 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrative Experiments Identify How Punishment Impacts Welfare in Public Goods Games
Aug 23, 2025Punishment as a mechanism for promoting cooperation has been studied extensively for more than two decades, but its effectiveness remains a matter of dispute. Here, we examine how punishment's impact varies across cooperative settings through a large-scale integrative experiment. We vary 14 parameters that characterize public goods games, sampling 360 experimental conditions and collecting 147,618 decisions from 7,100 participants. Our results reveal striking heterogeneity in punishment effectiveness: while punishment consistently increases contributions, its impact on payoffs (i.e., efficiency) ranges from dramatically enhancing welfare (up to 43% improvement) to severely undermining it (up to 44% reduction) depending on the cooperative context. To characterize these patterns, we developed models that outperformed human forecasters (laypeople and domain experts) in predicting punishment outcomes in new experiments. Communication emerged as the most predictive feature, followed by contribution framing (opt-out vs. opt-in), contribution type (variable vs. all-or-nothing), game length (number of rounds), peer outcome visibility (whether participants can see others' earnings), and the availability of a reward mechanism. Interestingly, however, most of these features interact to influence punishment effectiveness rather than operating independently. For example, the extent to which longer games increase the effectiveness of punishment depends on whether groups can communicate. Together, our results refocus the debate over punishment from whether or not it "works" to the specific conditions under which it does and does not work. More broadly, our study demonstrates how integrative experiments can be combined with machine learning to uncover generalizable patterns, potentially involving interactions between multiple features, and help generate novel explanations in complex social phenomena.
When Are Combinations of Humans and AI Useful?
May 09, 2024Inspired by the increasing use of AI to augment humans, researchers have studied human-AI systems involving different tasks, systems, and populations. Despite such a large body of work, we lack a broad conceptual understanding of when combinations of humans and AI are better than either alone. Here, we addressed this question by conducting a meta-analysis of over 100 recent experimental studies reporting over 300 effect sizes. First, we found that, on average, human-AI combinations performed significantly worse than the best of humans or AI alone. Second, we found performance losses in tasks that involved making decisions and significantly greater gains in tasks that involved creating content. Finally, when humans outperformed AI alone, we found performance gains in the combination, but when the AI outperformed humans alone we found losses. These findings highlight the heterogeneity of the effects of human-AI collaboration and point to promising avenues for improving human-AI systems.
A Test for Evaluating Performance in Human-Computer Systems
Jun 28, 2022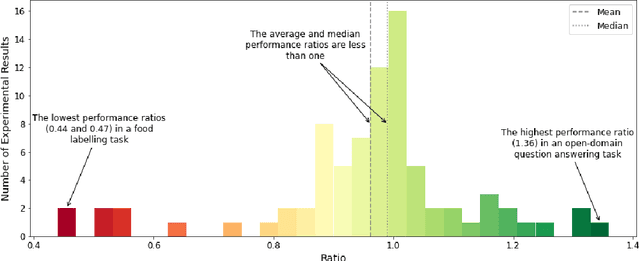

The Turing test for comparing computer performance to that of humans is well known, but, surprisingly, there is no widely used test for comparing how much better human-computer systems perform relative to humans alone, computers alone, or other baselines. Here, we show how to perform such a test using the ratio of means as a measure of effect size. Then we demonstrate the use of this test in three ways. First, in an analysis of 79 recently published experimental results, we find that, surprisingly, over half of the studies find a decrease in performance, the mean and median ratios of performance improvement are both approximately 1 (corresponding to no improvement at all), and the maximum ratio is 1.36 (a 36% improvement). Second, we experimentally investigate whether a higher performance improvement ratio is obtained when 100 human programmers generate software using GPT-3, a massive, state-of-the-art AI system. In this case, we find a speed improvement ratio of 1.27 (a 27% improvement). Finally, we find that 50 human non-programmers using GPT-3 can perform the task about as well as--and less expensively than--the human programmers. In this case, neither the non-programmers nor the computer would have been able to perform the task alone, so this is an example of a very strong form of human-computer synergy.
Will We Trust What We Don't Understand? Impact of Model Interpretability and Outcome Feedback on Trust in AI
Nov 16, 2021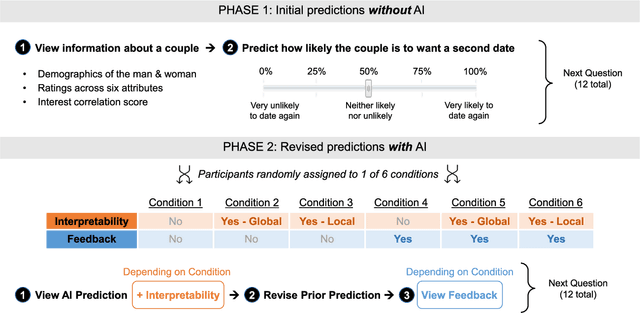
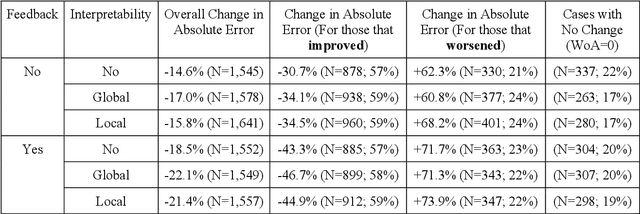
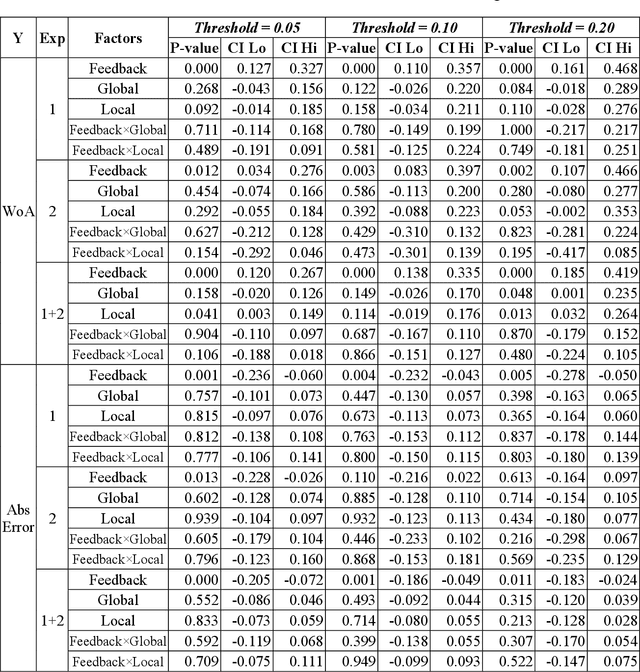
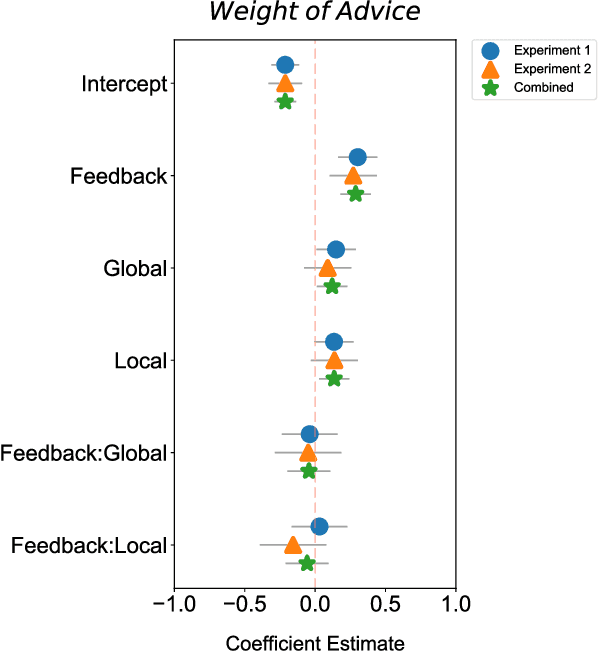
Despite AI's superhuman performance in a variety of domains, humans are often unwilling to adopt AI systems. The lack of interpretability inherent in many modern AI techniques is believed to be hurting their adoption, as users may not trust systems whose decision processes they do not understand. We investigate this proposition with a novel experiment in which we use an interactive prediction task to analyze the impact of interpretability and outcome feedback on trust in AI and on human performance in AI-assisted prediction tasks. We find that interpretability led to no robust improvements in trust, while outcome feedback had a significantly greater and more reliable effect. However, both factors had modest effects on participants' task performance. Our findings suggest that (1) factors receiving significant attention, such as interpretability, may be less effective at increasing trust than factors like outcome feedback, and (2) augmenting human performance via AI systems may not be a simple matter of increasing trust in AI, as increased trust is not always associated with equally sizable improvements in performance. These findings invite the research community to focus not only on methods for generating interpretations but also on techniques for ensuring that interpretations impact trust and performance in practice.