 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro Symbolic Knowledge Reasoning for Procedural Video Question Answering
Mar 19, 2025



This paper introduces a new video question-answering (VQA) dataset that challenges models to leverage procedural knowledge for complex reasoning. It requires recognizing visual entities, generating hypotheses, and performing contextual, causal, and counterfactual reasoning. To address this, we propose neuro symbolic reasoning module that integrates neural networks and LLM-driven constrained reasoning over variables for interpretable answer generation. Results show that combining LLMs with structured knowledge reasoning with logic enhances procedural reasoning on the STAR benchmark and our dataset. Code and dataset at https://github.com/LUNAProject22/KML soon.
Keyword-driven Retrieval-Augmented Large Language Models for Cold-start User Recommendations
May 30, 2024



Recent advancements in Large Language Models (LLMs) have shown significant potential in enhancing recommender systems. However, addressing the cold-start recommendation problem, where users lack historical data, remains a considerable challenge. In this paper, we introduce KALM4Rec (Keyword-driven Retrieval-Augmented Large Language Models for Cold-start User Recommendations), a novel framework specifically designed to tackle this problem by requiring only a few input keywords from users in a practical scenario of cold-start user restaurant recommendations. KALM4Rec operates in two main stages: candidates retrieval and LLM-based candidates re-ranking. In the first stage, keyword-driven retrieval models are used to identify potential candidates, addressing LLMs' limitations in processing extensive tokens and reducing the risk of generating misleading information. In the second stage, we employ LLMs with various prompting strategies, including zero-shot and few-shot techniques, to re-rank these candidates by integrating multiple examples directly into the LLM prompts. Our evaluation, using a Yelp restaurant dataset with user reviews from three English-speaking cities, shows that our proposed framework significantly improves recommendation quality. Specifically, the integration of in-context instructions with LLMs for re-ranking markedly enhances the performance of the cold-start user recommender system.
Structured Self-Attention Weights Encode Semantics in Sentiment Analysis
Oct 10, 2020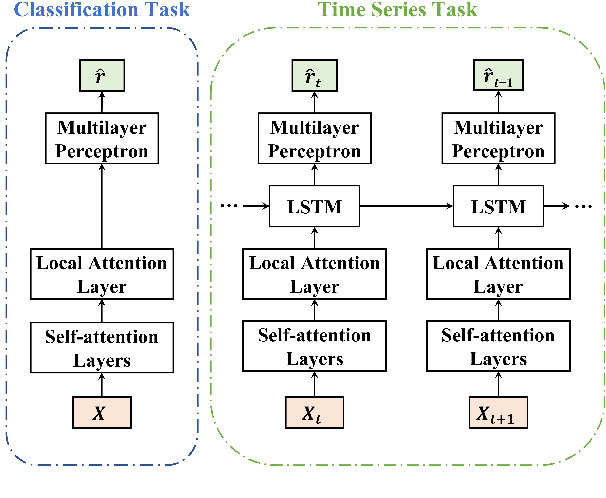
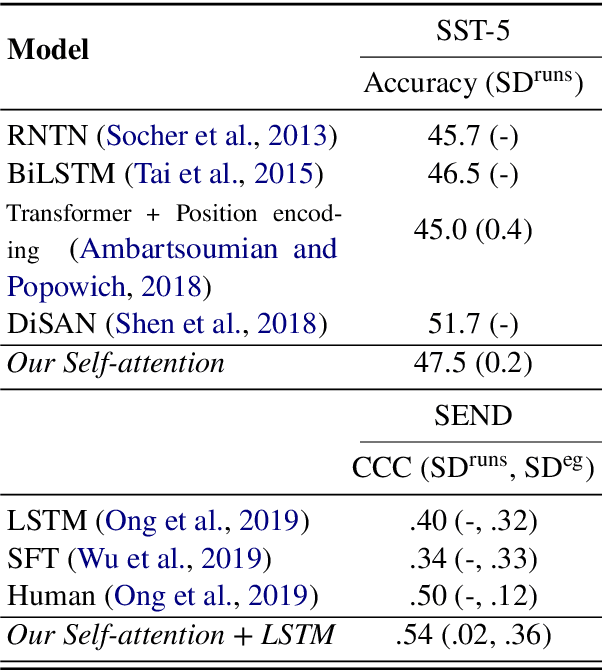
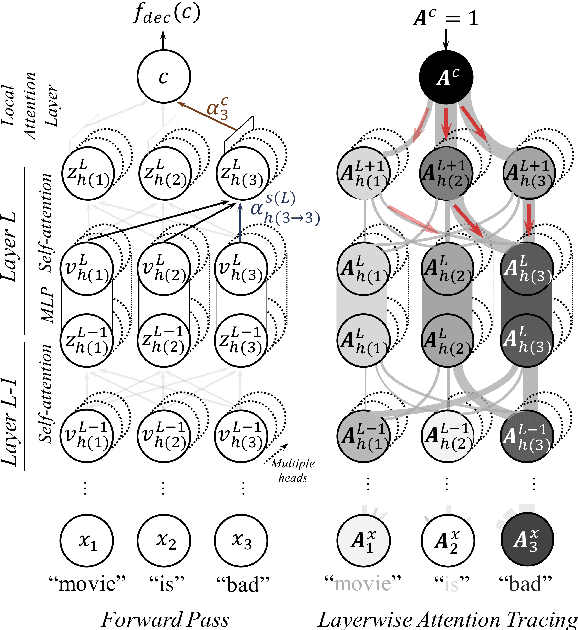
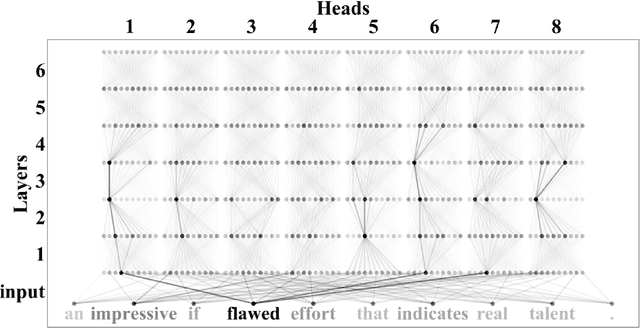
Neural attention, especially the self-attention made popular by the Transformer, has become the workhorse of state-of-the-art natural language processing (NLP) models. Very recent work suggests that the self-attention in the Transformer encodes syntactic information; Here, we show that self-attention scores encode semantics by considering sentiment analysis tasks. In contrast to gradient-based feature attribution methods, we propose a simple and effective Layer-wise Attention Tracing (LAT) method to analyze structured attention weights. We apply our method to Transformer models trained on two tasks that have surface dissimilarities, but share common semantics---sentiment analysis of movie reviews and time-series valence prediction in life story narratives. Across both tasks, words with high aggregated attention weights were rich in emotional semantics, as quantitatively validated by an emotion lexicon labeled by human annotators. Our results show that structured attention weights encode rich semantics in sentiment analysis, and match human interpretations of semantics.
Learning to Caption Images with Two-Stream Attention and Sentence Auto-Encoder
Nov 22, 2019


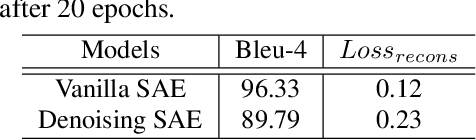
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the correlations between visual and textual cues. To bridge these two modalities, state-of-the-art methods commonly use a dynamic interface between image and text, called attention, that learns to identify related image parts to estimate the next word conditioned on the previous steps. While this mechanism is effective, it fails to find the right associations between visual and textual cues when they are noisy. In this paper we propose two novel approaches to address this issue - (i) a two-stream attention mechanism that can automatically discover latent categories and relate them to image regions based on the previously generated words, (ii) a regularization technique that encapsulates the syntactic and semantic structure of captions and improves the optimization of the image captioning model. Our qualitative and quantitative results demonstrate remarkable improvements on the MSCOCO dataset setting and lead to new state-of-the-art performances for image captioning.
A Multimodal LSTM for Predicting Listener Empathic Responses Over Time
Dec 12, 2018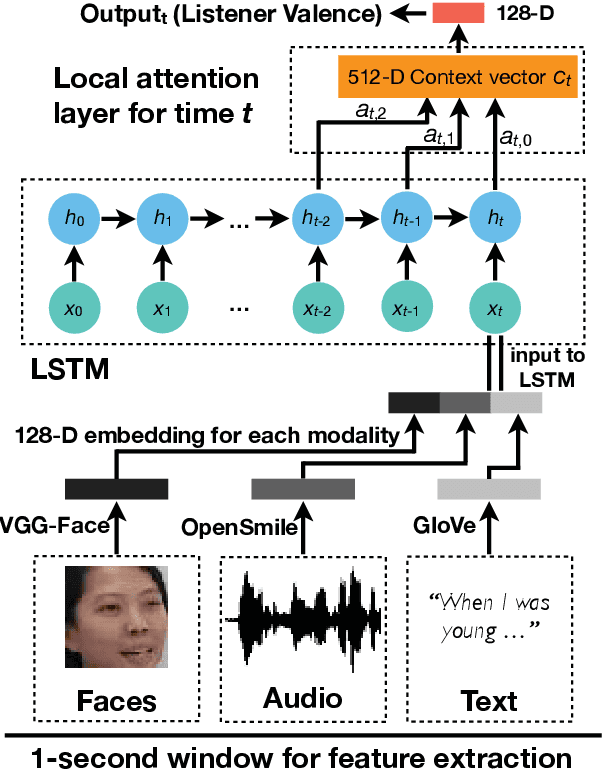
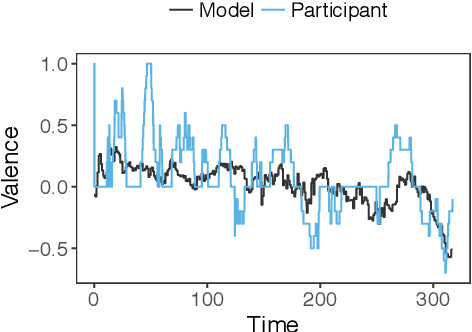
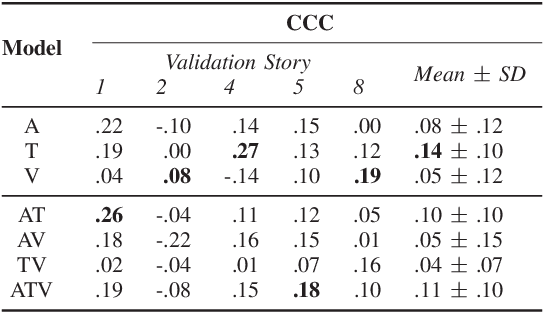
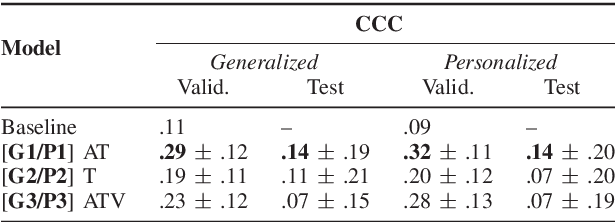
People naturally understand the emotions of-and often also empathize with-those around them. In this paper, we predict the emotional valence of an empathic listener over time as they listen to a speaker narrating a life story. We use the dataset provided by the OMG-Empathy Prediction Challenge, a workshop held in conjunction with IEEE FG 2019. We present a multimodal LSTM model with feature-level fusion and local attention that predicts empathic responses from audio, text, and visual features. Our best-performing model, which used only the audio and text features, achieved a concordance correlation coefficient (CCC) of 0.29 and 0.32 on the Validation set for the Generalized and Personalized track respectively, and achieved a CCC of 0.14 and 0.14 on the held-out Test set. We discuss the difficulties faced and the lessons learnt tackling this challenge.