 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy Does Not Guarantee Human-Likeness in Monocular Depth Estimators
Dec 09, 2025Monocular depth estimation is a fundamental capability for real-world applications such as autonomous driving and robotics. Although deep neural networks (DNNs) have achieved superhuman accuracy on physical-based benchmarks, a key challenge remains: aligning model representations with human perception, a promising strategy for enhancing model robustness and interpretability. Research in object recognition has revealed a complex trade-off between model accuracy and human-like behavior, raising a question whether a similar divergence exist in depth estimation, particularly for natural outdoor scenes where benchmarks rely on sensor-based ground truth rather than human perceptual estimates. In this study, we systematically investigated the relationship between model accuracy and human similarity across 69 monocular depth estimators using the KITTI dataset. To dissect the structure of error patterns on a factor-by-factor basis, we applied affine fitting to decompose prediction errors into interpretable components. Intriguingly, our results reveal while humans and DNNs share certain estimation biases (positive error correlations), we observed distinct trade-off relationships between model accuracy and human similarity. This finding indicates that improving accuracy does not necessarily lead to more human-like behavior, underscoring the necessity of developing multifaceted, human-centric evaluations beyond traditional accuracy.
REF$^2$-NeRF: Reflection and Refraction aware Neural Radiance Field
Nov 30, 2023



Recently, significant progress has been made in the study of methods for 3D reconstruction from multiple images using implicit neural representations, exemplified by the neural radiance field (NeRF) method. Such methods, which are based on volume rendering, can model various light phenomena, and various extended methods have been proposed to accommodate different scenes and situations. However, when handling scenes with multiple glass objects, e.g., objects in a glass showcase, modeling the target scene accurately has been challenging due to the presence of multiple reflection and refraction effects. Thus, this paper proposes a NeRF-based modeling method for scenes containing a glass case. In the proposed method, refraction and reflection are modeled using elements that are dependent and independent of the viewer's perspective. This approach allows us to estimate the surfaces where refraction occurs, i.e., glass surfaces, and enables the separation and modeling of both direct and reflected light components. Compared to existing methods, the proposed method enables more accurate modeling of both glass refraction and the overall scene.
Occlusion Handling using Semantic Segmentation and Visibility-Based Rendering for Mixed Reality
Jul 30, 2017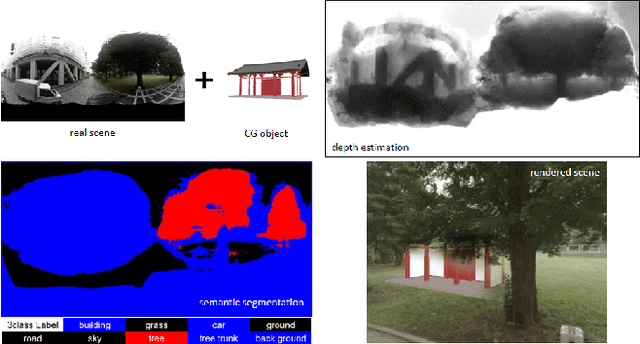
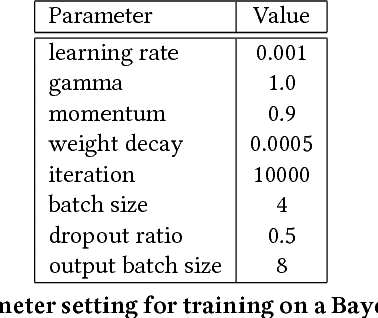

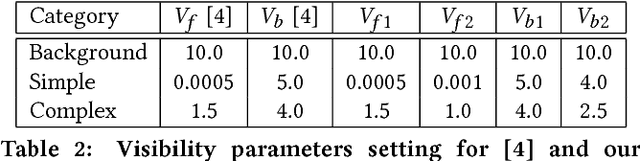
Real-time occlusion handling is a major problem in outdoor mixed reality system because it requires great computational cost mainly due to the complexity of the scene. Using only segmentation, it is difficult to accurately render a virtual object occluded by complex objects such as trees, bushes etc. In this paper, we propose a novel occlusion handling method for real-time, outdoor, and omni-directional mixed reality system using only the information from a monocular image sequence. We first present a semantic segmentation scheme for predicting the amount of visibility for different type of objects in the scene. We also simultaneously calculate a foreground probability map using depth estimation derived from optical flow. Finally, we combine the segmentation result and the probability map to render the computer generated object and the real scene using a visibility-based rendering method. Our results show great improvement in handling occlusions compared to existing blending based methods.