 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Task and Metrics of Instance Segmentation on 3D Point Clouds
Sep 27, 2019

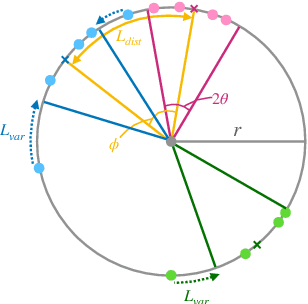
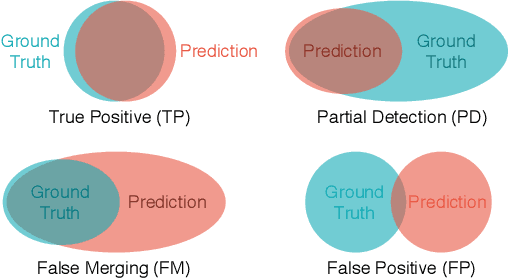
Instance segmentation on 3D point clouds is one of the most extensively researched areas toward the realization of autonomous cars and robots. Certain existing studies have split input point clouds into small regions such as 1m x 1m; one reason for this is that models in the studies cannot consume a large number of points because of the large space complexity. However, because such small regions occasionally include a very small number of instances belonging to the same class, an evaluation using existing metrics such as mAP is largely affected by the category recognition performance. To address these problems, we propose a new method with space complexity O(Np) such that large regions can be consumed, as well as novel metrics for tasks that are independent of the categories or size of the inputs. Our method learns a mapping from input point clouds to an embedding space, where the embeddings form clusters for each instance and distinguish instances using these clusters during testing. Our method achieves state-of-the-art performance using both existing and the proposed metrics. Moreover, we show that our new metric can evaluate the performance of a task without being affected by any other condition.
RGBD-GAN: Unsupervised 3D Representation Learning From Natural Image Datasets via RGBD Image Synthesis
Sep 27, 2019
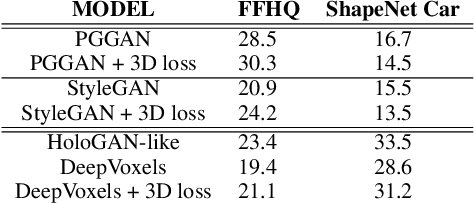
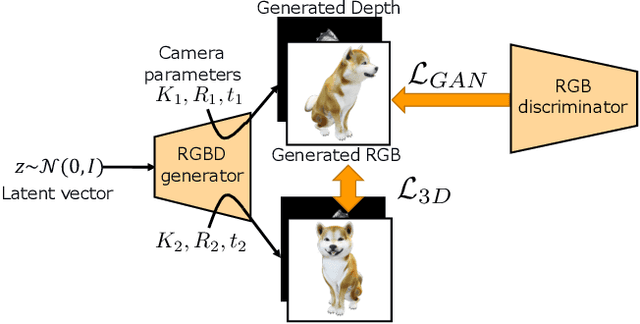
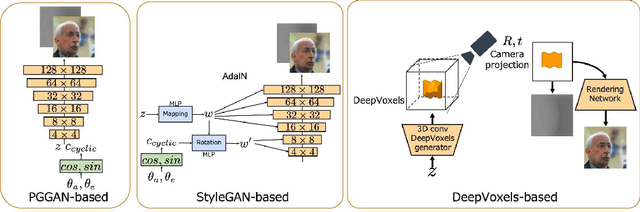
Understanding three-dimensional (3D) geometries from two-dimensional (2D) images without any labeled information is promising for understanding the real world without incurring annotation cost. We herein propose a novel generative model, RGBD-GAN, which achieves unsupervised 3D representation learning from 2D images. The proposed method enables camera parameter conditional image generation and depth image generation without any 3D annotations such as camera poses or depth. We used an explicit 3D consistency loss for two RGBD images generated from different camera parameters in addition to the ordinal GAN objective. The loss is simple yet effective for any type of image generator such as the DCGAN and StyleGAN to be conditioned on camera parameters. We conducted experiments and demonstrated that the proposed method could learn 3D representations from 2D images with various generator architectures.
GRAM: Scalable Generative Models for Graphs with Graph Attention Mechanism
Jun 05, 2019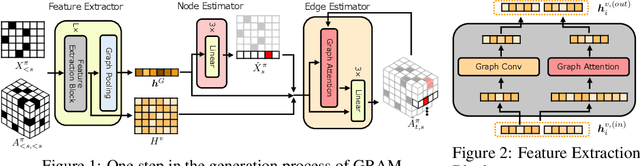
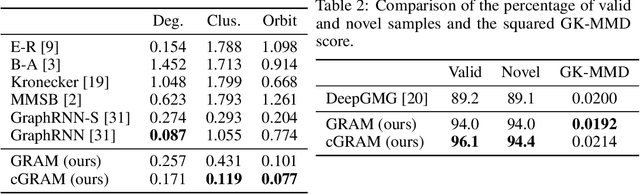
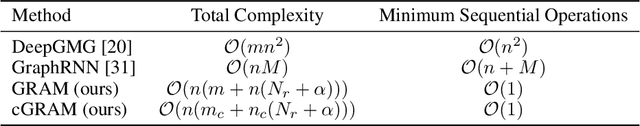
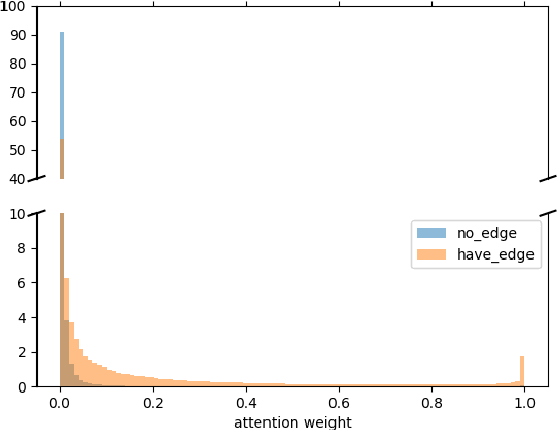
Graphs are ubiquitous real-world data structures, and generative models that can approximate distributions over graphs and derive samples from it have significant importance. There are several known challenges in graph generation tasks, and scalability handling large graphs and datasets is one of the most important for applications in a wide range of real-world domains. Although an increasing number of graph generative models have been proposed in the field of machine learning that have demonstrated impressive results in several tasks, scalability is still an unresolved problem owing to the complex generation process or difficulty in training parallelization. In this work, we first define scalability from three different perspectives: number of nodes, data, and node/edge labels, and then we propose GRAM, a generative model for real-world graphs that is scalable in all the three contexts, especially on training. We aim to achieve scalability by employing a novel graph attention mechanism, formulating the likelihood of graphs in a simple and general manner and utilizing the properties of real-world graphs such as community structure and sparseness of edges. Furthermore, we construct a non-domain-specific evaluation metric in node/edge-labeled graph generation tasks that combine a graph kernel and Maximum Mean Discrepancy. Our experiments on real-world graph datasets showed that our models can scale up to large graphs and datasets that baseline models had difficulty handling, and demonstrated results that were competitive with or superior than the baseline methods.
Invariant Tensor Feature Coding
Jun 05, 2019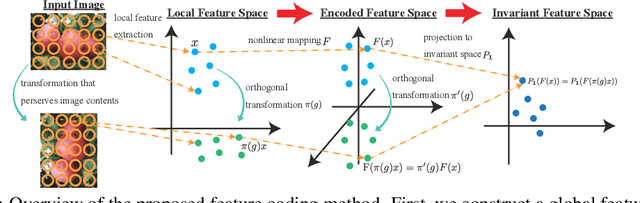
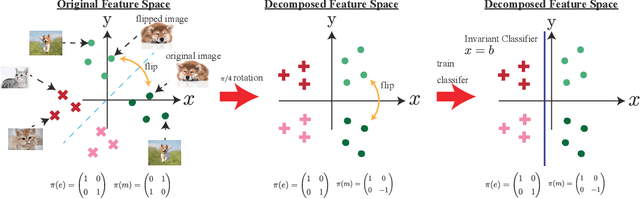
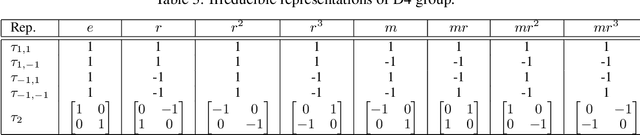
We propose a novel feature coding method that exploits invariance. We consider the setting where the transformations that preserve the image contents compose a finite group of orthogonal matrices. This is the case in many image transformations such as image rotations and image flipping. We prove that the group-invariant feature vector contains sufficient discriminative information when we learn a linear classifier using convex loss minimization. From this result, we propose a novel feature modeling for principal component analysis, and k-means clustering, which are used for most feature coding methods, and global feature functions that explicitly consider the group action. Although the global feature functions are complex nonlinear functions in general, we can calculate the group action on this space easily by constructing the functions as the tensor product representations of basic representations, resulting in the explicit form of invariant feature functions. We demonstrate the effectiveness of our methods on several image datasets.
Compact Approximation for Polynomial of Covariance Feature
Jun 05, 2019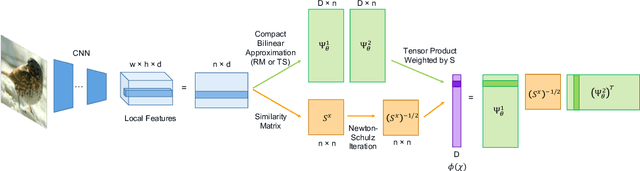

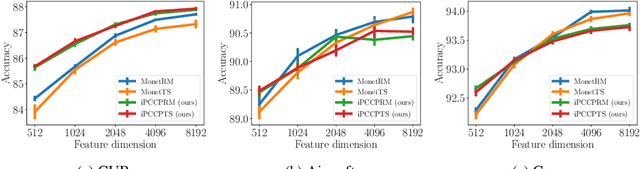
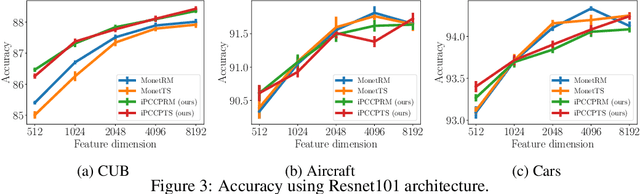
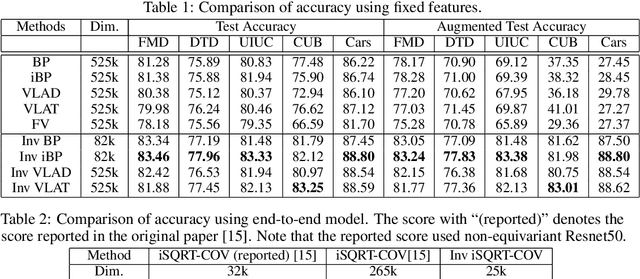
Covariance pooling is a feature pooling method with good classification accuracy. Because covariance features consist of second-order statistics, the scale of the feature elements are varied. Therefore, normalizing covariance features using a matrix square root affects the performance improvement. When pooling methods are applied to local features extracted from CNN models, the accuracy increases when the pooling function is back-propagatable and the feature-extraction model is learned in an end-to-end manner. Recently, the iterative polynomial approximation method for the matrix square root of a covariance feature was proposed, and resulted in a faster and more stable training than the methods based on singular-value decomposition. In this paper, we propose an extension of compact bilinear pooling, which is a compact approximation of the standard covariance feature, to the polynomials of the covariance feature. Subsequently, we apply the proposed approximation to the polynomial corresponding to the matrix square root to obtain a compact approximation for the square root of the covariance feature. Our method approximates a higher-dimensional polynomial of a covariance by the weighted sum of the approximate features corresponding to a pair of local features based on the similarity of the local features. We apply our method for standard fine-grained image recognition datasets and demonstrate that the proposed method shows comparable accuracy with fewer dimensions than the original feature.
Improved Optical Flow for Gesture-based Human-robot Interaction
May 21, 2019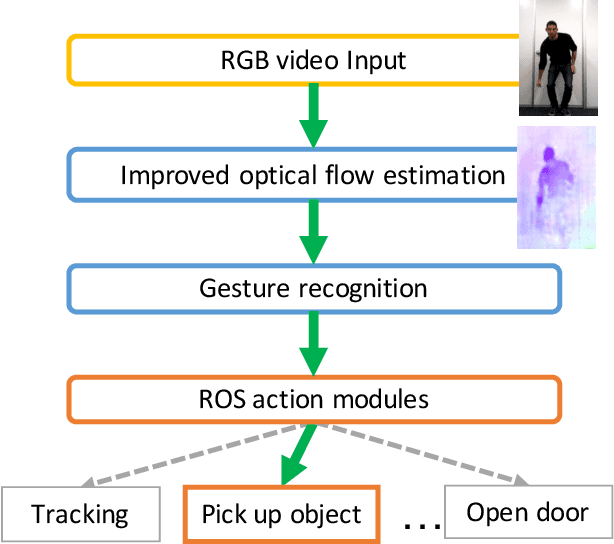
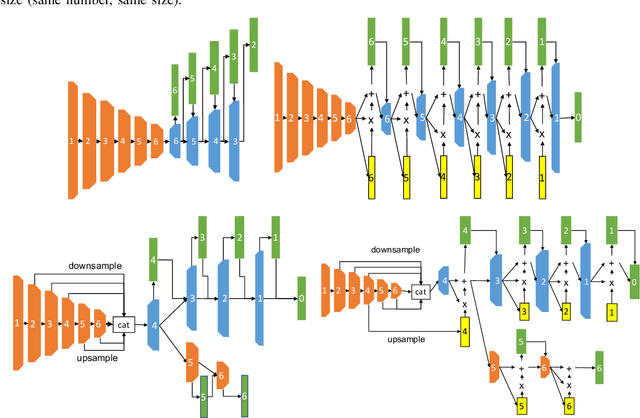

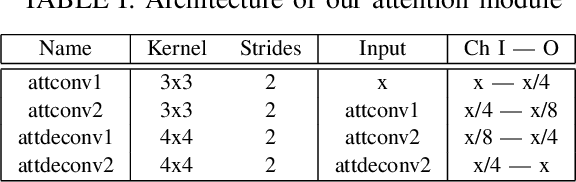
Gesture interaction is a natural way of communicating with a robot as an alternative to speech. Gesture recognition methods leverage optical flow in order to understand human motion. However, while accurate optical flow estimation (i.e., traditional) methods are costly in terms of runtime, fast estimation (i.e., deep learning) methods' accuracy can be improved. In this paper, we present a pipeline for gesture-based human-robot interaction that uses a novel optical flow estimation method in order to achieve an improved speed-accuracy trade-off. Our optical flow estimation method introduces four improvements to previous deep learning-based methods: strong feature extractors, attention to contours, midway features, and a combination of these three. This results in a better understanding of motion, and a finer representation of silhouettes. In order to evaluate our pipeline, we generated our own dataset, MIBURI, which contains gestures to command a house service robot. In our experiments, we show how our method improves not only optical flow estimation, but also gesture recognition, offering a speed-accuracy trade-off more realistic for practical robot applications.
Interactive Video Retrieval with Dialog
May 07, 2019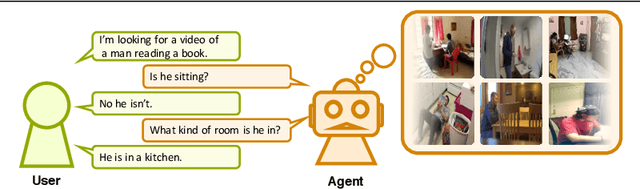
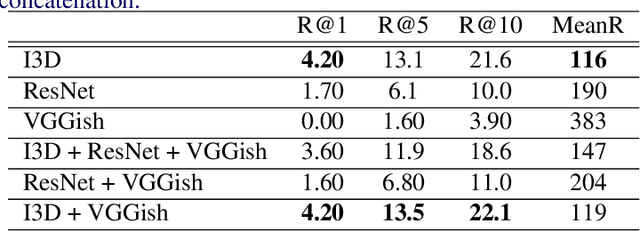
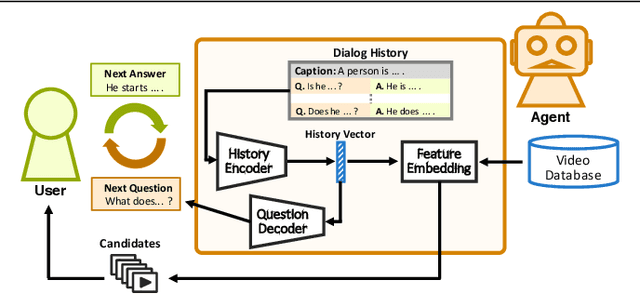
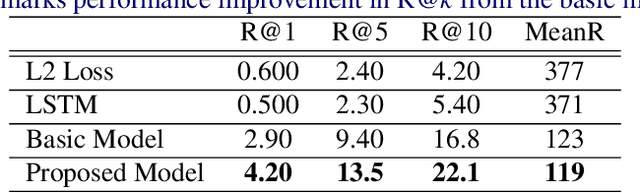
Now that everyone can easily record videos, the quantity of which is continuously increasing, research on methods for improved video retrieval is important in the contemporary world. In cases where target videos are to be identified within a large collection gathered by individuals, the appropriate information must be obtained to retrieve the correct video within a large number of similar items in the target database. The purpose of this research is to retrieve target videos in such cases by introducing an interaction, or a dialog, between the system and the user. We propose a system to retrieve videos by asking questions about the content of the videos and leveraging the user's responses to the questions. Additionally, we confirmed the usefulness of the proposed system through experiments using the dataset called AVSD which includes videos and dialogs about the videos.
Label-Noise Robust Multi-Domain Image-to-Image Translation
May 06, 2019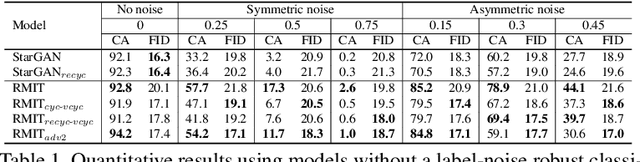
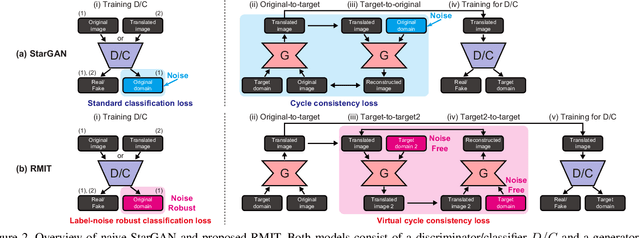


Multi-domain image-to-image translation is a problem where the goal is to learn mappings among multiple domains. This problem is challenging in terms of scalability because it requires the learning of numerous mappings, the number of which increases proportional to the number of domains. However, generative adversarial networks (GANs) have emerged recently as a powerful framework for this problem. In particular, label-conditional extensions (e.g., StarGAN) have become a promising solution owing to their ability to address this problem using only a single unified model. Nonetheless, a limitation is that they rely on the availability of large-scale clean-labeled data, which are often laborious or impractical to collect in a real-world scenario. To overcome this limitation, we propose a novel model called the label-noise robust image-to-image translation model (RMIT) that can learn a clean label conditional generator even when noisy labeled data are only available. In particular, we propose a novel loss called the virtual cycle consistency loss that is able to regularize cyclic reconstruction independently of noisy labeled data, as well as we introduce advanced techniques to boost the performance in practice. Our experimental results demonstrate that RMIT is useful for obtaining label-noise robustness in various settings including synthetic and real-world noise.
Image Generation from Small Datasets via Batch Statistics Adaptation
Apr 22, 2019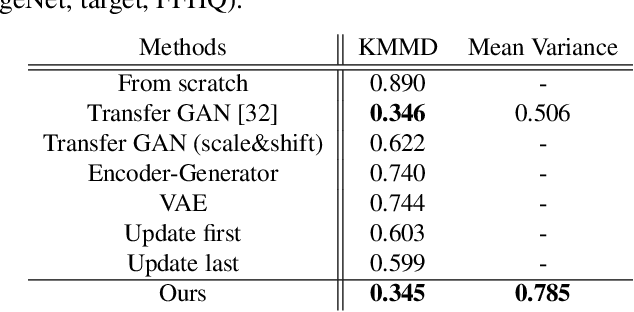

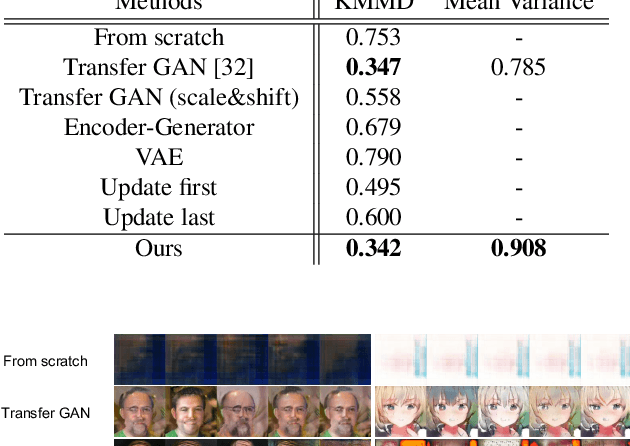
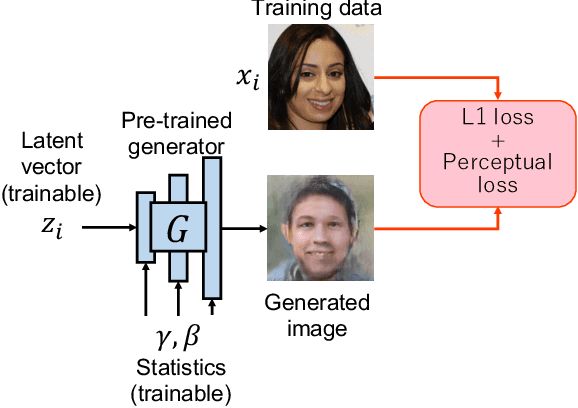
Thanks to the recent development of deep generative models, it is becoming possible to generate high-quality images with both fidelity and diversity. However, the training of such generative models requires a large dataset. To reduce the amount of data required, we propose a new method for transferring prior knowledge of the pre-trained generator, which is trained with a large dataset, to a small dataset in a different domain. Using such prior knowledge, the model can generate images leveraging some common sense that cannot be acquired from a small dataset. In this work, we propose a novel method focusing on the parameters for batch statistics, scale and shift, of the hidden layers in the generator. By training only these parameters in a supervised manner, we achieved stable training of the generator, and our method can generate higher quality images compared to previous methods without collapsing even when the dataset is small (~100). Our results show that the diversity of the filters acquired in the pre-trained generator is important for the performance on the target domain. By our method, it becomes possible to add a new class or domain to a pre-trained generator without disturbing the performance on the original domain.
Long-Term Video Generation of Multiple Futures Using Human Poses
Apr 17, 2019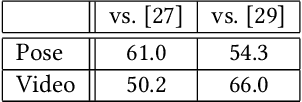
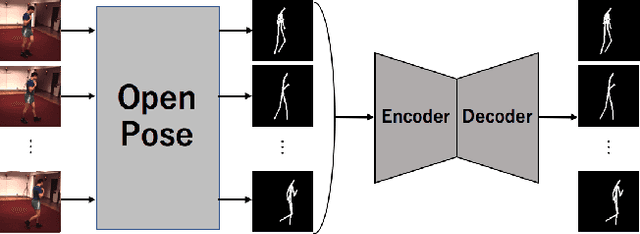
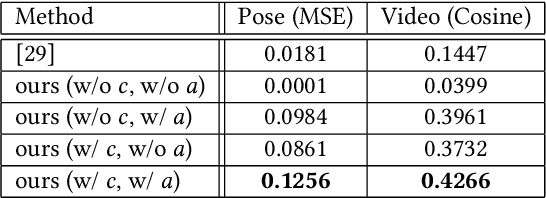
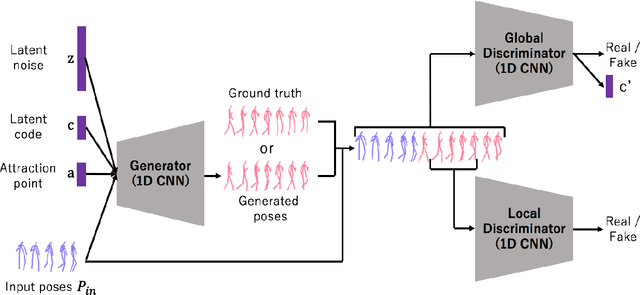
Predicting the near-future from an input video is a useful task for applications such as autonomous driving and robotics. While most previous works predict a single future, multiple futures with different behaviors can possibly occur. Moreover, if the predicted future is too short, it may not be fully usable by a human or other system. In this paper, we propose a novel method for future video prediction capable of generating multiple long-term futures. This makes the predictions more suitable for real applications. First, from an input human video, we generate sequences of future human poses as the image coordinates of their body-joints by adversarial learning. We generate multiple futures by inputting to the generator combinations of a latent code (to reflect various behaviors) and an attraction point (to reflect various trajectories). In addition, we generate long-term future human poses using a novel approach based on unidimensional convolutional neural networks. Last, we generate an output video based on the generated poses for visualization. We evaluate the generated future poses and videos using three criteria (i.e., realism, diversity and accuracy), and show that our proposed method outperforms other state-of-the-art works.