 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Diverse Scientific Hypothesis Search with Large Language Models
Jun 09, 2026Large language models (LLMs) are on the rise for accelerating scientific discovery, most recently in advanced tasks such as generating valid scientific hypotheses. Yet in many discovery settings, the goal is not to identify a single best hypothesis since validation can be noisy and expensive, and scientists benefit from a set of high-quality alternative hypotheses that hedge against downstream uncertainty for the best solutions. Nevertheless, commonly used evolutionary search recipes tend to prioritize optimization over exploration in hypothesis generation, and the resulting selection pressure during the search process leads to diversity collapse. Motivated by these limitations, we formulate hypothesis search as a sampling problem, where the objective is to efficiently produce diverse, high-quality hypotheses under a fixed validation budget. Building on this perspective, we propose \ours, an evolutionary framework inspired by the classical parallel tempering algorithm that searches hypotheses at multiple temperature levels and enables principled information exchange across temperatures to improve exploration without disrupting convergence. Across domains including molecular discovery, equation discovery, and algorithm discovery, our approach consistently improves both hypothesis quality and diversity under the same validation budget, and produces candidates that remain robust under more expensive downstream computational validations.
SynLlama: Generating Synthesizable Molecules and Their Analogs with Large Language Models
Mar 16, 2025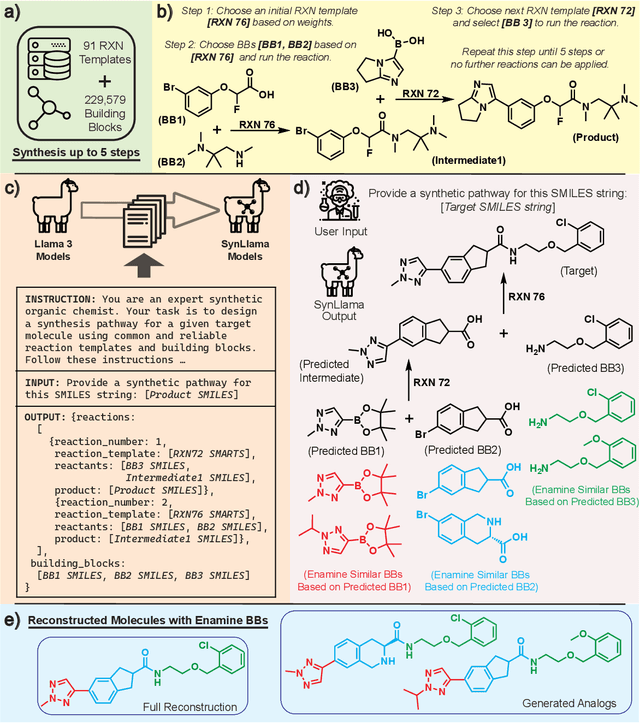
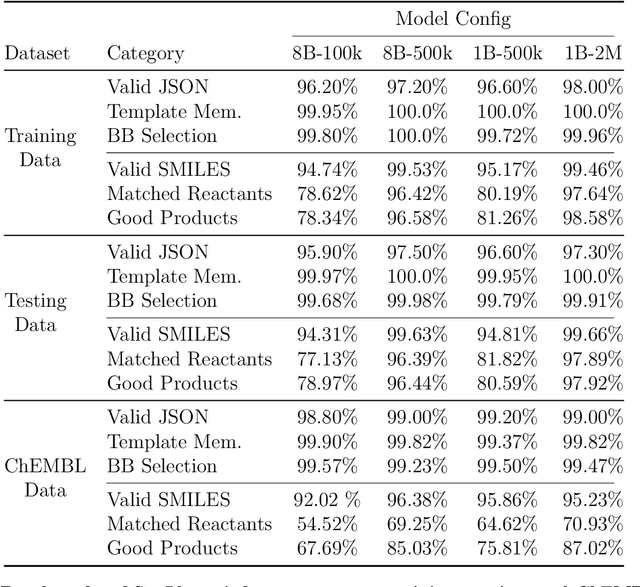
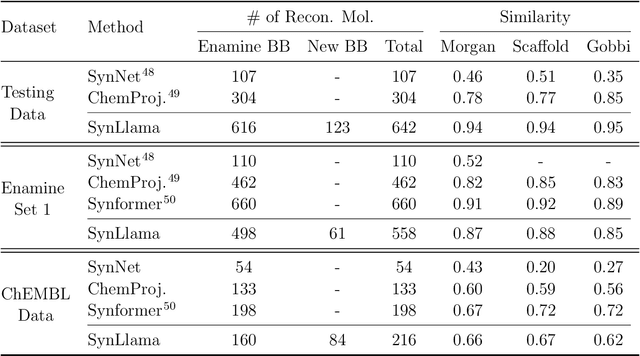
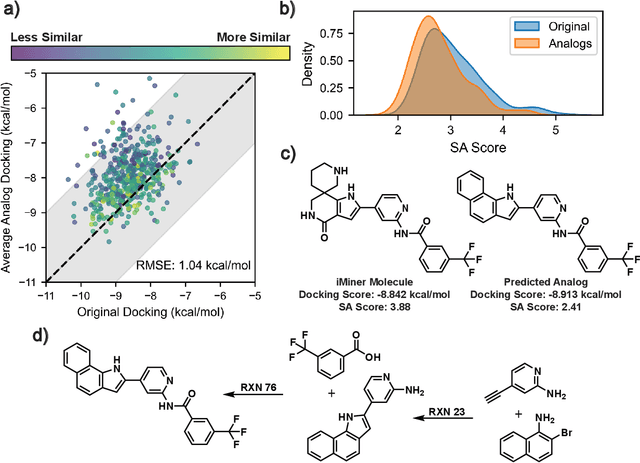
Generative machine learning models for small molecule drug discovery have shown immense promise, but many molecules generated by this approach are too difficult to synthesize to be worth further investigation or further development. We present a novel approach by fine-tuning Meta's Llama3 large language models (LLMs) to create SynLlama, which generates full synthetic pathways made of commonly accessible Enamine building blocks and robust organic reaction templates. SynLlama explores a large synthesizable space using significantly less data compared to other state-of-the-art methods, and offers strong performance in bottom-up synthesis, synthesizable analog generation, and hit expansion, offering medicinal chemists a valuable tool for drug discovery developments. We find that SynLlama can effectively generalize to unseen yet purchasable building blocks, meaning that its reconstruction capabilities extend to a broader synthesizable chemical space than the training data.
SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration
Sep 03, 2024



Here we show that a Large Language Model (LLM) can serve as a foundation model for a Chemical Language Model (CLM) which performs at or above the level of CLMs trained solely on chemical SMILES string data. Using supervised fine-tuning (SFT) and direct preference optimization (DPO) on the open-source Llama LLM, we demonstrate that we can train an LLM to respond to prompts such as generating molecules with properties of interest to drug development. This overall framework allows an LLM to not just be a chatbot client for chemistry and materials tasks, but can be adapted to speak more directly as a CLM which can generate molecules with user-specified properties.