 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization Using a Mixture of Multiple Latent Domains
Nov 18, 2019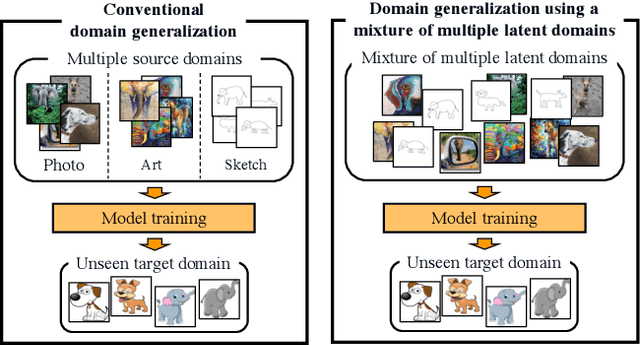
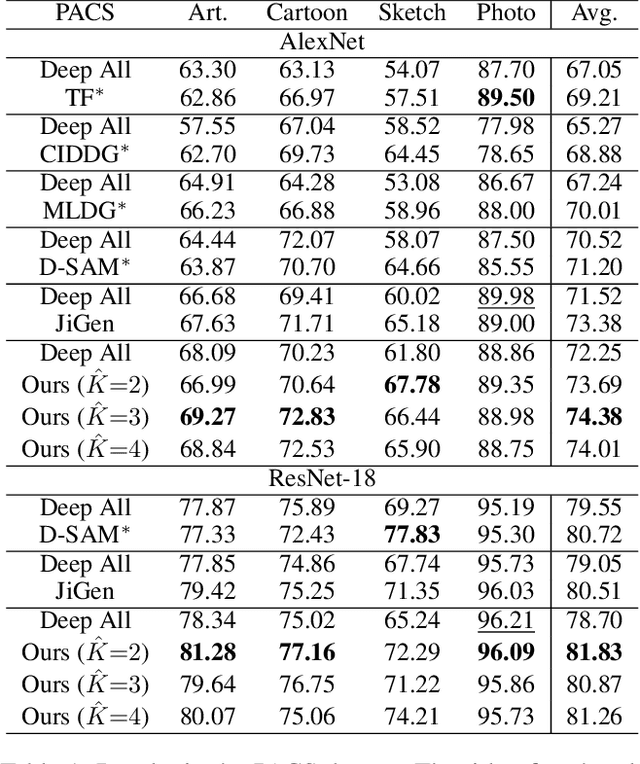
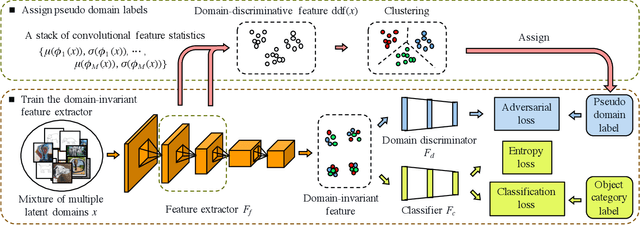
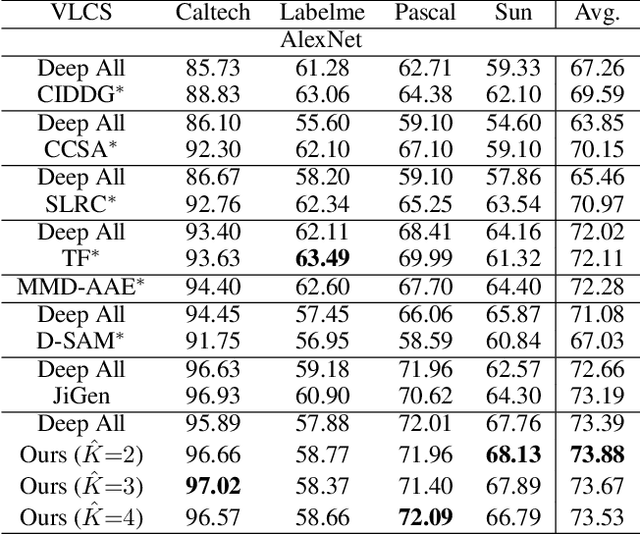
When domains, which represent underlying data distributions, vary during training and testing processes, deep neural networks suffer a drop in their performance. Domain generalization allows improvements in the generalization performance for unseen target domains by using multiple source domains. Conventional methods assume that the domain to which each sample belongs is known in training. However, many datasets, such as those collected via web crawling, contain a mixture of multiple latent domains, in which the domain of each sample is unknown. This paper introduces domain generalization using a mixture of multiple latent domains as a novel and more realistic scenario, where we try to train a domain-generalized model without using domain labels. To address this scenario, we propose a method that iteratively divides samples into latent domains via clustering, and which trains the domain-invariant feature extractor shared among the divided latent domains via adversarial learning. We assume that the latent domain of images is reflected in their style, and thus, utilize style features for clustering. By using these features, our proposed method successfully discovers latent domains and achieves domain generalization even if the domain labels are not given. Experiments show that our proposed method can train a domain-generalized model without using domain labels. Moreover, it outperforms conventional domain generalization methods, including those that utilize domain labels.
TWINs: Two Weighted Inconsistency-reduced Networks for Partial Domain Adaptation
Dec 18, 2018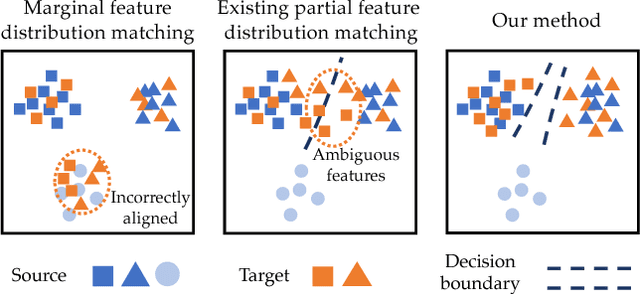
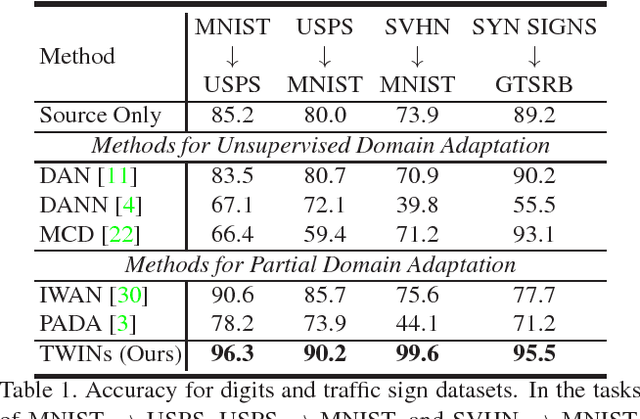
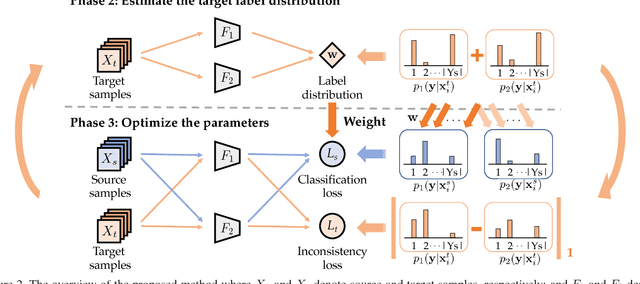
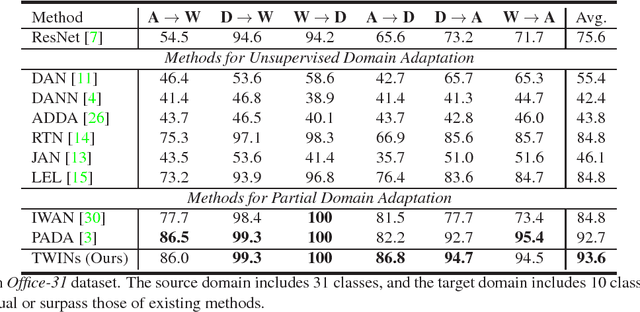
The task of unsupervised domain adaptation is proposed to transfer the knowledge of a label-rich domain (source domain) to a label-scarce domain (target domain). Matching feature distributions between different domains is a widely applied method for the aforementioned task. However, the method does not perform well when classes in the two domains are not identical. Specifically, when the classes of the target correspond to a subset of those of the source, target samples can be incorrectly aligned with the classes that exist only in the source. This problem setting is termed as partial domain adaptation (PDA). In this study, we propose a novel method called Two Weighted Inconsistency-reduced Networks (TWINs) for PDA. We utilize two classification networks to estimate the ratio of the target samples in each class with which a classification loss is weighted to adapt the classes present in the target domain. Furthermore, to extract discriminative features for the target, we propose to minimize the divergence between domains measured by the classifiers' inconsistency on target samples. We empirically demonstrate that reducing the inconsistency between two networks is effective for PDA and that our method outperforms other existing methods with a large margin in several datasets.