 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn pseudo-absence generation and machine learning for locust breeding ground prediction in Africa
Nov 06, 2021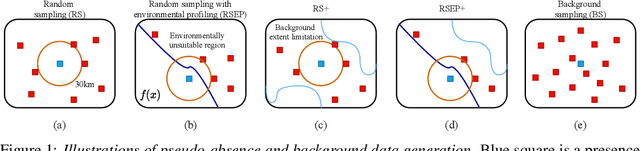
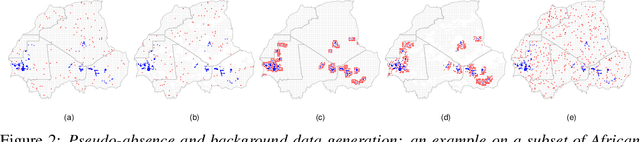

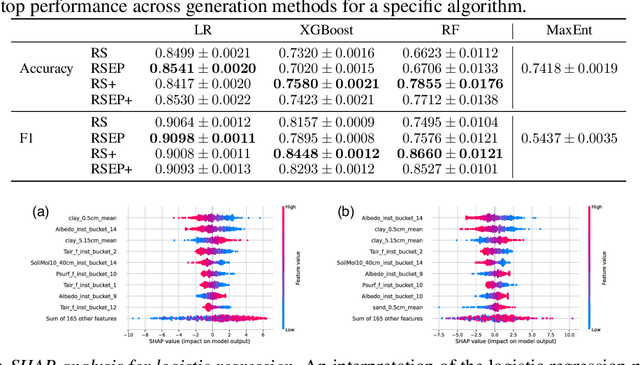
Desert locust outbreaks threaten the food security of a large part of Africa and have affected the livelihoods of millions of people over the years. Machine learning (ML) has been demonstrated as an effective approach to locust distribution modelling which could assist in early warning. ML requires a significant amount of labelled data to train. Most publicly available labelled data on locusts are presence-only data, where only the sightings of locusts being present at a location are recorded. Therefore, prior work using ML have resorted to pseudo-absence generation methods as a way to circumvent this issue. The most commonly used approach is to randomly sample points in a region of interest while ensuring that these sampled pseudo-absence points are at least a specific distance away from true presence points. In this paper, we compare this random sampling approach to more advanced pseudo-absence generation methods, such as environmental profiling and optimal background extent limitation, specifically for predicting desert locust breeding grounds in Africa. Interestingly, we find that for the algorithms we tested, namely logistic regression, gradient boosting, random forests and maximum entropy, all popular in prior work, the logistic model performed significantly better than the more sophisticated ensemble methods, both in terms of prediction accuracy and F1 score. Although background extent limitation combined with random sampling boosted performance for ensemble methods, for LR this was not the case, and instead, a significant improvement was obtained when using environmental profiling. In light of this, we conclude that a simpler ML approach such as logistic regression combined with more advanced pseudo-absence generation, specifically environmental profiling, can be a sensible and effective approach to predicting locust breeding grounds across Africa.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
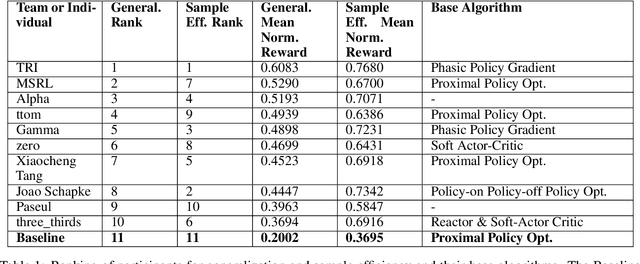
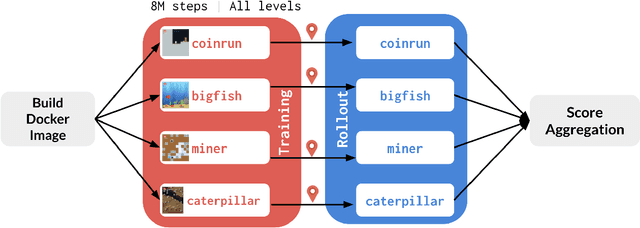
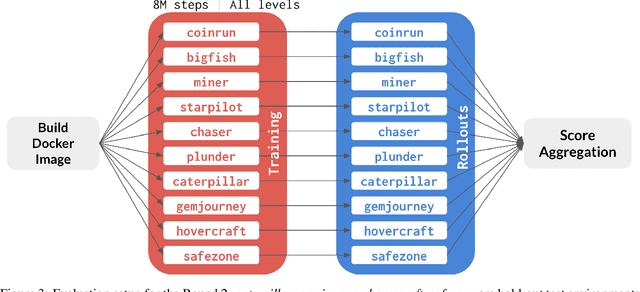
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.