 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Uncertainty Estimation of Learned Variational MRI Reconstruction
Feb 12, 2021
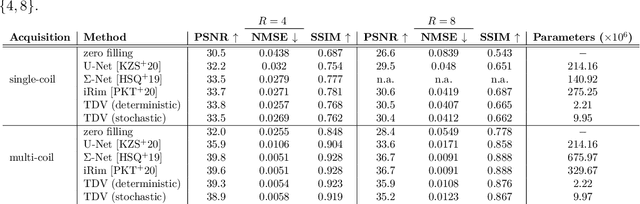
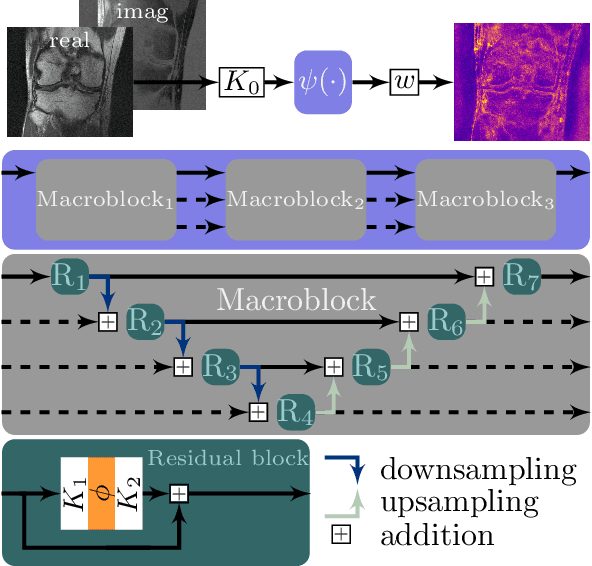
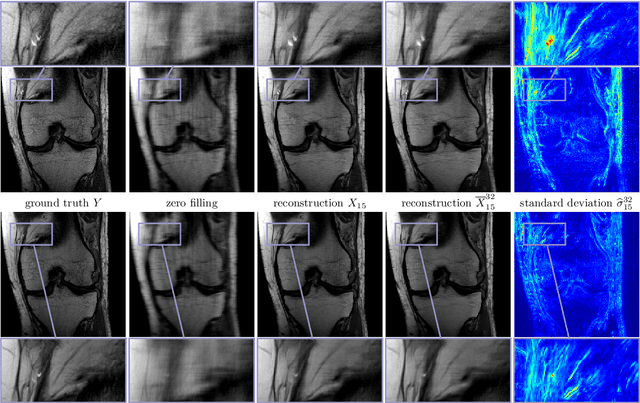
Recent deep learning approaches focus on improving quantitative scores of dedicated benchmarks, and therefore only reduce the observation-related (aleatoric) uncertainty. However, the model-immanent (epistemic) uncertainty is less frequently systematically analyzed. In this work, we introduce a Bayesian variational framework to quantify the epistemic uncertainty. To this end, we solve the linear inverse problem of undersampled MRI reconstruction in a variational setting. The associated energy functional is composed of a data fidelity term and the total deep variation (TDV) as a learned parametric regularizer. To estimate the epistemic uncertainty we draw the parameters of the TDV regularizer from a multivariate Gaussian distribution, whose mean and covariance matrix are learned in a stochastic optimal control problem. In several numerical experiments, we demonstrate that our approach yields competitive results for undersampled MRI reconstruction. Moreover, we can accurately quantify the pixelwise epistemic uncertainty, which can serve radiologists as an additional resource to visualize reconstruction reliability.
Shared Prior Learning of Energy-Based Models for Image Reconstruction
Nov 13, 2020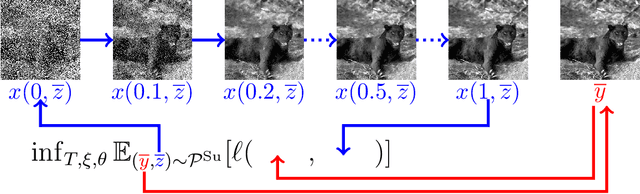
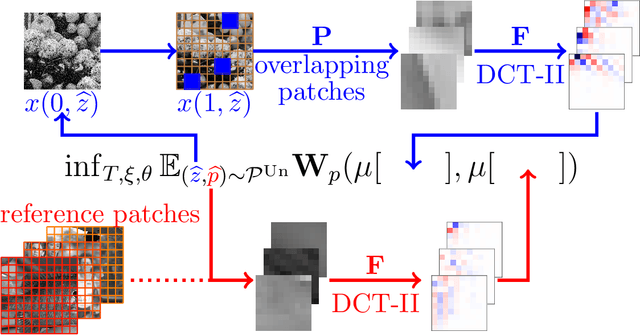
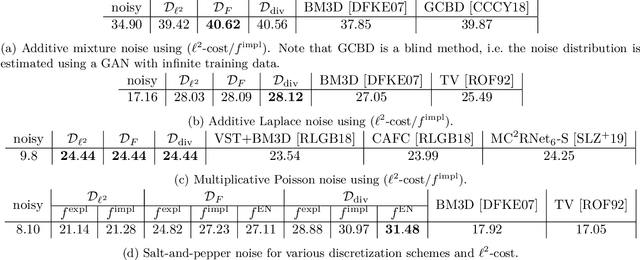
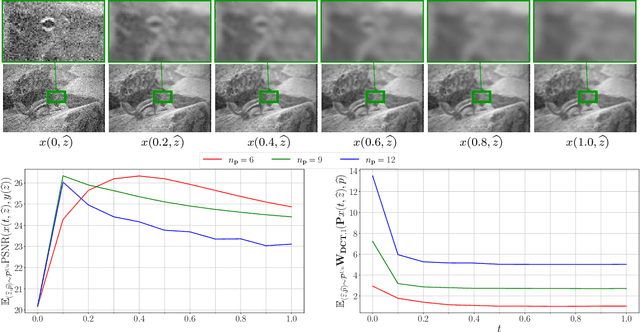
We propose a novel learning-based framework for image reconstruction particularly designed for training without ground truth data, which has three major building blocks: energy-based learning, a patch-based Wasserstein loss functional, and shared prior learning. In energy-based learning, the parameters of an energy functional composed of a learned data fidelity term and a data-driven regularizer are computed in a mean-field optimal control problem. In the absence of ground truth data, we change the loss functional to a patch-based Wasserstein functional, in which local statistics of the output images are compared to uncorrupted reference patches. Finally, in shared prior learning, both aforementioned optimal control problems are optimized simultaneously with shared learned parameters of the regularizer to further enhance unsupervised image reconstruction. We derive several time discretization schemes of the gradient flow and verify their consistency in terms of Mosco convergence. In numerous numerical experiments, we demonstrate that the proposed method generates state-of-the-art results for various image reconstruction applications--even if no ground truth images are available for training.
BP-MVSNet: Belief-Propagation-Layers for Multi-View-Stereo
Oct 23, 2020
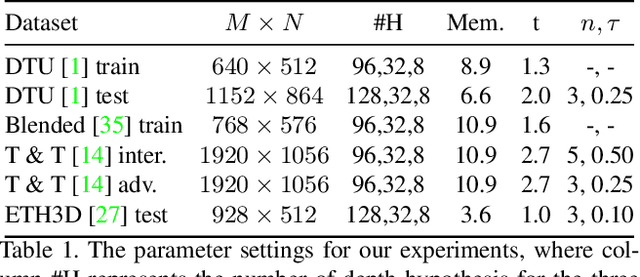
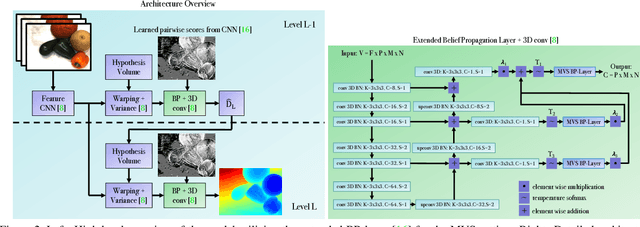
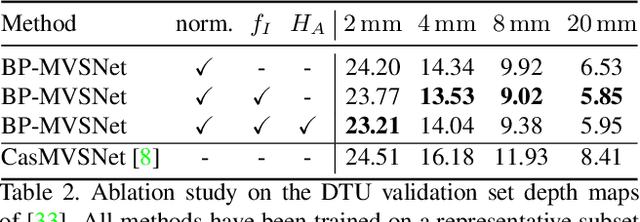
In this work, we propose BP-MVSNet, a convolutional neural network (CNN)-based Multi-View-Stereo (MVS) method that uses a differentiable Conditional Random Field (CRF) layer for regularization. To this end, we propose to extend the BP layer and add what is necessary to successfully use it in the MVS setting. We therefore show how we can calculate a normalization based on the expected 3D error, which we can then use to normalize the label jumps in the CRF. This is required to make the BP layer invariant to different scales in the MVS setting. In order to also enable fractional label jumps, we propose a differentiable interpolation step, which we embed into the computation of the pairwise term. These extensions allow us to integrate the BP layer into a multi-scale MVS network, where we continuously improve a rough initial estimate until we get high quality depth maps as a result. We evaluate the proposed BP-MVSNet in an ablation study and conduct extensive experiments on the DTU, Tanks and Temples and ETH3D data sets. The experiments show that we can significantly outperform the baseline and achieve state-of-the-art results.
Total Deep Variation: A Stable Regularizer for Inverse Problems
Jun 15, 2020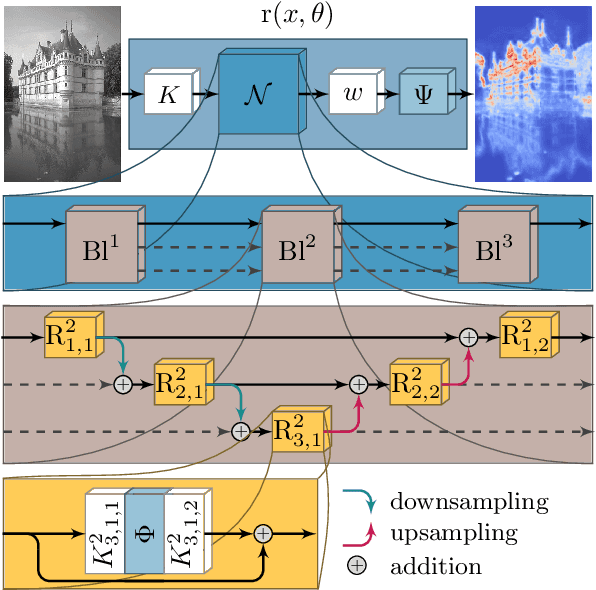
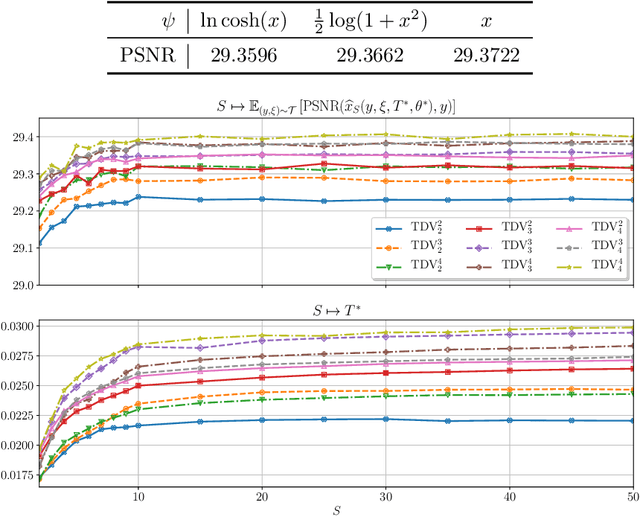
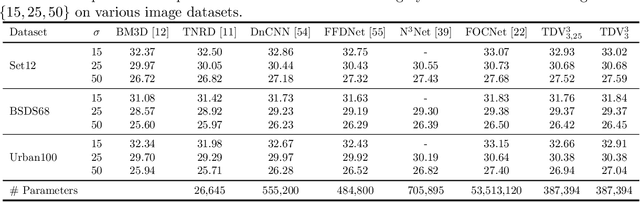
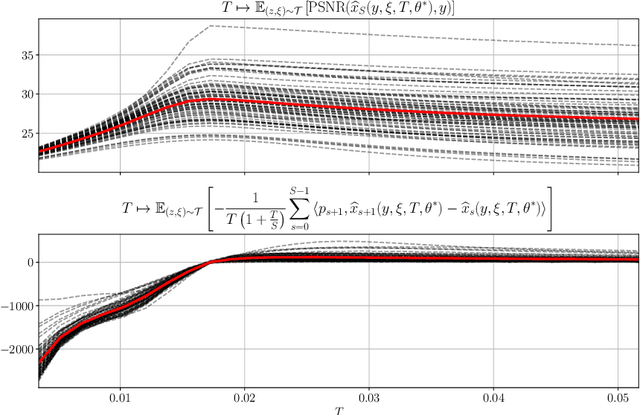
Various problems in computer vision and medical imaging can be cast as inverse problems. A frequent method for solving inverse problems is the variational approach, which amounts to minimizing an energy composed of a data fidelity term and a regularizer. Classically, handcrafted regularizers are used, which are commonly outperformed by state-of-the-art deep learning approaches. In this work, we combine the variational formulation of inverse problems with deep learning by introducing the data-driven general-purpose total deep variation regularizer. In its core, a convolutional neural network extracts local features on multiple scales and in successive blocks. This combination allows for a rigorous mathematical analysis including an optimal control formulation of the training problem in a mean-field setting and a stability analysis with respect to the initial values and the parameters of the regularizer. In addition, we experimentally verify the robustness against adversarial attacks and numerically derive upper bounds for the generalization error. Finally, we achieve state-of-the-art results for numerous imaging tasks.
Belief Propagation Reloaded: Learning BP-Layers for Labeling Problems
Mar 13, 2020
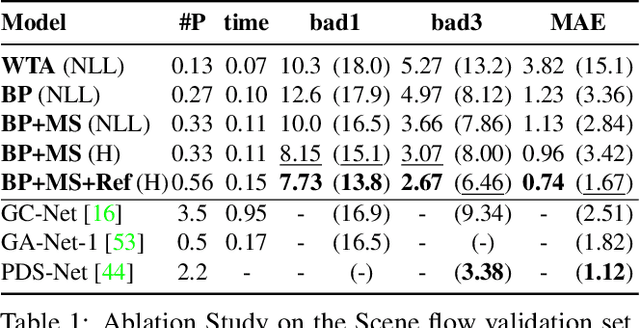
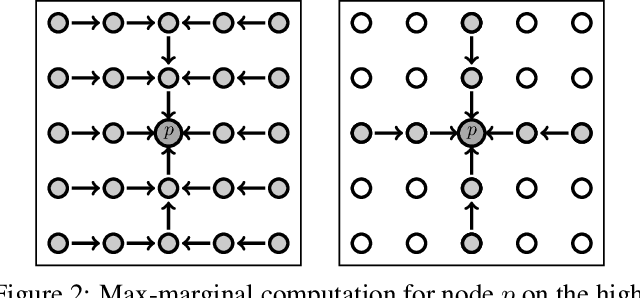
It has been proposed by many researchers that combining deep neural networks with graphical models can create more efficient and better regularized composite models. The main difficulties in implementing this in practice are associated with a discrepancy in suitable learning objectives as well as with the necessity of approximations for the inference. In this work we take one of the simplest inference methods, a truncated max-product Belief Propagation, and add what is necessary to make it a proper component of a deep learning model: We connect it to learning formulations with losses on marginals and compute the backprop operation. This BP-Layer can be used as the final or an intermediate block in convolutional neural networks (CNNs), allowing us to design a hierarchical model composing BP inference and CNNs at different scale levels. The model is applicable to a range of dense prediction problems, is well-trainable and provides parameter-efficient and robust solutions in stereo, optical flow and semantic segmentation.
Total Deep Variation for Linear Inverse Problems
Feb 17, 2020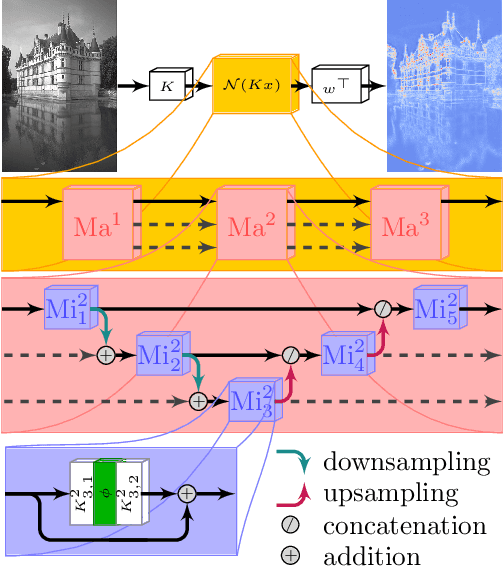
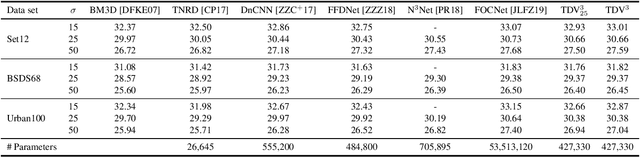
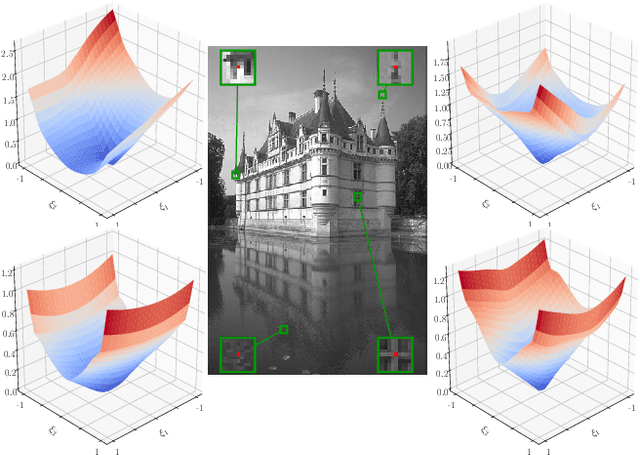
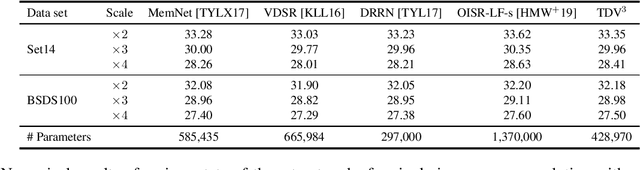
Diverse inverse problems in imaging can be cast as variational problems composed of a task-specific data fidelity term and a regularization term. In this paper, we propose a novel learnable general-purpose regularizer exploiting recent architectural design patterns from deep learning. We cast the learning problem as a discrete sampled optimal control problem, for which we derive the adjoint state equations and an optimality condition. By exploiting the variational structure of our approach, we perform a sensitivity analysis with respect to the learned parameters obtained from different training datasets. Moreover, we carry out a nonlinear eigenfunction analysis, which reveals interesting properties of the learned regularizer. We show state-of-the-art performance for classical image restoration and medical image reconstruction problems.
The Five Elements of Flow
Dec 23, 2019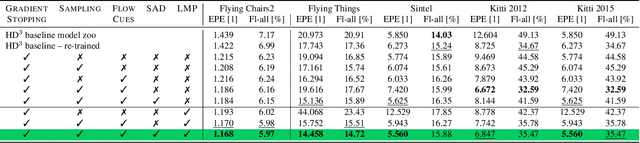
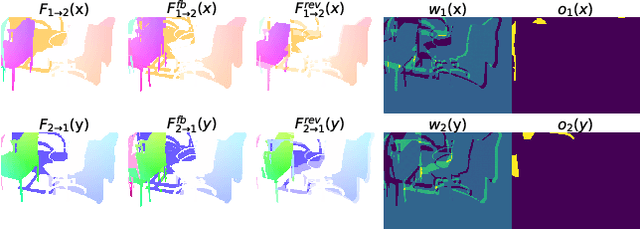
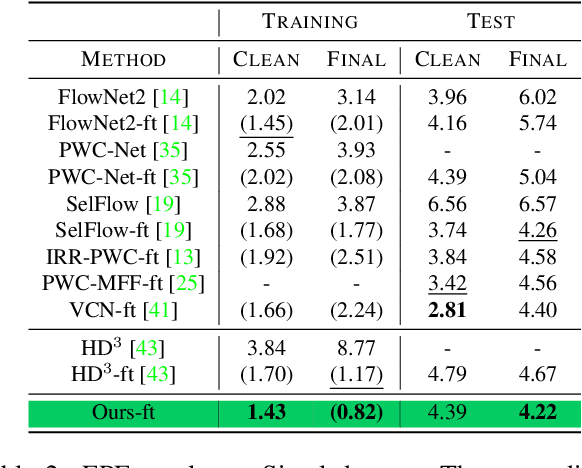
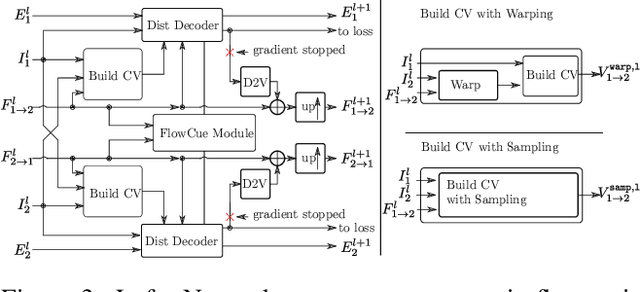
In this work we propose five concrete steps to improve the performance of optical flow algorithms. We carefully reviewed recently introduced innovations and well-established techniques in deep learning-based flow methods including i) pyramidal feature representations, ii) flow-based consistency checks, iii) cost volume construction practices or iv) distillation, and present extensions or alternatives to inhibiting factors we identified therein. We also show how changing the way gradients propagate in modern flow networks can lead to surprising boosts in performance. Finally, we contribute a novel feature that adaptively guides the learning process towards improving on under-performing flow predictions. Our findings are conceptually simple and easy to implement, yet result in compelling improvements on relevant error measures that we demonstrate via exhaustive ablations on datasets like Flying Chairs2, Flying Things, Sintel and KITTI. We establish new state-of-the-art results on the challenging Sintel and Kitti 2015 test datasets, and even show the portability of our findings to different optical flow and depth from stereo approaches.
On the estimation of the Wasserstein distance in generative models
Oct 02, 2019
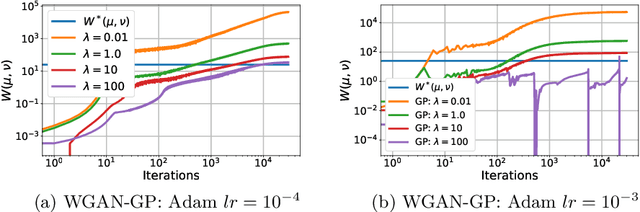

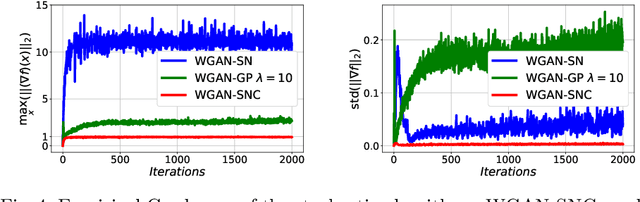
Generative Adversarial Networks (GANs) have been used to model the underlying probability distribution of sample based datasets. GANs are notoriuos for training difficulties and their dependence on arbitrary hyperparameters. One recent improvement in GAN literature is to use the Wasserstein distance as loss function leading to Wasserstein Generative Adversarial Networks (WGANs). Using this as a basis, we show various ways in which the Wasserstein distance is estimated for the task of generative modelling. Additionally, the secrets in training such models are shown and summarized at the end of this work. Where applicable, we extend current works to different algorithms, different cost functions, and different regularization schemes to improve generative models.
Learned Collaborative Stereo Refinement
Jul 31, 2019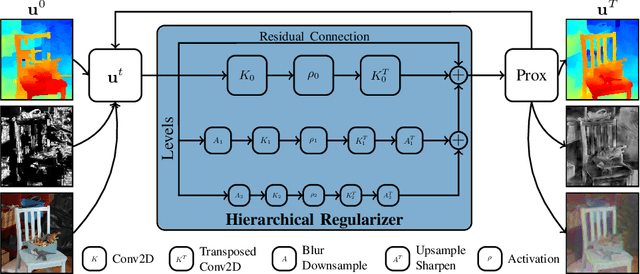
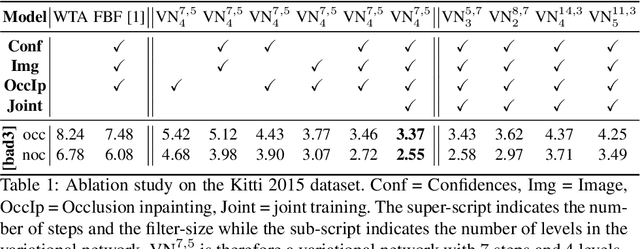
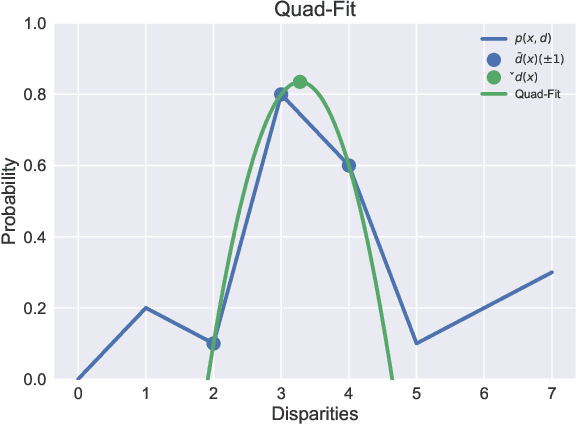
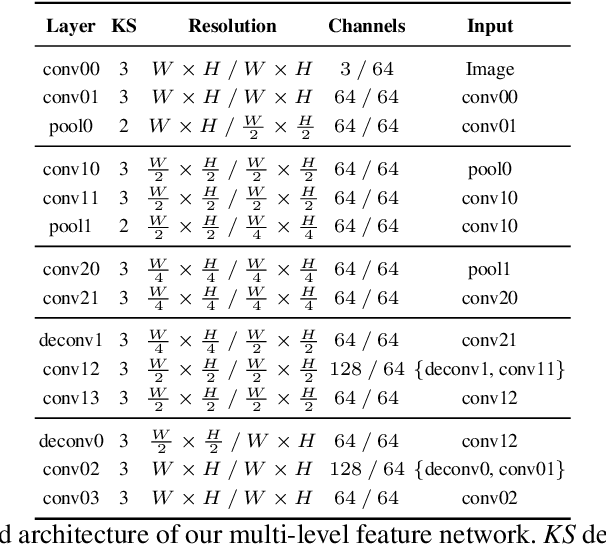
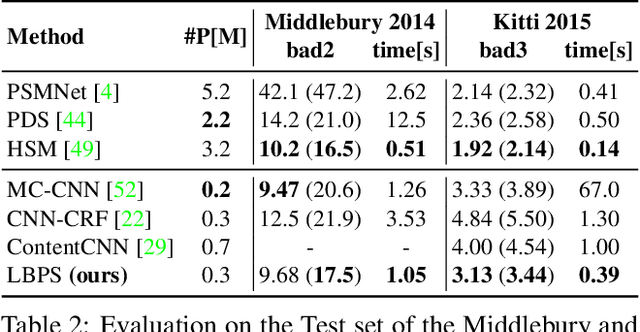
In this work, we propose a learning-based method to denoise and refine disparity maps of a given stereo method. The proposed variational network arises naturally from unrolling the iterates of a proximal gradient method applied to a variational energy defined in a joint disparity, color, and confidence image space. Our method allows to learn a robust collaborative regularizer leveraging the joint statistics of the color image, the confidence map and the disparity map. Due to the variational structure of our method, the individual steps can be easily visualized, thus enabling interpretability of the method. We can therefore provide interesting insights into how our method refines and denoises disparity maps. The efficiency of our method is demonstrated by the publicly available stereo benchmarks Middlebury 2014 and Kitti 2015.
Self-Supervised Learning for Stereo Reconstruction on Aerial Images
Jul 29, 2019
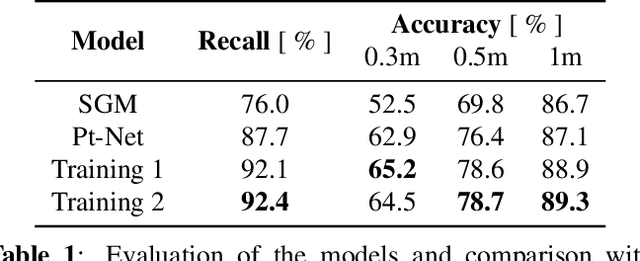
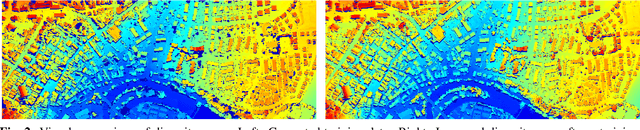
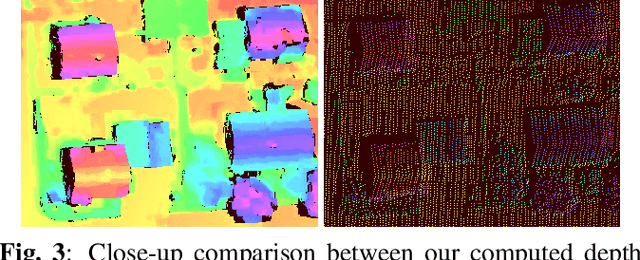
Recent developments established deep learning as an inevitable tool to boost the performance of dense matching and stereo estimation. On the downside, learning these networks requires a substantial amount of training data to be successful. Consequently, the application of these models outside of the laboratory is far from straight forward. In this work we propose a self-supervised training procedure that allows us to adapt our network to the specific (imaging) characteristics of the dataset at hand, without the requirement of external ground truth data. We instead generate interim training data by running our intermediate network on the whole dataset, followed by conservative outlier filtering. Bootstrapped from a pre-trained version of our hybrid CNN-CRF model, we alternate the generation of training data and network training. With this simple concept we are able to lift the completeness and accuracy of the pre-trained version significantly. We also show that our final model compares favorably to other popular stereo estimation algorithms on an aerial dataset.