 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Competing Bandits in Non-Stationary Matching Markets
May 31, 2022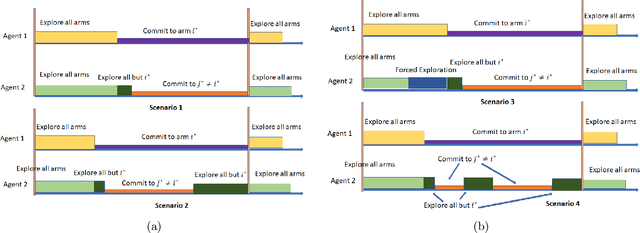
Understanding complex dynamics of two-sided online matching markets, where the demand-side agents compete to match with the supply-side (arms), has recently received substantial interest. To that end, in this paper, we introduce the framework of decentralized two-sided matching market under non stationary (dynamic) environments. We adhere to the serial dictatorship setting, where the demand-side agents have unknown and different preferences over the supply-side (arms), but the arms have fixed and known preference over the agents. We propose and analyze a decentralized and asynchronous learning algorithm, namely Decentralized Non-stationary Competing Bandits (\texttt{DNCB}), where the agents play (restrictive) successive elimination type learning algorithms to learn their preference over the arms. The complexity in understanding such a system stems from the fact that the competing bandits choose their actions in an asynchronous fashion, and the lower ranked agents only get to learn from a set of arms, not \emph{dominated} by the higher ranked agents, which leads to \emph{forced exploration}. With carefully defined complexity parameters, we characterize this \emph{forced exploration} and obtain sub-linear (logarithmic) regret of \texttt{DNCB}. Furthermore, we validate our theoretical findings via experiments.
Instance-Dependent Regret Analysis of Kernelized Bandits
Mar 12, 2022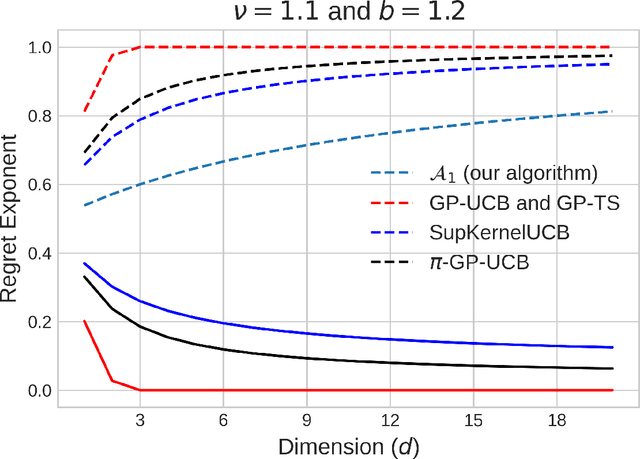
We study the kernelized bandit problem, that involves designing an adaptive strategy for querying a noisy zeroth-order-oracle to efficiently learn about the optimizer of an unknown function $f$ with a norm bounded by $M<\infty$ in a Reproducing Kernel Hilbert Space~(RKHS) associated with a positive definite kernel $K$. Prior results, working in a \emph{minimax framework}, have characterized the worst-case~(over all functions in the problem class) limits on regret achievable by \emph{any} algorithm, and have constructed algorithms with matching~(modulo polylogarithmic factors) worst-case performance for the \matern family of kernels. These results suffer from two drawbacks. First, the minimax lower bound gives no information about the limits of regret achievable by the commonly used algorithms on specific problem instances. Second, due to their worst-case nature, the existing upper bound analysis fails to adapt to easier problem instances within the function class. Our work takes steps to address both these issues. First, we derive \emph{instance-dependent} regret lower bounds for algorithms with uniformly~(over the function class) vanishing normalized cumulative regret. Our result, valid for all the practically relevant kernelized bandits algorithms, such as, GP-UCB, GP-TS and SupKernelUCB, identifies a fundamental complexity measure associated with every problem instance. We then address the second issue, by proposing a new minimax near-optimal algorithm which also adapts to easier problem instances.
Open Problem: Tight Online Confidence Intervals for RKHS Elements
Oct 28, 2021Confidence intervals are a crucial building block in the analysis of various online learning problems. The analysis of kernel based bandit and reinforcement learning problems utilize confidence intervals applicable to the elements of a reproducing kernel Hilbert space (RKHS). However, the existing confidence bounds do not appear to be tight, resulting in suboptimal regret bounds. In fact, the existing regret bounds for several kernelized bandit algorithms (e.g., GP-UCB, GP-TS, and their variants) may fail to even be sublinear. It is unclear whether the suboptimal regret bound is a fundamental shortcoming of these algorithms or an artifact of the proof, and the main challenge seems to stem from the online (sequential) nature of the observation points. We formalize the question of online confidence intervals in the RKHS setting and overview the existing results.
Trojan Signatures in DNN Weights
Sep 07, 2021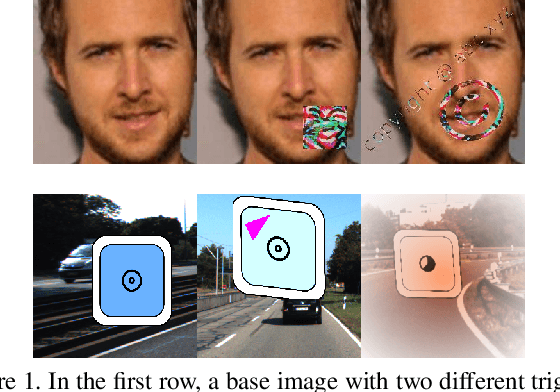
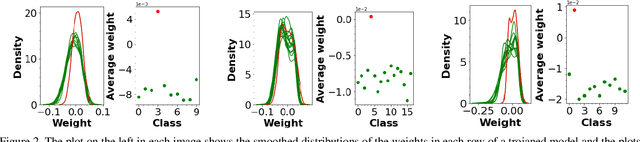
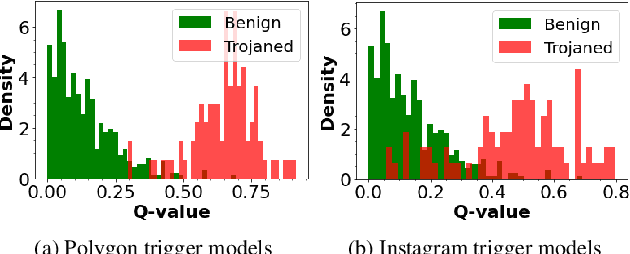
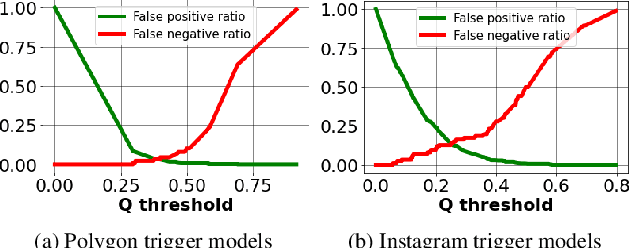
Deep neural networks have been shown to be vulnerable to backdoor, or trojan, attacks where an adversary has embedded a trigger in the network at training time such that the model correctly classifies all standard inputs, but generates a targeted, incorrect classification on any input which contains the trigger. In this paper, we present the first ultra light-weight and highly effective trojan detection method that does not require access to the training/test data, does not involve any expensive computations, and makes no assumptions on the nature of the trojan trigger. Our approach focuses on analysis of the weights of the final, linear layer of the network. We empirically demonstrate several characteristics of these weights that occur frequently in trojaned networks, but not in benign networks. In particular, we show that the distribution of the weights associated with the trojan target class is clearly distinguishable from the weights associated with other classes. Using this, we demonstrate the effectiveness of our proposed detection method against state-of-the-art attacks across a variety of architectures, datasets, and trigger types.
Decentralized Bayesian Learning with Metropolis-Adjusted Hamiltonian Monte Carlo
Jul 15, 2021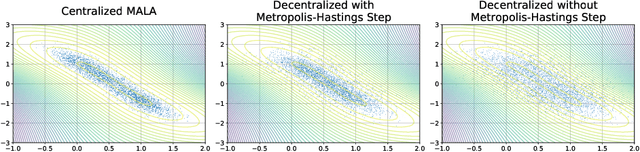
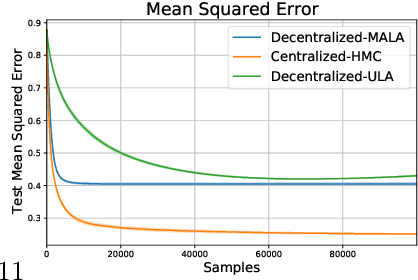
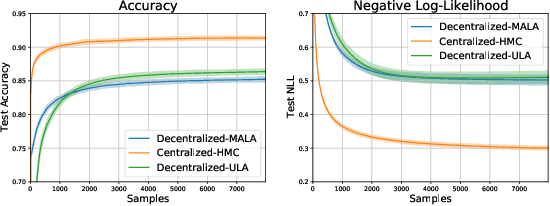
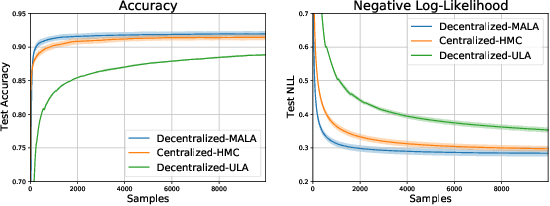
Federated learning performed by a decentralized networks of agents is becoming increasingly important with the prevalence of embedded software on autonomous devices. Bayesian approaches to learning benefit from offering more information as to the uncertainty of a random quantity, and Langevin and Hamiltonian methods are effective at realizing sampling from an uncertain distribution with large parameter dimensions. Such methods have only recently appeared in the decentralized setting, and either exclusively use stochastic gradient Langevin and Hamiltonian Monte Carlo approaches that require a diminishing stepsize to asymptotically sample from the posterior and are known in practice to characterize uncertainty less faithfully than constant step-size methods with a Metropolis adjustment, or assume strong convexity properties of the potential function. We present the first approach to incorporating constant stepsize Metropolis-adjusted HMC in the decentralized sampling framework, show theoretical guarantees for consensus and probability distance to the posterior stationary distribution, and demonstrate their effectiveness numerically on standard real world problems, including decentralized learning of neural networks which is known to be highly non-convex.
A Field Guide to Federated Optimization
Jul 14, 2021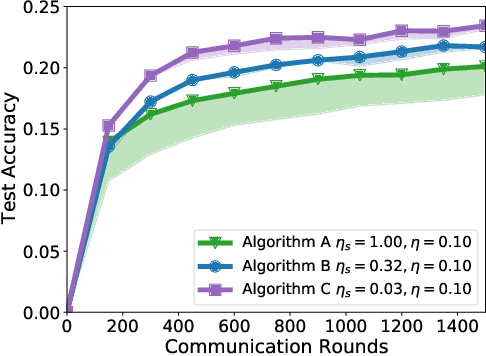


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Active and Dynamic Beam Tracking UnderStochastic Mobility
Jun 21, 2021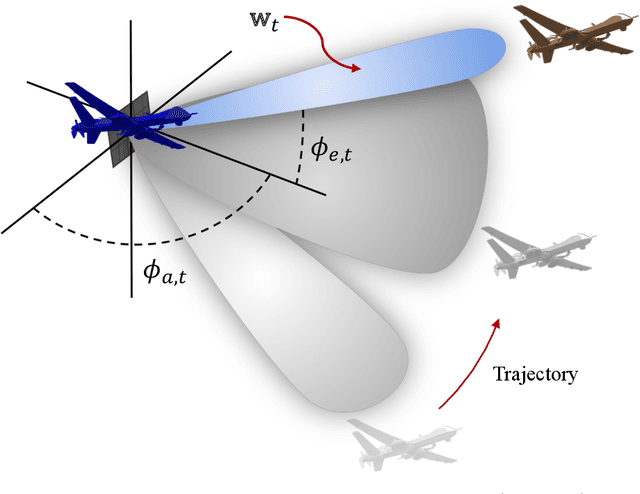
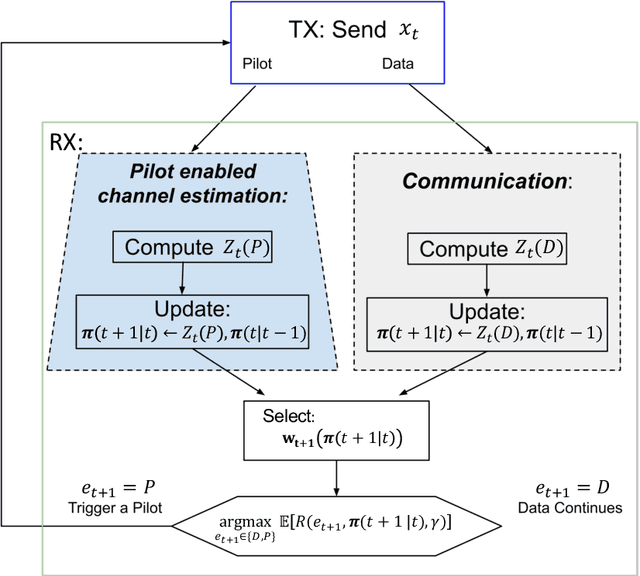
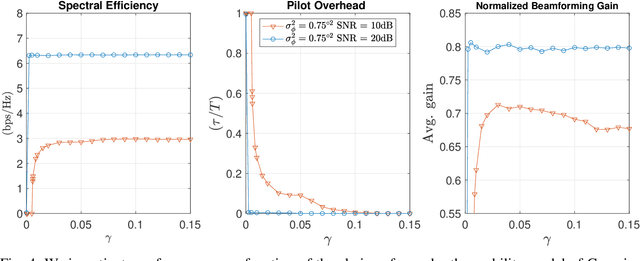
We consider the problem of active and sequential beam tracking at mmWave frequencies and above. We focus on the dynamic scenario of a UAV to UAV communications where we formulate the problem to be equivalent to tracking an optimal beamforming vector along the line-of-sight path. In this setting, the resulting beam ideally points in the direction of the angle of arrival with sufficiently high resolution. Existing solutions account for predictable movements or small random movements using filtering strategies or by accounting for predictable mobility but must resort to re-estimation protocols when tracking fails due to unpredictable movements. We propose an algorithm for active learning of the AoA through evolving a Bayesian posterior probability belief which is utilized for a sequential selection of beamforming vectors. We propose an adaptive pilot allocation strategy based on a trade-off of mutual information versus spectral efficiency. Numerically, we analyze the performance of our proposed algorithm and demonstrate significant improvements over existing strategies.
Adaptive Sampling for Minimax Fair Classification
Mar 01, 2021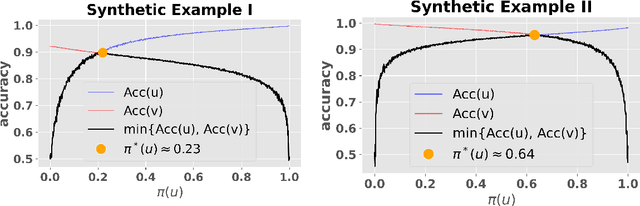
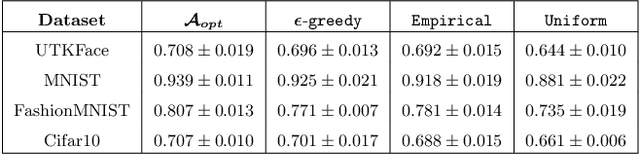
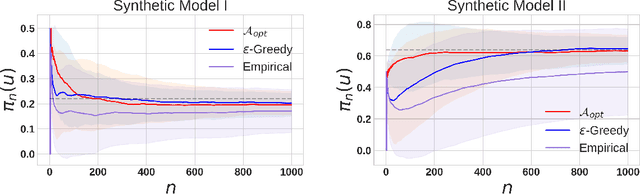
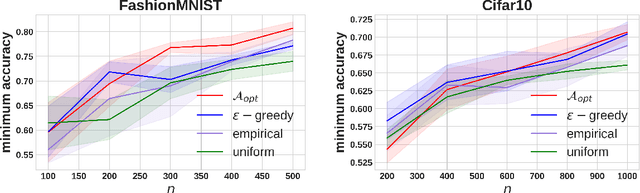
Machine learning models trained on imbalanced datasets can often end up adversely affecting inputs belonging to the underrepresented groups. To address this issue, we consider the problem of adaptively constructing training sets which allow us to learn classifiers that are fair in a minimax sense. We first propose an adaptive sampling algorithm based on the principle of optimism, and derive theoretical bounds on its performance. We then suitably adapt the techniques developed for the analysis of our proposed algorithm to derive bounds on the performance of a related $\epsilon$-greedy strategy recently proposed in the literature. Next, by deriving algorithm independent lower-bounds for a specific class of problems, we show that the performance achieved by our adaptive scheme cannot be improved in general. We then validate the benefits of adaptively constructing training sets via experiments on synthetic tasks with logistic regression classifiers, as well as on several real-world tasks using convolutional neural networks.
Adaptive Sampling for Estimating Distributions: A Bayesian Upper Confidence Bound Approach
Dec 08, 2020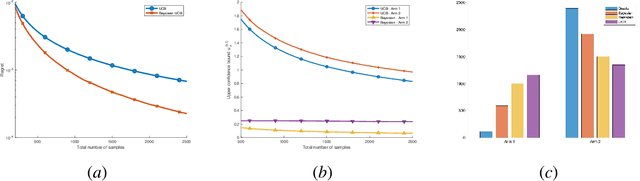
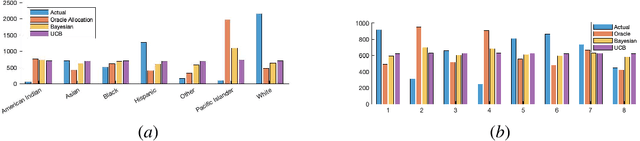
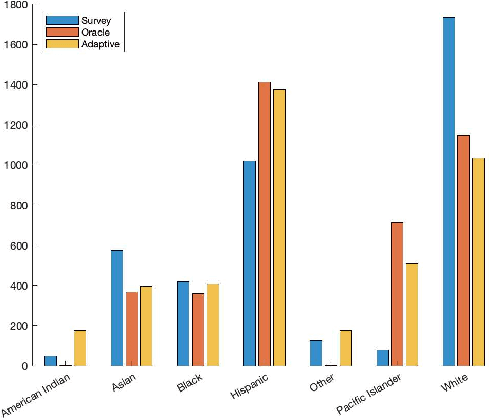
The problem of adaptive sampling for estimating probability mass functions (pmf) uniformly well is considered. Performance of the sampling strategy is measured in terms of the worst-case mean squared error. A Bayesian variant of the existing upper confidence bound (UCB) based approaches is proposed. It is shown analytically that the performance of this Bayesian variant is no worse than the existing approaches. The posterior distribution on the pmfs in the Bayesian setting allows for a tighter computation of upper confidence bounds which leads to significant performance gains in practice. Using this approach, adaptive sampling protocols are proposed for estimating SARS-CoV-2 seroprevalence in various groups such as location and ethnicity. The effectiveness of this strategy is discussed using data obtained from a seroprevalence survey in Los Angeles county.
CLEANN: Accelerated Trojan Shield for Embedded Neural Networks
Sep 04, 2020
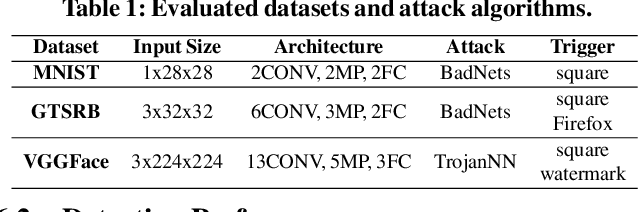
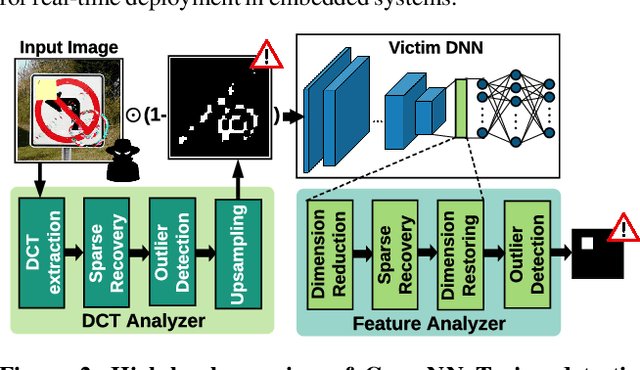

We propose CLEANN, the first end-to-end framework that enables online mitigation of Trojans for embedded Deep Neural Network (DNN) applications. A Trojan attack works by injecting a backdoor in the DNN while training; during inference, the Trojan can be activated by the specific backdoor trigger. What differentiates CLEANN from the prior work is its lightweight methodology which recovers the ground-truth class of Trojan samples without the need for labeled data, model retraining, or prior assumptions on the trigger or the attack. We leverage dictionary learning and sparse approximation to characterize the statistical behavior of benign data and identify Trojan triggers. CLEANN is devised based on algorithm/hardware co-design and is equipped with specialized hardware to enable efficient real-time execution on resource-constrained embedded platforms. Proof of concept evaluations on CLEANN for the state-of-the-art Neural Trojan attacks on visual benchmarks demonstrate its competitive advantage in terms of attack resiliency and execution overhead.