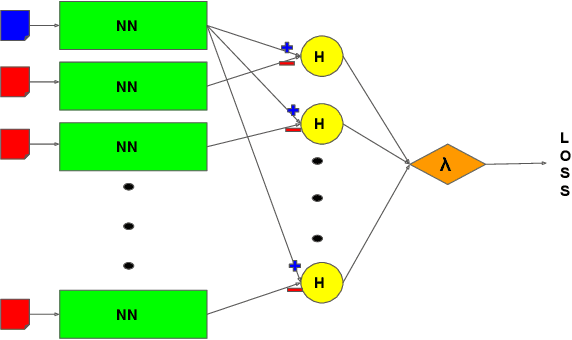

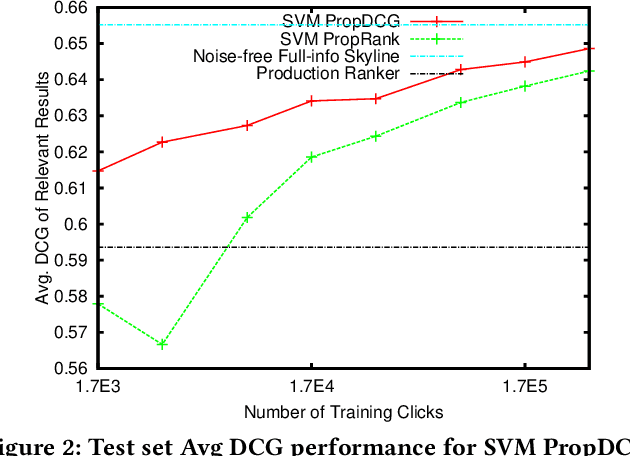
Implicit feedback (e.g., clicks, dwell times) is an attractive source of training data for Learning-to-Rank, but it inevitably suffers from biases such as position bias. It was recently shown how counterfactual inference techniques can provide a rigorous approach for handling these biases, but existing methods are restricted to the special case of optimizing average rank for linear ranking functions. In this work, we generalize the counterfactual learning-to-rank approach to a broad class of additive rank metrics -- like Discounted Cumulative Gain (DCG) and Precision@k -- as well as non-linear deep network models. Focusing on DCG, this conceptual generalization gives rise to two new learning methods that both directly optimize an unbiased estimate of DCG despite the bias in the implicit feedback data. The first, SVM PropDCG, generalizes the Propensity Ranking SVM (SVM PropRank), and we show how the resulting optimization problem can be addressed via the Convex Concave Procedure (CCP). The second, Deep PropDCG, further generalizes the counterfactual learning-to-rank approach to deep networks as non-linear ranking functions. In addition to the theoretical support, we empirically find that SVM PropDCG significantly outperforms SVM PropRank in terms of DCG, and that it is robust to varying severity of presentation bias, noise, and propensity-model misspecification. Moreover, the ability to train non-linear ranking functions via Deep PropDCG further improves DCG.
Consistent Position Bias Estimation without Online Interventions for Learning-to-Rank
Jun 09, 2018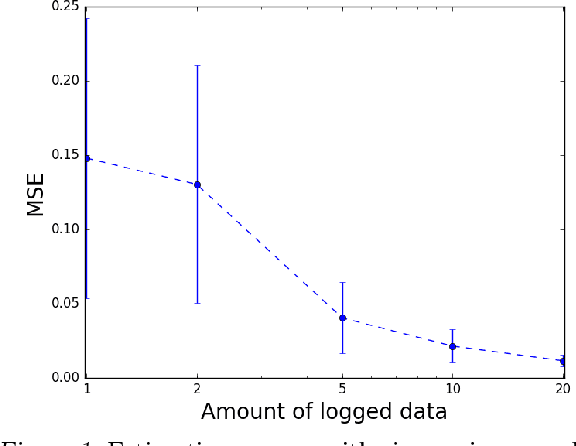
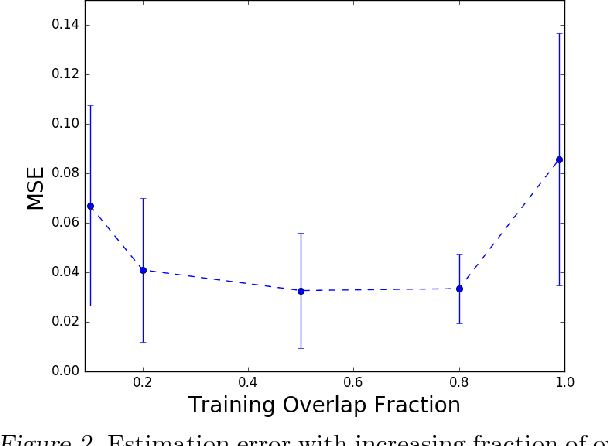
Presentation bias is one of the key challenges when learning from implicit feedback in search engines, as it confounds the relevance signal with uninformative signals due to position in the ranking, saliency, and other presentation factors. While it was recently shown how counterfactual learning-to-rank (LTR) approaches \cite{Joachims/etal/17a} can provably overcome presentation bias if observation propensities are known, it remains to show how to accurately estimate these propensities. In this paper, we propose the first method for producing consistent propensity estimates without manual relevance judgments, disruptive interventions, or restrictive relevance modeling assumptions. We merely require that we have implicit feedback data from multiple different ranking functions. Furthermore, we argue that our estimation technique applies to an extended class of Contextual Position-Based Propensity Models, where propensities not only depend on position but also on observable features of the query and document. Initial simulation studies confirm that the approach is scalable, accurate, and robust.
Effective Evaluation using Logged Bandit Feedback from Multiple Loggers
Jun 26, 2017
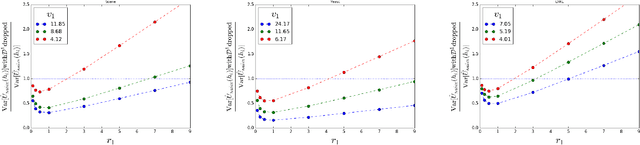
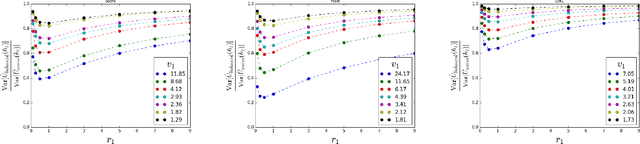
Accurately evaluating new policies (e.g. ad-placement models, ranking functions, recommendation functions) is one of the key prerequisites for improving interactive systems. While the conventional approach to evaluation relies on online A/B tests, recent work has shown that counterfactual estimators can provide an inexpensive and fast alternative, since they can be applied offline using log data that was collected from a different policy fielded in the past. In this paper, we address the question of how to estimate the performance of a new target policy when we have log data from multiple historic policies. This question is of great relevance in practice, since policies get updated frequently in most online systems. We show that naively combining data from multiple logging policies can be highly suboptimal. In particular, we find that the standard Inverse Propensity Score (IPS) estimator suffers especially when logging and target policies diverge -- to a point where throwing away data improves the variance of the estimator. We therefore propose two alternative estimators which we characterize theoretically and compare experimentally. We find that the new estimators can provide substantially improved estimation accuracy.
Large-scale Validation of Counterfactual Learning Methods: A Test-Bed
Jun 25, 2017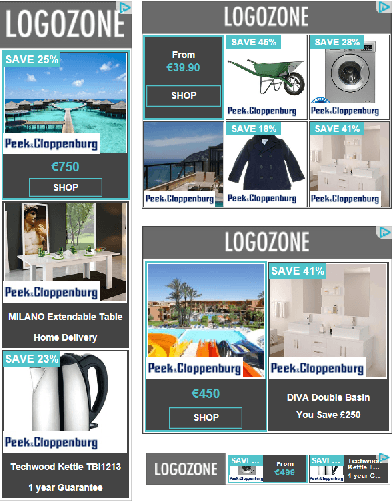

The ability to perform effective off-policy learning would revolutionize the process of building better interactive systems, such as search engines and recommendation systems for e-commerce, computational advertising and news. Recent approaches for off-policy evaluation and learning in these settings appear promising. With this paper, we provide real-world data and a standardized test-bed to systematically investigate these algorithms using data from display advertising. In particular, we consider the problem of filling a banner ad with an aggregate of multiple products the user may want to purchase. This paper presents our test-bed, the sanity checks we ran to ensure its validity, and shows results comparing state-of-the-art off-policy learning methods like doubly robust optimization, POEM, and reductions to supervised learning using regression baselines. Our results show experimental evidence that recent off-policy learning methods can improve upon state-of-the-art supervised learning techniques on a large-scale real-world data set.
Unbiased Learning-to-Rank with Biased Feedback
Aug 16, 2016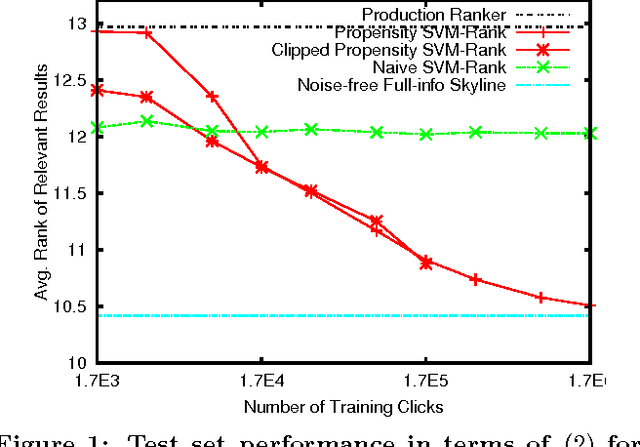
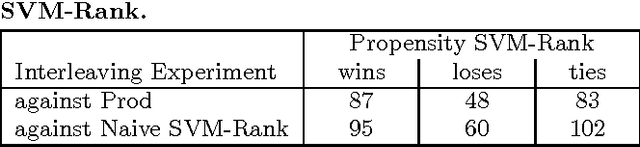
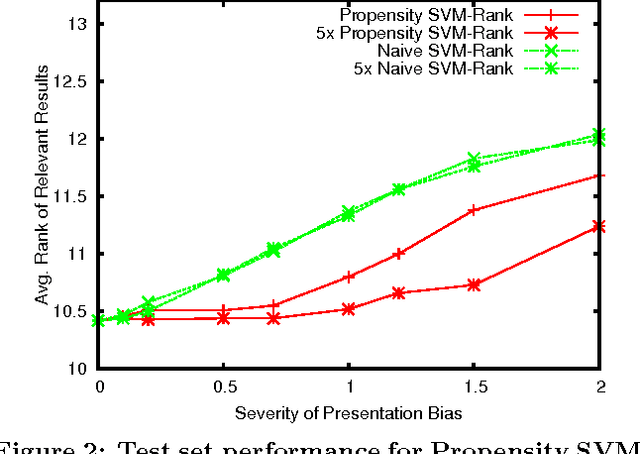
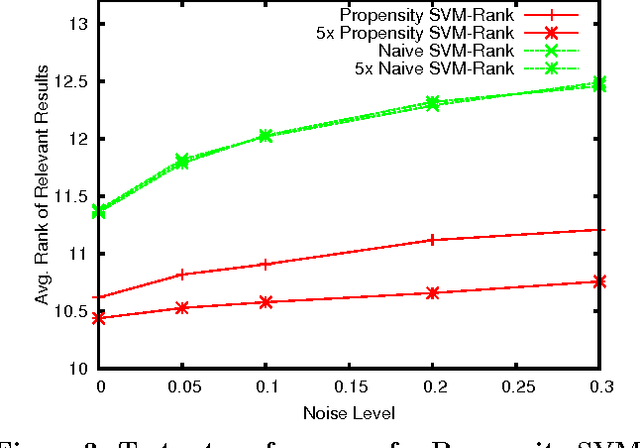
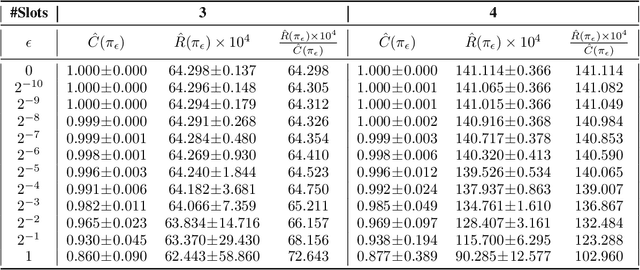
Implicit feedback (e.g., clicks, dwell times, etc.) is an abundant source of data in human-interactive systems. While implicit feedback has many advantages (e.g., it is inexpensive to collect, user centric, and timely), its inherent biases are a key obstacle to its effective use. For example, position bias in search rankings strongly influences how many clicks a result receives, so that directly using click data as a training signal in Learning-to-Rank (LTR) methods yields sub-optimal results. To overcome this bias problem, we present a counterfactual inference framework that provides the theoretical basis for unbiased LTR via Empirical Risk Minimization despite biased data. Using this framework, we derive a Propensity-Weighted Ranking SVM for discriminative learning from implicit feedback, where click models take the role of the propensity estimator. In contrast to most conventional approaches to de-bias the data using click models, this allows training of ranking functions even in settings where queries do not repeat. Beyond the theoretical support, we show empirically that the proposed learning method is highly effective in dealing with biases, that it is robust to noise and propensity model misspecification, and that it scales efficiently. We also demonstrate the real-world applicability of our approach on an operational search engine, where it substantially improves retrieval performance.