 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuda: Private User Dataset Agent for User-Sovereign and Privacy-Preserving Personalized AI
Feb 09, 2026Personal data centralization among dominant platform providers including search engines, social networking services, and e-commerce has created siloed ecosystems that restrict user sovereignty, thereby impeding data use across services. Meanwhile, the rapid proliferation of Large Language Model (LLM)-based agents has intensified demand for highly personalized services that require the dynamic provision of diverse personal data. This presents a significant challenge: balancing the utilization of such data with privacy protection. To address this challenge, we propose Puda (Private User Dataset Agent), a user-sovereign architecture that aggregates data across services and enables client-side management. Puda allows users to control data sharing at three privacy levels: (i) Detailed Browsing History, (ii) Extracted Keywords, and (iii) Predefined Category Subsets. We implemented Puda as a browser-based system that serves as a common platform across diverse services and evaluated it through a personalized travel planning task. Our results show that providing Predefined Category Subsets achieves 97.2% of the personalization performance (evaluated via an LLM-as-a-Judge framework across three criteria) obtained when sharing Detailed Browsing History. These findings demonstrate that Puda enables effective multi-granularity management, offering practical choices to mitigate the privacy-personalization trade-off. Overall, Puda provides an AI-native foundation for user sovereignty, empowering users to safely leverage the full potential of personalized AI.
Distributed Asymmetric Allocation: A Topic Model for Large Imbalanced Corpora in Social Sciences
Dec 19, 2025Social scientists employ latent Dirichlet allocation (LDA) to find highly specific topics in large corpora, but they often struggle in this task because (1) LDA, in general, takes a significant amount of time to fit on large corpora; (2) unsupervised LDA fragments topics into sub-topics in short documents; (3) semi-supervised LDA fails to identify specific topics defined using seed words. To solve these problems, I have developed a new topic model called distributed asymmetric allocation (DAA) that integrates multiple algorithms for efficiently identifying sentences about important topics in large corpora. I evaluate the ability of DAA to identify politically important topics by fitting it to the transcripts of speeches at the United Nations General Assembly between 1991 and 2017. The results show that DAA can classify sentences significantly more accurately and quickly than LDA thanks to the new algorithms. More generally, the results demonstrate that it is important for social scientists to optimize Dirichlet priors of LDA to perform content analysis accurately.
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
Aug 19, 2024



Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.
Multichannel Semantic Segmentation with Unsupervised Domain Adaptation
Dec 11, 2018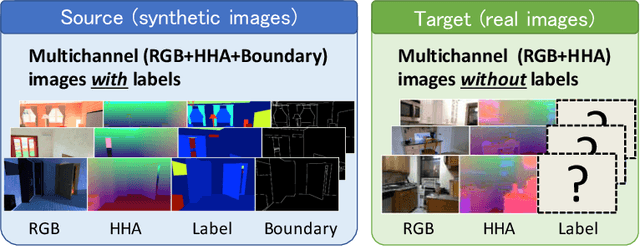
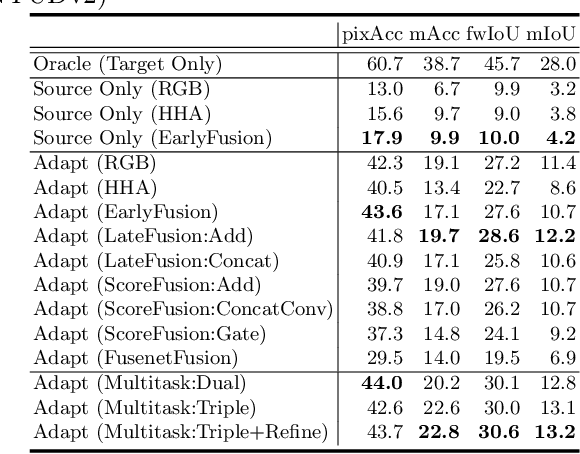
Most contemporary robots have depth sensors, and research on semantic segmentation with RGBD images has shown that depth images boost the accuracy of segmentation. Since it is time-consuming to annotate images with semantic labels per pixel, it would be ideal if we could avoid this laborious work by utilizing an existing dataset or a synthetic dataset which we can generate on our own. Robot motions are often tested in a synthetic environment, where multichannel (eg, RGB + depth + instance boundary) images plus their pixel-level semantic labels are available. However, models trained simply on synthetic images tend to demonstrate poor performance on real images. In order to address this, we propose two approaches that can efficiently exploit multichannel inputs combined with an unsupervised domain adaptation (UDA) algorithm. One is a fusion-based approach that uses depth images as inputs. The other is a multitask learning approach that uses depth images as outputs. We demonstrated that the segmentation results were improved by using a multitask learning approach with a post-process and created a benchmark for this task.
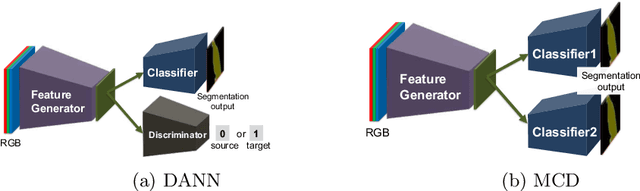
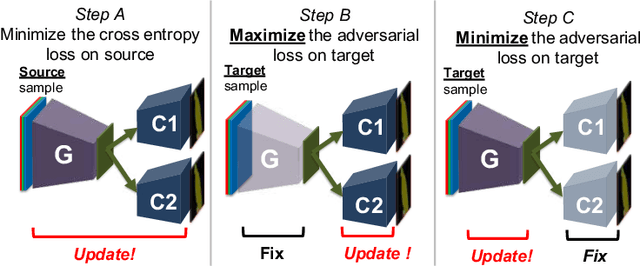
Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
Apr 03, 2018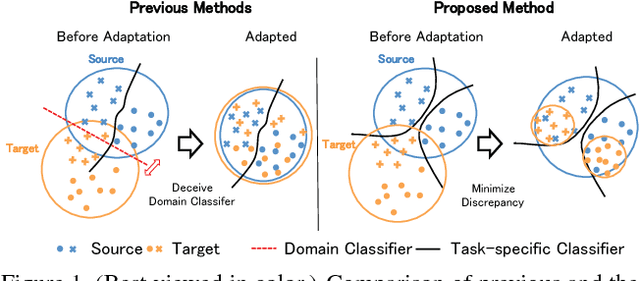
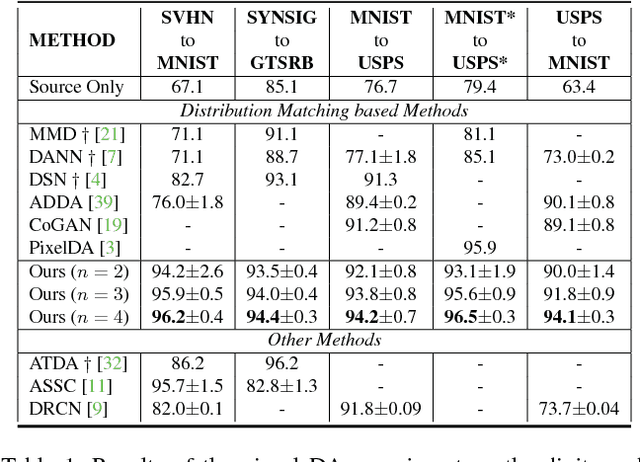
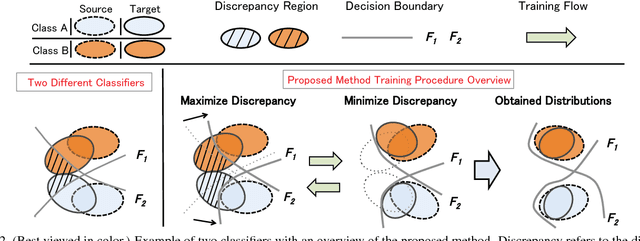

In this work, we present a method for unsupervised domain adaptation. Many adversarial learning methods train domain classifier networks to distinguish the features as either a source or target and train a feature generator network to mimic the discriminator. Two problems exist with these methods. First, the domain classifier only tries to distinguish the features as a source or target and thus does not consider task-specific decision boundaries between classes. Therefore, a trained generator can generate ambiguous features near class boundaries. Second, these methods aim to completely match the feature distributions between different domains, which is difficult because of each domain's characteristics. To solve these problems, we introduce a new approach that attempts to align distributions of source and target by utilizing the task-specific decision boundaries. We propose to maximize the discrepancy between two classifiers' outputs to detect target samples that are far from the support of the source. A feature generator learns to generate target features near the support to minimize the discrepancy. Our method outperforms other methods on several datasets of image classification and semantic segmentation. The codes are available at \url{https://github.com/mil-tokyo/MCD_DA}