 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Factual News Headlines in Finnish
Dec 05, 2022We present a novel approach to generating news headlines in Finnish for a given news story. We model this as a summarization task where a model is given a news article, and its task is to produce a concise headline describing the main topic of the article. Because there are no openly available GPT-2 models for Finnish, we will first build such a model using several corpora. The model is then fine-tuned for the headline generation task using a massive news corpus. The system is evaluated by 3 expert journalists working in a Finnish media house. The results showcase the usability of the presented approach as a headline suggestion tool to facilitate the news production process.
Word Order Matters when you Increase Masking
Nov 08, 2022Word order, an essential property of natural languages, is injected in Transformer-based neural language models using position encoding. However, recent experiments have shown that explicit position encoding is not always useful, since some models without such feature managed to achieve state-of-the art performance on some tasks. To understand better this phenomenon, we examine the effect of removing position encodings on the pre-training objective itself (i.e., masked language modelling), to test whether models can reconstruct position information from co-occurrences alone. We do so by controlling the amount of masked tokens in the input sentence, as a proxy to affect the importance of position information for the task. We find that the necessity of position information increases with the amount of masking, and that masked language models without position encodings are not able to reconstruct this information on the task. These findings point towards a direct relationship between the amount of masking and the ability of Transformers to capture order-sensitive aspects of language using position encoding.
Subject Verb Agreement Error Patterns in Meaningless Sentences: Humans vs. BERT
Sep 21, 2022
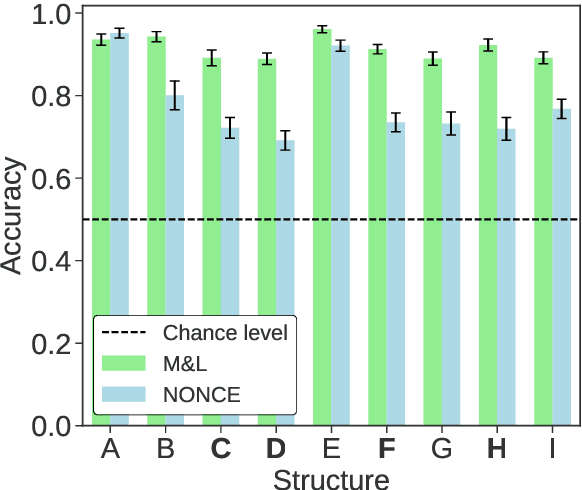
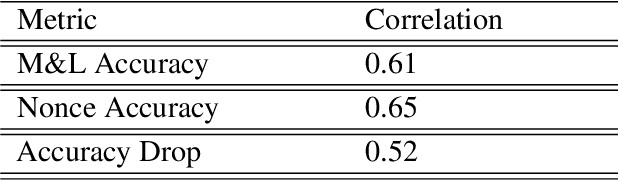
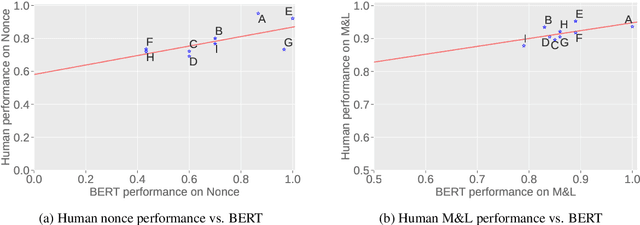
Both humans and neural language models are able to perform subject-verb number agreement (SVA). In principle, semantics shouldn't interfere with this task, which only requires syntactic knowledge. In this work we test whether meaning interferes with this type of agreement in English in syntactic structures of various complexities. To do so, we generate both semantically well-formed and nonsensical items. We compare the performance of BERT-base to that of humans, obtained with a psycholinguistic online crowdsourcing experiment. We find that BERT and humans are both sensitive to our semantic manipulation: They fail more often when presented with nonsensical items, especially when their syntactic structure features an attractor (a noun phrase between the subject and the verb that has not the same number as the subject). We also find that the effect of meaningfulness on SVA errors is stronger for BERT than for humans, showing higher lexical sensitivity of the former on this task.
Probing for the Usage of Grammatical Number
Apr 21, 2022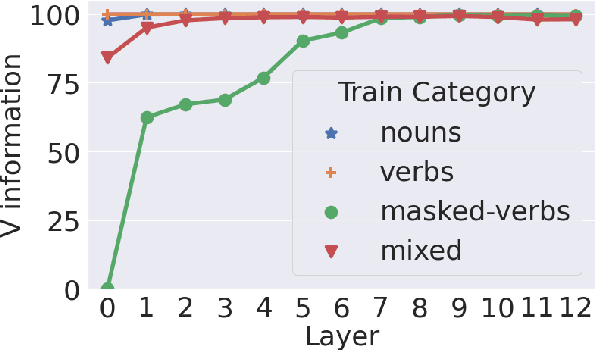
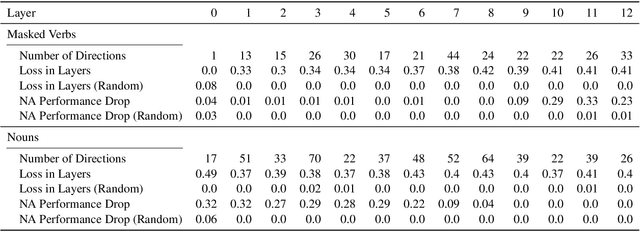
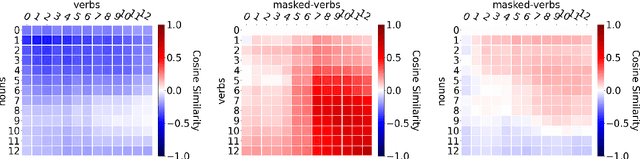
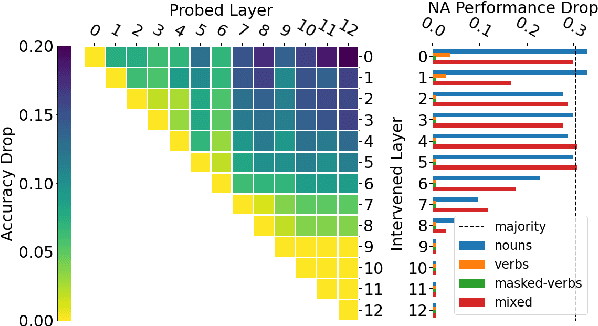
A central quest of probing is to uncover how pre-trained models encode a linguistic property within their representations. An encoding, however, might be spurious-i.e., the model might not rely on it when making predictions. In this paper, we try to find encodings that the model actually uses, introducing a usage-based probing setup. We first choose a behavioral task which cannot be solved without using the linguistic property. Then, we attempt to remove the property by intervening on the model's representations. We contend that, if an encoding is used by the model, its removal should harm the performance on the chosen behavioral task. As a case study, we focus on how BERT encodes grammatical number, and on how it uses this encoding to solve the number agreement task. Experimentally, we find that BERT relies on a linear encoding of grammatical number to produce the correct behavioral output. We also find that BERT uses a separate encoding of grammatical number for nouns and verbs. Finally, we identify in which layers information about grammatical number is transferred from a noun to its head verb.
Does BERT really agree ? Fine-grained Analysis of Lexical Dependence on a Syntactic Task
Apr 14, 2022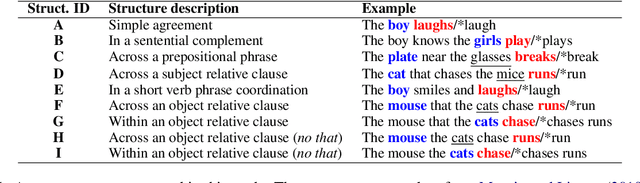
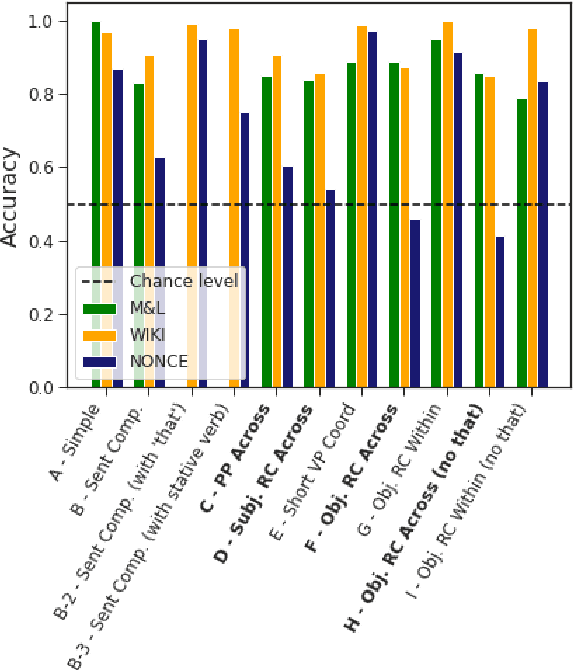
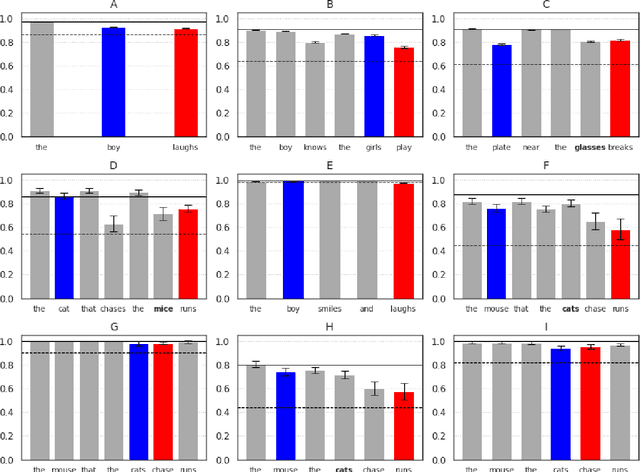

Although transformer-based Neural Language Models demonstrate impressive performance on a variety of tasks, their generalization abilities are not well understood. They have been shown to perform strongly on subject-verb number agreement in a wide array of settings, suggesting that they learned to track syntactic dependencies during their training even without explicit supervision. In this paper, we examine the extent to which BERT is able to perform lexically-independent subject-verb number agreement (NA) on targeted syntactic templates. To do so, we disrupt the lexical patterns found in naturally occurring stimuli for each targeted structure in a novel fine-grained analysis of BERT's behavior. Our results on nonce sentences suggest that the model generalizes well for simple templates, but fails to perform lexically-independent syntactic generalization when as little as one attractor is present.
Automatic Dialect Adaptation in Finnish and its Effect on Perceived Creativity
Sep 06, 2020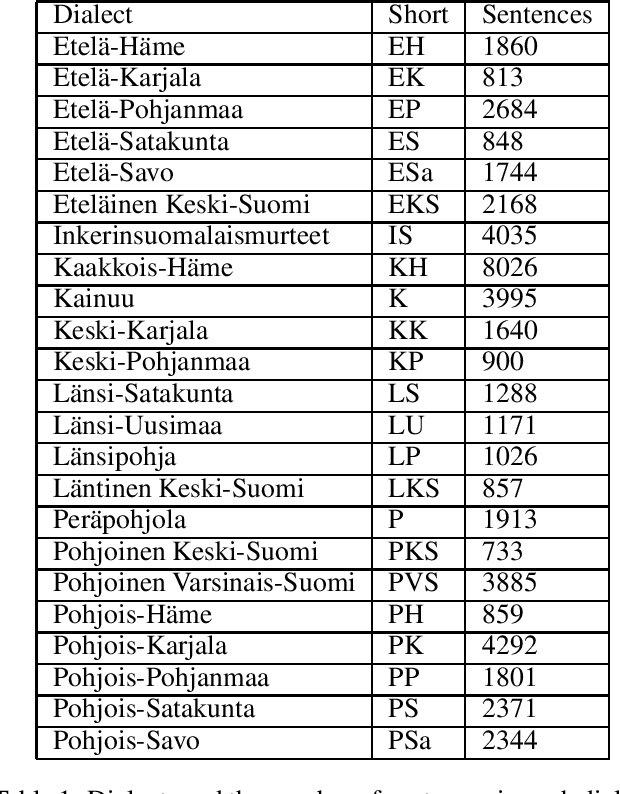

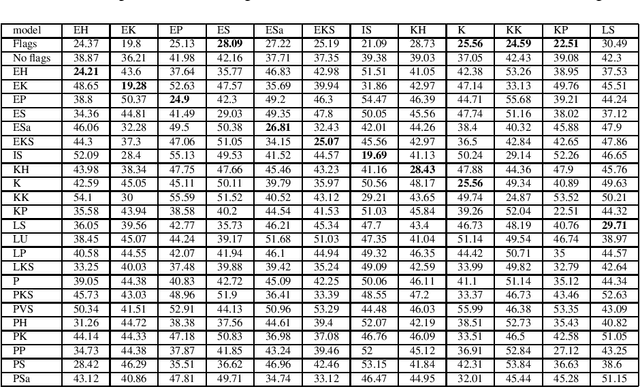
We present a novel approach for adapting text written in standard Finnish to different dialects. We experiment with character level NMT models both by using a multi-dialectal and transfer learning approaches. The models are tested with over 20 different dialects. The results seem to favor transfer learning, although not strongly over the multi-dialectal approach. We study the influence dialectal adaptation has on perceived creativity of computer generated poetry. Our results suggest that the more the dialect deviates from the standard Finnish, the lower scores people tend to give on an existing evaluation metric. However, on a word association test, people associate creativity and originality more with dialect and fluency more with standard Finnish.
Multi-SimLex: A Large-Scale Evaluation of Multilingual and Cross-Lingual Lexical Semantic Similarity
Mar 10, 2020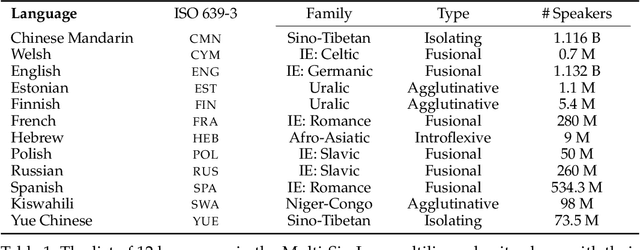
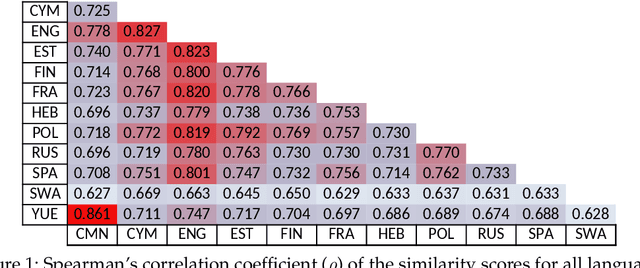

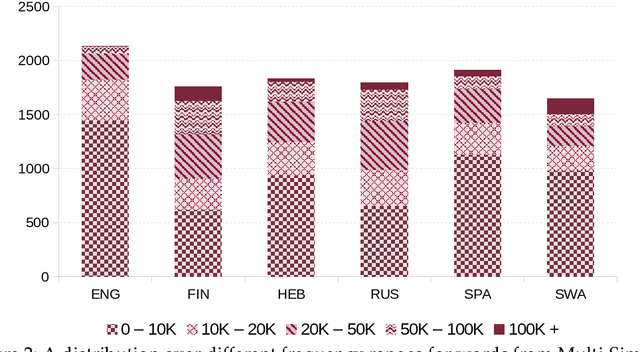
We introduce Multi-SimLex, a large-scale lexical resource and evaluation benchmark covering datasets for 12 typologically diverse languages, including major languages (e.g., Mandarin Chinese, Spanish, Russian) as well as less-resourced ones (e.g., Welsh, Kiswahili). Each language dataset is annotated for the lexical relation of semantic similarity and contains 1,888 semantically aligned concept pairs, providing a representative coverage of word classes (nouns, verbs, adjectives, adverbs), frequency ranks, similarity intervals, lexical fields, and concreteness levels. Additionally, owing to the alignment of concepts across languages, we provide a suite of 66 cross-lingual semantic similarity datasets. Due to its extensive size and language coverage, Multi-SimLex provides entirely novel opportunities for experimental evaluation and analysis. On its monolingual and cross-lingual benchmarks, we evaluate and analyze a wide array of recent state-of-the-art monolingual and cross-lingual representation models, including static and contextualized word embeddings (such as fastText, M-BERT and XLM), externally informed lexical representations, as well as fully unsupervised and (weakly) supervised cross-lingual word embeddings. We also present a step-by-step dataset creation protocol for creating consistent, Multi-Simlex-style resources for additional languages. We make these contributions -- the public release of Multi-SimLex datasets, their creation protocol, strong baseline results, and in-depth analyses which can be be helpful in guiding future developments in multilingual lexical semantics and representation learning -- available via a website which will encourage community effort in further expansion of Multi-Simlex to many more languages. Such a large-scale semantic resource could inspire significant further advances in NLP across languages.
Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing
Jul 02, 2018Addressing the cross-lingual variation of grammatical structures and meaning categorization is a key challenge for multilingual Natural Language Processing. The lack of resources for the majority of the world's languages makes supervised learning not viable. Moreover, the performance of most algorithms is hampered by language-specific biases and the neglect of informative multilingual data. The discipline of Linguistic Typology provides a principled framework to compare languages systematically and empirically and documents their variation in publicly available databases. These enshrine crucial information to design language-independent algorithms and refine techniques devised to mitigate the above-mentioned issues, including cross-lingual transfer and multilingual joint models, with typological features. In this survey, we demonstrate that typology is beneficial to several NLP applications, involving both semantic and syntactic tasks. Moreover, we outline several techniques to extract features from databases or acquire them automatically: these features can be subsequently integrated into multilingual models to tie parameters together cross-lingually or gear a model towards a specific language. Finally, we advocate for a new typology that accounts for the patterns within individual examples rather than entire languages, and for graded categories rather than discrete ones, in oder to bridge the gap with the contextual and continuous nature of machine learning algorithms.
Introduction: Cognitive Issues in Natural Language Processing
Oct 24, 2016This special issue is dedicated to get a better picture of the relationships between computational linguistics and cognitive science. It specifically raises two questions: "what is the potential contribution of computational language modeling to cognitive science?" and conversely: "what is the influence of cognitive science in contemporary computational linguistics?"
Archaeology in the Digital Age: From Paper to Databases
Jul 08, 2015Research units in archaeology often manage large and precious archives containing various documents, including reports on fieldwork, scholarly studies and reference books. These archives are of course invaluable, recording decades of work, but are generally hard to consult and access. In this context, digitizing full text documents is not enough: information must be formalized, structured and easy to access thanks to friendly user interfaces.