 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking a Pulse on How Generative AI is Reshaping the Software Engineering Research Landscape
Apr 13, 2026Context: Software engineering (SE) researchers increasingly study Generative AI (GenAI) while also incorporating it into their own research practices. Despite rapid adoption, there is limited empirical evidence on how GenAI is used in SE research and its implications for research practices and governance. Aims: We conduct a large-scale survey of 457 SE researchers publishing in top venues between 2023 and 2025. Method: Using quantitative and qualitative analyses, we examine who uses GenAI and why, where it is used across research activities, and how researchers perceive its benefits, opportunities, challenges, risks, and governance. Results: GenAI use is widespread, with many researchers reporting pressure to adopt and align their work with it. Usage is concentrated in writing and early-stage activities, while methodological and analytical tasks remain largely human-driven. Although productivity gains are widely perceived, concerns about trust, correctness, and regulatory uncertainty persist. Researchers highlight risks such as inaccuracies and bias, emphasize mitigation through human oversight and verification, and call for clearer governance, including guidance on responsible use and peer review. Conclusion: We provide a fine-grained, SE-specific characterization of GenAI use across research activities, along with taxonomies of GenAI use cases for research and peer review, opportunities, risks, mitigation strategies, and governance needs. These findings establish an empirical baseline for the responsible integration of GenAI into academic practice.
Get on the Train or be Left on the Station: Using LLMs for Software Engineering Research
Jun 15, 2025The adoption of Large Language Models (LLMs) is not only transforming software engineering (SE) practice but is also poised to fundamentally disrupt how research is conducted in the field. While perspectives on this transformation range from viewing LLMs as mere productivity tools to considering them revolutionary forces, we argue that the SE research community must proactively engage with and shape the integration of LLMs into research practices, emphasizing human agency in this transformation. As LLMs rapidly become integral to SE research - both as tools that support investigations and as subjects of study - a human-centric perspective is essential. Ensuring human oversight and interpretability is necessary for upholding scientific rigor, fostering ethical responsibility, and driving advancements in the field. Drawing from discussions at the 2nd Copenhagen Symposium on Human-Centered AI in SE, this position paper employs McLuhan's Tetrad of Media Laws to analyze the impact of LLMs on SE research. Through this theoretical lens, we examine how LLMs enhance research capabilities through accelerated ideation and automated processes, make some traditional research practices obsolete, retrieve valuable aspects of historical research approaches, and risk reversal effects when taken to extremes. Our analysis reveals opportunities for innovation and potential pitfalls that require careful consideration. We conclude with a call to action for the SE research community to proactively harness the benefits of LLMs while developing frameworks and guidelines to mitigate their risks, to ensure continued rigor and impact of research in an AI-augmented future.
Tag that issue: Applying API-domain labels in issue tracking systems
Apr 06, 2023Labeling issues with the skills required to complete them can help contributors to choose tasks in Open Source Software projects. However, manually labeling issues is time-consuming and error-prone, and current automated approaches are mostly limited to classifying issues as bugs/non-bugs. We investigate the feasibility and relevance of automatically labeling issues with what we call "API-domains," which are high-level categories of APIs. Therefore, we posit that the APIs used in the source code affected by an issue can be a proxy for the type of skills (e.g., DB, security, UI) needed to work on the issue. We ran a user study (n=74) to assess API-domain labels' relevancy to potential contributors, leveraged the issues' descriptions and the project history to build prediction models, and validated the predictions with contributors (n=20) of the projects. Our results show that (i) newcomers to the project consider API-domain labels useful in choosing tasks, (ii) labels can be predicted with a precision of 84% and a recall of 78.6% on average, (iii) the results of the predictions reached up to 71.3% in precision and 52.5% in recall when training with a project and testing in another (transfer learning), and (iv) project contributors consider most of the predictions helpful in identifying needed skills. These findings suggest our approach can be applied in practice to automatically label issues, assisting developers in finding tasks that better match their skills.
Can I Solve It? Identifying APIs Required to Complete OSS Task
Mar 23, 2021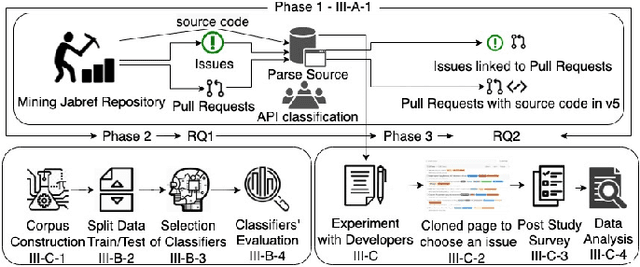
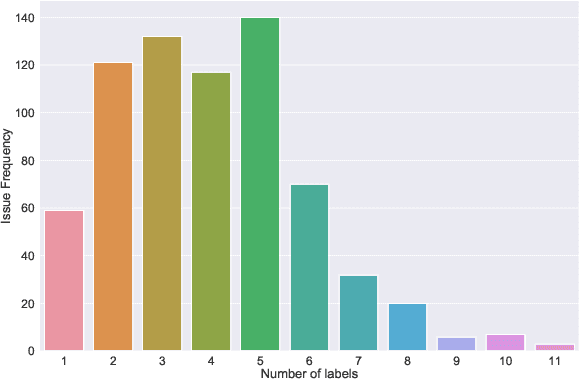
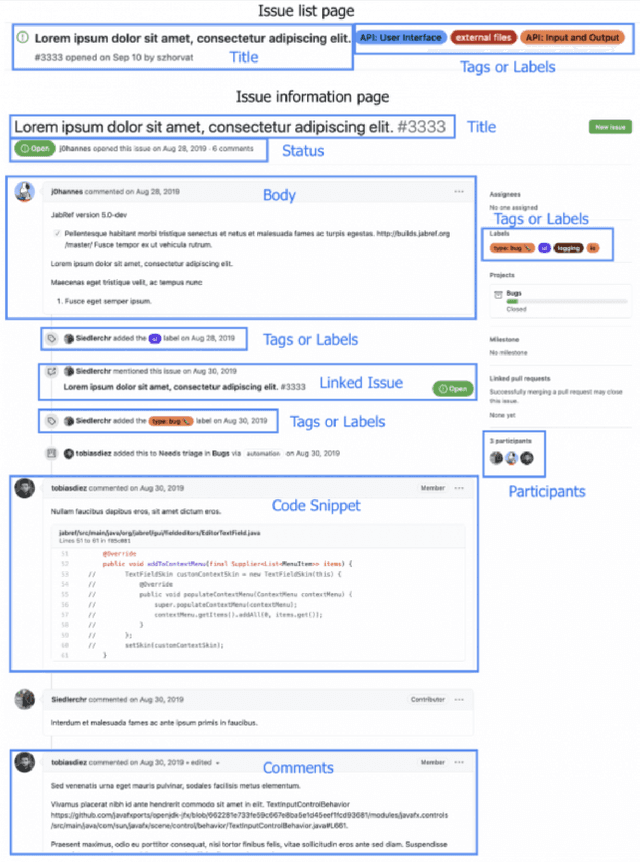
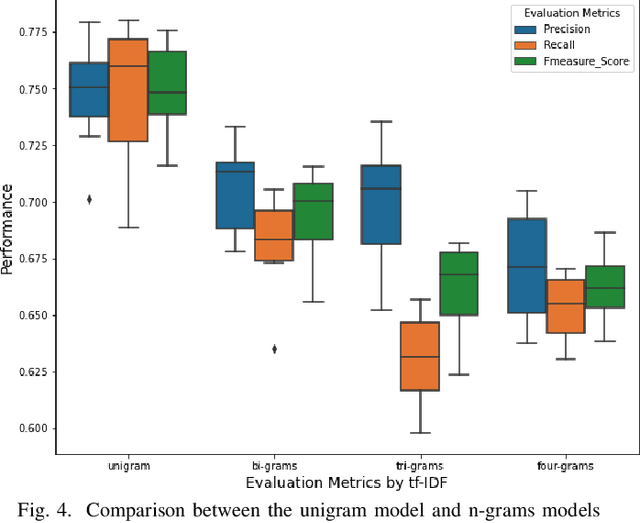
Open Source Software projects add labels to open issues to help contributors choose tasks. However, manually labeling issues is time-consuming and error-prone. Current automatic approaches for creating labels are mostly limited to classifying issues as a bug/non-bug. In this paper, we investigate the feasibility and relevance of labeling issues with the domain of the APIs required to complete the tasks. We leverage the issues' description and the project history to build prediction models, which resulted in precision up to 82% and recall up to 97.8%. We also ran a user study (n=74) to assess these labels' relevancy to potential contributors. The results show that the labels were useful to participants in choosing tasks, and the API-domain labels were selected more often than the existing architecture-based labels. Our results can inspire the creation of tools to automatically label issues, helping developers to find tasks that better match their skills.