 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking a Pulse on How Generative AI is Reshaping the Software Engineering Research Landscape
Apr 13, 2026Context: Software engineering (SE) researchers increasingly study Generative AI (GenAI) while also incorporating it into their own research practices. Despite rapid adoption, there is limited empirical evidence on how GenAI is used in SE research and its implications for research practices and governance. Aims: We conduct a large-scale survey of 457 SE researchers publishing in top venues between 2023 and 2025. Method: Using quantitative and qualitative analyses, we examine who uses GenAI and why, where it is used across research activities, and how researchers perceive its benefits, opportunities, challenges, risks, and governance. Results: GenAI use is widespread, with many researchers reporting pressure to adopt and align their work with it. Usage is concentrated in writing and early-stage activities, while methodological and analytical tasks remain largely human-driven. Although productivity gains are widely perceived, concerns about trust, correctness, and regulatory uncertainty persist. Researchers highlight risks such as inaccuracies and bias, emphasize mitigation through human oversight and verification, and call for clearer governance, including guidance on responsible use and peer review. Conclusion: We provide a fine-grained, SE-specific characterization of GenAI use across research activities, along with taxonomies of GenAI use cases for research and peer review, opportunities, risks, mitigation strategies, and governance needs. These findings establish an empirical baseline for the responsible integration of GenAI into academic practice.
Time Warp: The Gap Between Developers' Ideal vs Actual Workweeks in an AI-Driven Era
Feb 21, 2025



Software developers balance a variety of different tasks in a workweek, yet the allocation of time often differs from what they consider ideal. Identifying and addressing these deviations is crucial for organizations aiming to enhance the productivity and well-being of the developers. In this paper, we present the findings from a survey of 484 software developers at Microsoft, which aims to identify the key differences between how developers would like to allocate their time during an ideal workweek versus their actual workweek. Our analysis reveals significant deviations between a developer's ideal workweek and their actual workweek, with a clear correlation: as the gap between these two workweeks widens, we observe a decline in both productivity and satisfaction. By examining these deviations in specific activities, we assess their direct impact on the developers' satisfaction and productivity. Additionally, given the growing adoption of AI tools in software engineering, both in the industry and academia, we identify specific tasks and areas that could be strong candidates for automation. In this paper, we make three key contributions: 1) We quantify the impact of workweek deviations on developer productivity and satisfaction 2) We identify individual tasks that disproportionately affect satisfaction and productivity 3) We provide actual data-driven insights to guide future AI automation efforts in software engineering, aligning them with the developers' requirements and ideal workflows for maximizing their productivity and satisfaction.
Beyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products
Oct 15, 2024
Large Language Models (LLMs) are increasingly embedded into software products across diverse industries, enhancing user experiences, but at the same time introducing numerous challenges for developers. Unique characteristics of LLMs force developers, who are accustomed to traditional software development and evaluation, out of their comfort zones as the LLM components shatter standard assumptions about software systems. This study explores the emerging solutions that software developers are adopting to navigate the encountered challenges. Leveraging a mixed-method research, including 26 interviews and a survey with 332 responses, the study identifies 19 emerging solutions regarding quality assurance that practitioners across several product teams at Microsoft are exploring. The findings provide valuable insights that can guide the development and evaluation of LLM-based products more broadly in the face of these challenges.
GEMS: Generative Expert Metric System through Iterative Prompt Priming
Oct 01, 2024



Across domains, metrics and measurements are fundamental to identifying challenges, informing decisions, and resolving conflicts. Despite the abundance of data available in this information age, not only can it be challenging for a single expert to work across multi-disciplinary data, but non-experts can also find it unintuitive to create effective measures or transform theories into context-specific metrics that are chosen appropriately. This technical report addresses this challenge by examining software communities within large software corporations, where different measures are used as proxies to locate counterparts within the organization to transfer tacit knowledge. We propose a prompt-engineering framework inspired by neural activities, demonstrating that generative models can extract and summarize theories and perform basic reasoning, thereby transforming concepts into context-aware metrics to support software communities given software repository data. While this research zoomed in on software communities, we believe the framework's applicability extends across various fields, showcasing expert-theory-inspired metrics that aid in triaging complex challenges.
Can GPT-4 Replicate Empirical Software Engineering Research?
Oct 03, 2023



Empirical software engineering research on production systems has brought forth a better understanding of the software engineering process for practitioners and researchers alike. However, only a small subset of production systems is studied, limiting the impact of this research. While software engineering practitioners benefit from replicating research on their own data, this poses its own set of challenges, since performing replications requires a deep understanding of research methodologies and subtle nuances in software engineering data. Given that large language models (LLMs), such as GPT-4, show promise in tackling both software engineering- and science-related tasks, these models could help democratize empirical software engineering research. In this paper, we examine LLMs' abilities to perform replications of empirical software engineering research on new data. We specifically study their ability to surface assumptions made in empirical software engineering research methodologies, as well as their ability to plan and generate code for analysis pipelines on seven empirical software engineering papers. We perform a user study with 14 participants with software engineering research expertise, who evaluate GPT-4-generated assumptions and analysis plans (i.e., a list of module specifications) from the papers. We find that GPT-4 is able to surface correct assumptions, but struggle to generate ones that reflect common knowledge about software engineering data. In a manual analysis of the generated code, we find that the GPT-4-generated code contains the correct high-level logic, given a subset of the methodology. However, the code contains many small implementation-level errors, reflecting a lack of software engineering knowledge. Our findings have implications for leveraging LLMs for software engineering research as well as practitioner data scientists in software teams.
Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models
Jan 10, 2023



Incident management for cloud services is a complex process involving several steps and has a huge impact on both service health and developer productivity. On-call engineers require significant amount of domain knowledge and manual effort for root causing and mitigation of production incidents. Recent advances in artificial intelligence has resulted in state-of-the-art large language models like GPT-3.x (both GPT-3.0 and GPT-3.5), which have been used to solve a variety of problems ranging from question answering to text summarization. In this work, we do the first large-scale study to evaluate the effectiveness of these models for helping engineers root cause and mitigate production incidents. We do a rigorous study at Microsoft, on more than 40,000 incidents and compare several large language models in zero-shot, fine-tuned and multi-task setting using semantic and lexical metrics. Lastly, our human evaluation with actual incident owners show the efficacy and future potential of using artificial intelligence for resolving cloud incidents.
Neural Knowledge Extraction From Cloud Service Incidents
Jul 15, 2020
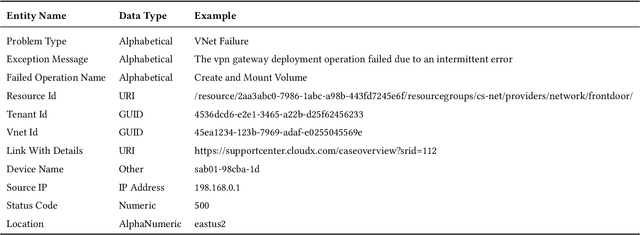

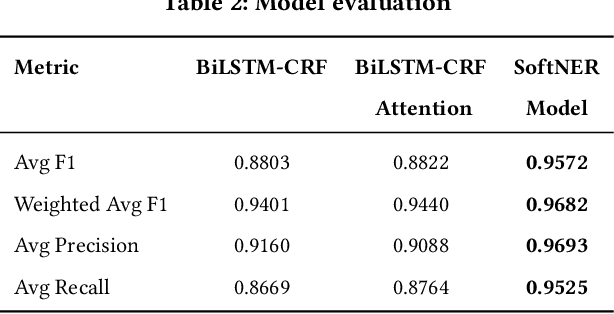
In the last decade, two paradigm shifts have reshaped the software industry - the move from boxed products to services and the widespread adoption of cloud computing. This has had a huge impact on the software development life cycle and the DevOps processes. Particularly, incident management has become critical for developing and operating large-scale services. Incidents are created to ensure timely communication of service issues and, also, their resolution. Prior work on incident management has been heavily focused on the challenges with incident triaging and de-duplication. In this work, we address the fundamental problem of structured knowledge extraction from service incidents. We have built SoftNER, a framework for unsupervised knowledge extraction from service incidents. We frame the knowledge extraction problem as a Named-entity Recognition task for extracting factual information. SoftNER leverages structural patterns like key,value pairs and tables for bootstrapping the training data. Further, we build a novel multi-task learning based BiLSTM-CRF model which leverages not just the semantic context but also the data-types for named-entity extraction. We have deployed SoftNER at Microsoft, a major cloud service provider and have evaluated it on more than 2 months of cloud incidents. We show that the unsupervised machine learning based approach has a high precision of 0.96. Our multi-task learning based deep learning model also outperforms the state of the art NER models. Lastly, using the knowledge extracted by SoftNER we are able to build significantly more accurate models for important downstream tasks like incident triaging.