 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Learning-to-Rank from Implicit Feedback
Nov 19, 2019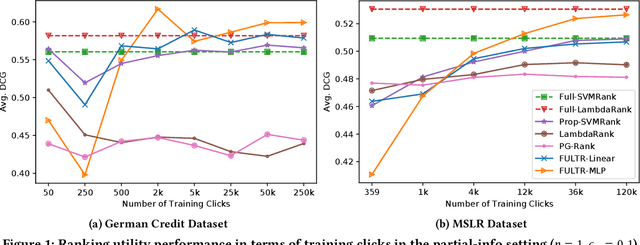
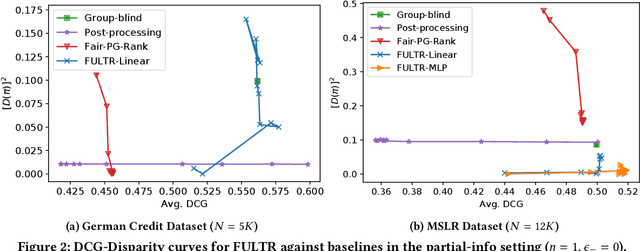
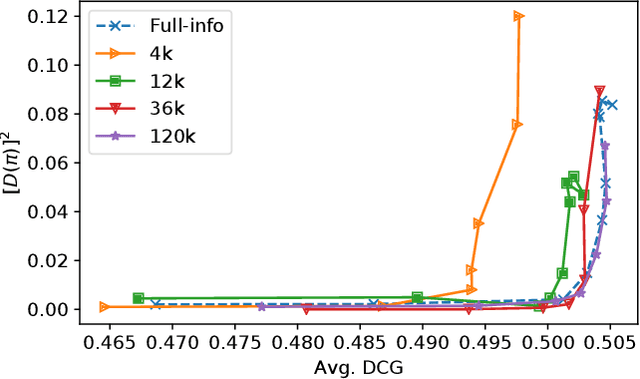
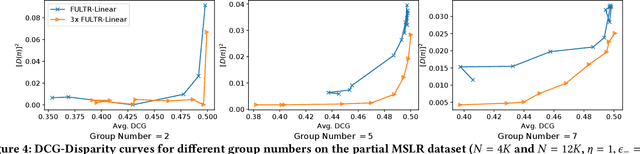
Addressing unfairness in rankings has become an increasingly important problem due to the growing influence of rankings in critical decision making, yet existing learning-to-rank algorithms suffer from multiple drawbacks when learning fair ranking policies from implicit feedback. Some algorithms suffer from extrinsic reasons of unfairness due to inherent selection biases in implicit feedback leading to rich-get-richer dynamics. While those that address the biased nature of implicit feedback suffer from intrinsic reasons of unfairness due to the lack of explicit control over the allocation of exposure based on merit (i.e, relevance). In both cases, the learned ranking policy can be unfair and lead to suboptimal results. To this end, we propose a novel learning-to-rank framework, FULTR, that is the first to address both intrinsic and extrinsic reasons of unfairness when learning ranking policies from logged implicit feedback. Considering the needs of various applications, we define a class of amortized fairness of exposure constraints with respect to items based on their merit, and propose corresponding counterfactual estimators of disparity (aka unfairness) and utility that are also robust to click noise. Furthermore, we provide an efficient algorithm that optimizes both utility and fairness via a policy-gradient approach. To show that our proposed algorithm learns accurate and fair ranking policies from biased and noisy feedback, we provide empirical results beyond the theoretical justification of the framework.
Social Media Writing Style Fingerprint
Dec 26, 2017We present our approach for computer-aided social media text authorship attribution based on recent advances in short text authorship verification. We use various natural language techniques to create word-level and character-level models that act as hidden layers to simulate a simple neural network. The choice of word-level and character-level models in each layer was informed through validation performance. The output layer of our system uses an unweighted majority vote vector to arrive at a conclusion. We also considered writing bias in social media posts while collecting our training dataset to increase system robustness. Our system achieved a precision, recall, and F-measure of 0.82, 0.926 and 0.869 respectively.