 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsect-Foundation: A Foundation Model and Large-scale 1M Dataset for Visual Insect Understanding
Nov 26, 2023



In precision agriculture, the detection and recognition of insects play an essential role in the ability of crops to grow healthy and produce a high-quality yield. The current machine vision model requires a large volume of data to achieve high performance. However, there are approximately 5.5 million different insect species in the world. None of the existing insect datasets can cover even a fraction of them due to varying geographic locations and acquisition costs. In this paper, we introduce a novel ``Insect-1M'' dataset, a game-changing resource poised to revolutionize insect-related foundation model training. Covering a vast spectrum of insect species, our dataset, including 1 million images with dense identification labels of taxonomy hierarchy and insect descriptions, offers a panoramic view of entomology, enabling foundation models to comprehend visual and semantic information about insects like never before. Then, to efficiently establish an Insect Foundation Model, we develop a micro-feature self-supervised learning method with a Patch-wise Relevant Attention mechanism capable of discerning the subtle differences among insect images. In addition, we introduce Description Consistency loss to improve micro-feature modeling via insect descriptions. Through our experiments, we illustrate the effectiveness of our proposed approach in insect modeling and achieve State-of-the-Art performance on standard benchmarks of insect-related tasks. Our Insect Foundation Model and Dataset promise to empower the next generation of insect-related vision models, bringing them closer to the ultimate goal of precision agriculture.
Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
May 25, 2023Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the egocentric view. First, we introduce a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
Fairness Continual Learning Approach to Semantic Scene Understanding in Open-World Environments
May 25, 2023Continual semantic segmentation aims to learn new classes while maintaining the information from the previous classes. Although prior studies have shown impressive progress in recent years, the fairness concern in the continual semantic segmentation needs to be better addressed. Meanwhile, fairness is one of the most vital factors in deploying the deep learning model, especially in human-related or safety applications. In this paper, we present a novel Fairness Continual Learning approach to the semantic segmentation problem. In particular, under the fairness objective, a new fairness continual learning framework is proposed based on class distributions. Then, a novel Prototypical Contrastive Clustering loss is proposed to address the significant challenges in continual learning, i.e., catastrophic forgetting and background shift. Our proposed loss has also been proven as a novel, generalized learning paradigm of knowledge distillation commonly used in continual learning. Moreover, the proposed Conditional Structural Consistency loss further regularized the structural constraint of the predicted segmentation. Our proposed approach has achieved State-of-the-Art performance on three standard scene understanding benchmarks, i.e., ADE20K, Cityscapes, and Pascal VOC, and promoted the fairness of the segmentation model.
CoMaL: Conditional Maximum Likelihood Approach to Self-supervised Domain Adaptation in Long-tail Semantic Segmentation
Apr 14, 2023



The research in self-supervised domain adaptation in semantic segmentation has recently received considerable attention. Although GAN-based methods have become one of the most popular approaches to domain adaptation, they have suffered from some limitations. They are insufficient to model both global and local structures of a given image, especially in small regions of tail classes. Moreover, they perform bad on the tail classes containing limited number of pixels or less training samples. In order to address these issues, we present a new self-supervised domain adaptation approach to tackle long-tail semantic segmentation in this paper. Firstly, a new metric is introduced to formulate long-tail domain adaptation in the segmentation problem. Secondly, a new Conditional Maximum Likelihood (CoMaL) approach in an autoregressive framework is presented to solve the problem of long-tail domain adaptation. Although other segmentation methods work under the pixel independence assumption, the long-tailed pixel distributions in CoMaL are generally solved in the context of structural dependency, as that is more realistic. Finally, the proposed method is evaluated on popular large-scale semantic segmentation benchmarks, i.e., "SYNTHIA to Cityscapes" and "GTA to Cityscapes", and outperforms the prior methods by a large margin in both the standard and the proposed evaluation protocols.
CROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023



Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
FREDOM: Fairness Domain Adaptation Approach to Semantic Scene Understanding
Apr 04, 2023



Although Domain Adaptation in Semantic Scene Segmentation has shown impressive improvement in recent years, the fairness concerns in the domain adaptation have yet to be well defined and addressed. In addition, fairness is one of the most critical aspects when deploying the segmentation models into human-related real-world applications, e.g., autonomous driving, as any unfair predictions could influence human safety. In this paper, we propose a novel Fairness Domain Adaptation (FREDOM) approach to semantic scene segmentation. In particular, from the proposed formulated fairness objective, a new adaptation framework will be introduced based on the fair treatment of class distributions. Moreover, to generally model the context of structural dependency, a new conditional structural constraint is introduced to impose the consistency of predicted segmentation. Thanks to the proposed Conditional Structure Network, the self-attention mechanism has sufficiently modeled the structural information of segmentation. Through the ablation studies, the proposed method has shown the performance improvement of the segmentation models and promoted fairness in the model predictions. The experimental results on the two standard benchmarks, i.e., SYNTHIA $\to$ Cityscapes and GTA5 $\to$ Cityscapes, have shown that our method achieved State-of-the-Art (SOTA) performance.
CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars
Dec 01, 2022



Although unsupervised domain adaptation methods have achieved remarkable performance in semantic scene segmentation in visual perception for self-driving cars, these approaches remain impractical in real-world use cases. In practice, the segmentation models may encounter new data that have not been seen yet. Also, the previous data training of segmentation models may be inaccessible due to privacy problems. Therefore, to address these problems, in this work, we propose a Continual Unsupervised Domain Adaptation (CONDA) approach that allows the model to continuously learn and adapt with respect to the presence of the new data. Moreover, our proposed approach is designed without the requirement of accessing previous training data. To avoid the catastrophic forgetting problem and maintain the performance of the segmentation models, we present a novel Bijective Maximum Likelihood loss to impose the constraint of predicted segmentation distribution shifts. The experimental results on the benchmark of continual unsupervised domain adaptation have shown the advanced performance of the proposed CONDA method.
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022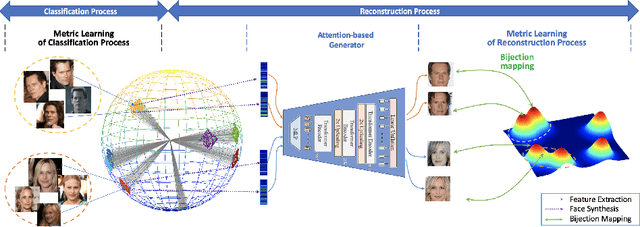

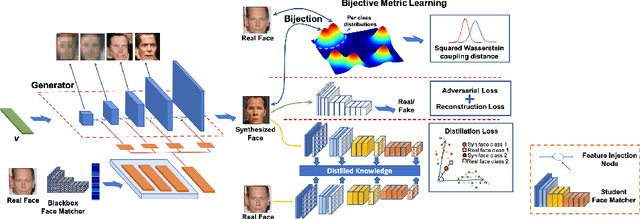
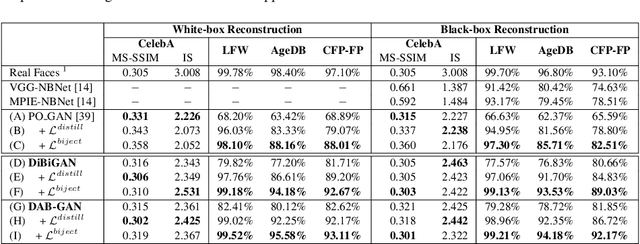
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.
Self-supervised Domain Adaptation in Crowd Counting
Jun 07, 2022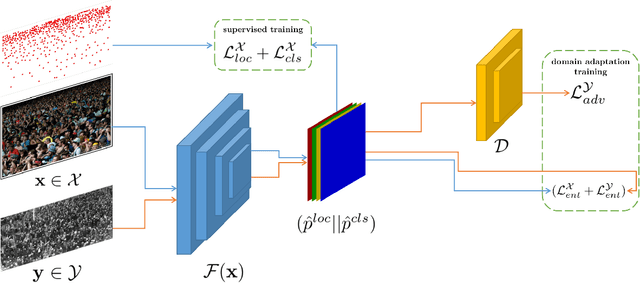
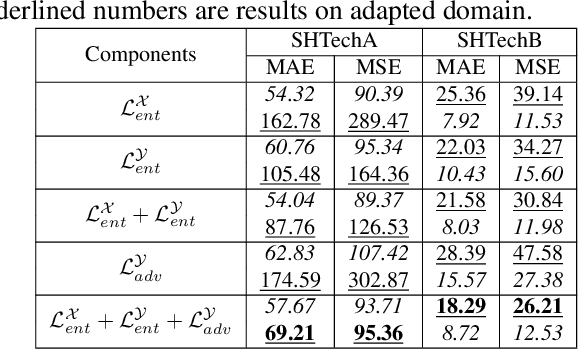
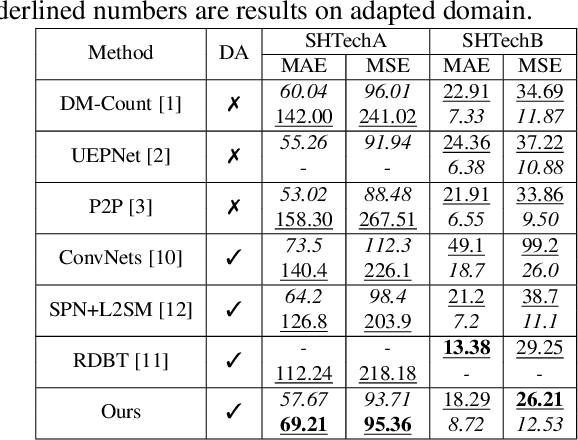

Self-training crowd counting has not been attentively explored though it is one of the important challenges in computer vision. In practice, the fully supervised methods usually require an intensive resource of manual annotation. In order to address this challenge, this work introduces a new approach to utilize existing datasets with ground truth to produce more robust predictions on unlabeled datasets, named domain adaptation, in crowd counting. While the network is trained with labeled data, samples without labels from the target domain are also added to the training process. In this process, the entropy map is computed and minimized in addition to the adversarial training process designed in parallel. Experiments on Shanghaitech, UCF_CC_50, and UCF-QNRF datasets prove a more generalized improvement of our method over the other state-of-the-arts in the cross-domain setting.
OTAdapt: Optimal Transport-based Approach For Unsupervised Domain Adaptation
May 22, 2022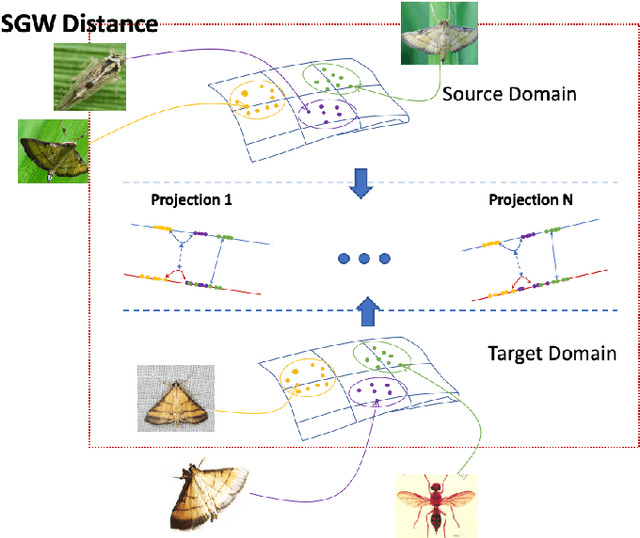
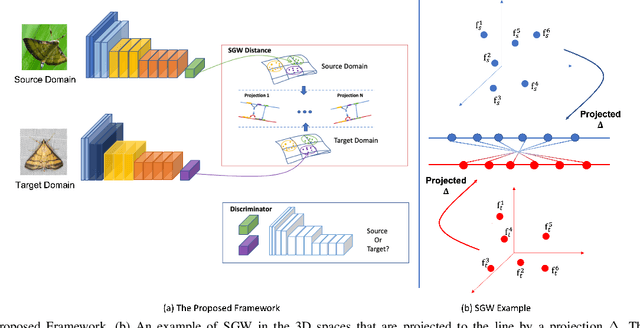

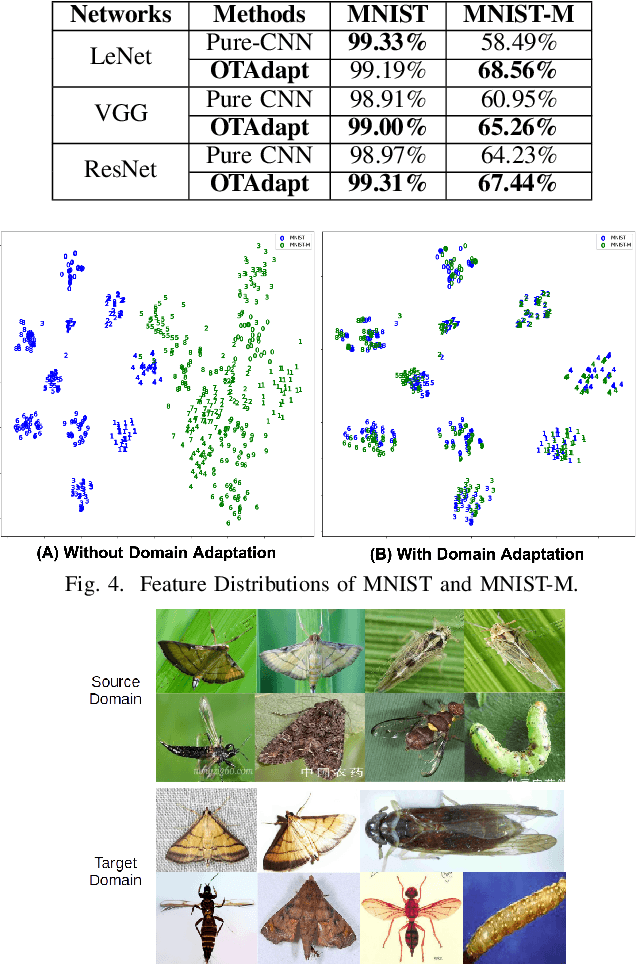
Unsupervised domain adaptation is one of the challenging problems in computer vision. This paper presents a novel approach to unsupervised domain adaptations based on the optimal transport-based distance. Our approach allows aligning target and source domains without the requirement of meaningful metrics across domains. In addition, the proposal can associate the correct mapping between source and target domains and guarantee a constraint of topology between source and target domains. The proposed method is evaluated on different datasets in various problems, i.e. (i) digit recognition on MNIST, MNIST-M, USPS datasets, (ii) Object recognition on Amazon, Webcam, DSLR, and VisDA datasets, (iii) Insect Recognition on the IP102 dataset. The experimental results show that our proposed method consistently improves performance accuracy. Also, our framework could be incorporated with any other CNN frameworks within an end-to-end deep network design for recognition problems to improve their performance.