 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCoder Benchmark: Bridging Language Generation and Quantum Hardware through Simulator-Based Feedback
Oct 30, 2025Large language models (LLMs) have increasingly been applied to automatic programming code generation. This task can be viewed as a language generation task that bridges natural language, human knowledge, and programming logic. However, it remains underexplored in domains that require interaction with hardware devices, such as quantum programming, where human coders write Python code that is executed on a quantum computer. To address this gap, we introduce QCoder Benchmark, an evaluation framework that assesses LLMs on quantum programming with feedback from simulated hardware devices. Our benchmark offers two key features. First, it supports evaluation using a quantum simulator environment beyond conventional Python execution, allowing feedback of domain-specific metrics such as circuit depth, execution time, and error classification, which can be used to guide better generation. Second, it incorporates human-written code submissions collected from real programming contests, enabling both quantitative comparisons and qualitative analyses of LLM outputs against human-written codes. Our experiments reveal that even advanced models like GPT-4o achieve only around 18.97% accuracy, highlighting the difficulty of the benchmark. In contrast, reasoning-based models such as o3 reach up to 78% accuracy, outperforming averaged success rates of human-written codes (39.98%). We release the QCoder Benchmark dataset and public evaluation API to support further research.
Generative quantum combinatorial optimization by means of a novel conditional generative quantum eigensolver
Jan 28, 2025Quantum computing is entering a transformative phase with the emergence of logical quantum processors, which hold the potential to tackle complex problems beyond classical capabilities. While significant progress has been made, applying quantum algorithms to real-world problems remains challenging. Hybrid quantum-classical techniques have been explored to bridge this gap, but they often face limitations in expressiveness, trainability, or scalability. In this work, we introduce conditional Generative Quantum Eigensolver (conditional-GQE), a context-aware quantum circuit generator powered by an encoder-decoder Transformer. Focusing on combinatorial optimization, we train our generator for solving problems with up to 10 qubits, exhibiting nearly perfect performance on new problems. By leveraging the high expressiveness and flexibility of classical generative models, along with an efficient preference-based training scheme, conditional-GQE provides a generalizable and scalable framework for quantum circuit generation. Our approach advances hybrid quantum-classical computing and contributes to accelerate the transition toward fault-tolerant quantum computing.
Scaling Law of Sim2Real Transfer Learning in Expanding Computational Materials Databases for Real-World Predictions
Aug 07, 2024To address the challenge of limited experimental materials data, extensive physical property databases are being developed based on high-throughput computational experiments, such as molecular dynamics simulations. Previous studies have shown that fine-tuning a predictor pretrained on a computational database to a real system can result in models with outstanding generalization capabilities compared to learning from scratch. This study demonstrates the scaling law of simulation-to-real (Sim2Real) transfer learning for several machine learning tasks in materials science. Case studies of three prediction tasks for polymers and inorganic materials reveal that the prediction error on real systems decreases according to a power-law as the size of the computational data increases. Observing the scaling behavior offers various insights for database development, such as determining the sample size necessary to achieve a desired performance, identifying equivalent sample sizes for physical and computational experiments, and guiding the design of data production protocols for downstream real-world tasks.
Transfer learning with affine model transformation
Oct 18, 2022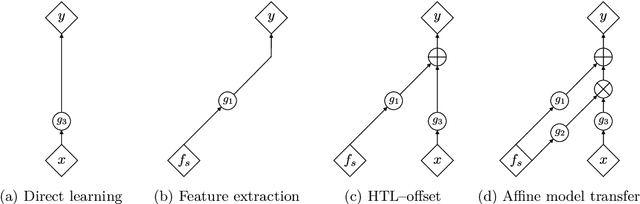
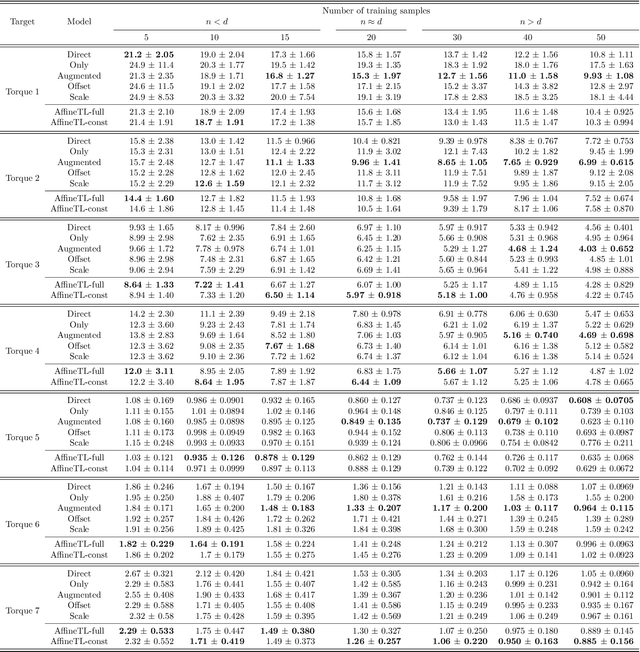
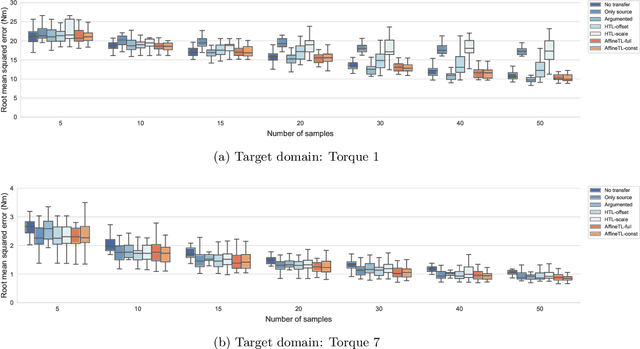

Supervised transfer learning (TL) has received considerable attention because of its potential to boost the predictive power of machine learning in cases with limited data. In a conventional scenario, cross-domain differences are modeled and estimated using a given set of source models and samples from a target domain. For example, if there is a functional relationship between source and target domains, only domain-specific factors are additionally learned using target samples to shift the source models to the target. However, the general methodology for modeling and estimating such cross-domain shifts has been less studied. This study presents a TL framework that simultaneously and separately estimates domain shifts and domain-specific factors using given target samples. Assuming consistency and invertibility of the domain transformation functions, we derive an optimal family of functions to represent the cross-domain shift. The newly derived class of transformation functions takes the same form as invertible neural networks using affine coupling layers, which are widely used in generative deep learning. We show that the proposed method encompasses a wide range of existing methods, including the most common TL procedure based on feature extraction using neural networks. We also clarify the theoretical properties of the proposed method, such as the convergence rate of the generalization error, and demonstrate the practical benefits of separately modeling and estimating domain-specific factors through several case studies.
A General Class of Transfer Learning Regression without Implementation Cost
Jun 23, 2020
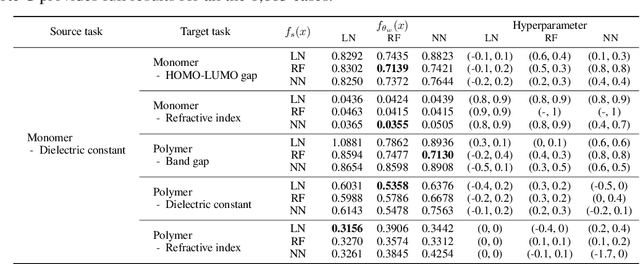
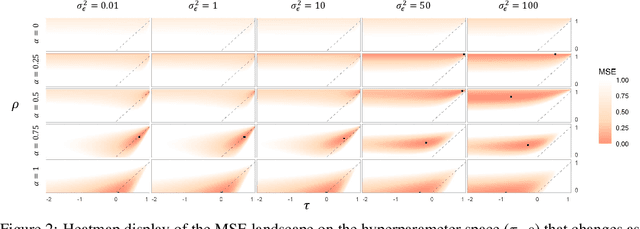
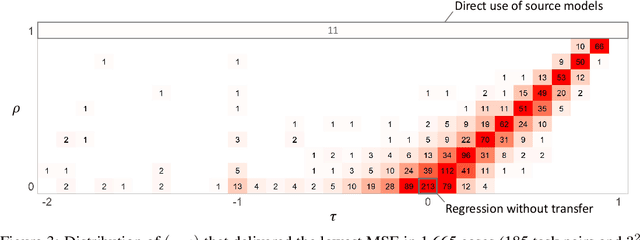
We propose a novel framework that unifies and extends existing methods of transfer learning (TL) for regression. To bridge a pretrained source model to the model on a target task, we introduce a density-ratio reweighting function, which is estimated through the Bayesian framework with a specific prior distribution. By changing two intrinsic hyperparameters and the choice of the density-ratio model, the proposed method can integrate three popular methods of TL: TL based on cross-domain similarity regularization, a probabilistic TL using the density-ratio estimation, and fine-tuning of pretrained neural networks. Moreover, the proposed method can benefit from its simple implementation without any additional cost; the model can be fully trained using off-the-shelf libraries for supervised learning in which the original output variable is simply transformed to a new output. We demonstrate its simplicity, generality, and applicability using various real data applications.